
Individualisierung von Konferenz-Programmen durch LLMs
Vor einem Jahr wurde ChatGPT vorgestellt, seitdem sind Sprachmodelle das mit Abstand am meisten diskutierte Thema der IT-Geschäftswelt. Große Sprachmodelle wie ChatGPT haben zahllose Anwendungsfälle, eines davon ist die Verwendung um Texte personalisiert, also an den Präferenzen der Nutzer orientiert, wiederzugeben. Ein Beispiel hierfür ist die Erstellung von individuellen Programmplänen. Bei Konferenzen ist es nicht ungewöhnlich, dass mehrere Vorträge zur gleichen Zeit stattfinden, wodurch ich mich entscheiden muss, welche Talks ich mir anhören möchte. Häufig kann das Durchsehen aller Vorträge und das Erstellen eines Plans zeitaufwändig sein. Daher wäre es doch praktisch, wenn ich ein Tool zur Verfügung habe, dass mir basierend auf meinen Interessen einen individuellen Plan zusammenstellt. Mit großen Sprachmodellen, wie GPT-3.5, steht uns diese Möglichkeit zur Verfügung. Wir haben daher eine Anwendung implementiert, die basierend auf einem User-Input und einer Vektordatenbank individuelle Programmpläne für die IT-Tage 2023 in Frankfurt am Main erstellt.
In diesem Blogartikel geben wir einen kurzen Überblick über die Entwicklung unserer Anwendung. Die Implementierung wurde in Python mit LangChain, Azure OpenAI Service und streamlit umgesetzt.
Über den Button kann das Ergebnis gerne getestet werden. Es besteht die Möglichkeit sich anhand der eigenen Interesse einen individuellen Programmplan generieren zu lassen.
Komponenten innerhalb der Gesamtarchitektur
Für die Generierung individueller Programmpläne mithilfe von GPT-3.5 sind verschiedene Komponenten erforderlich, die in einer Gesamtarchitektur miteinander interagieren.
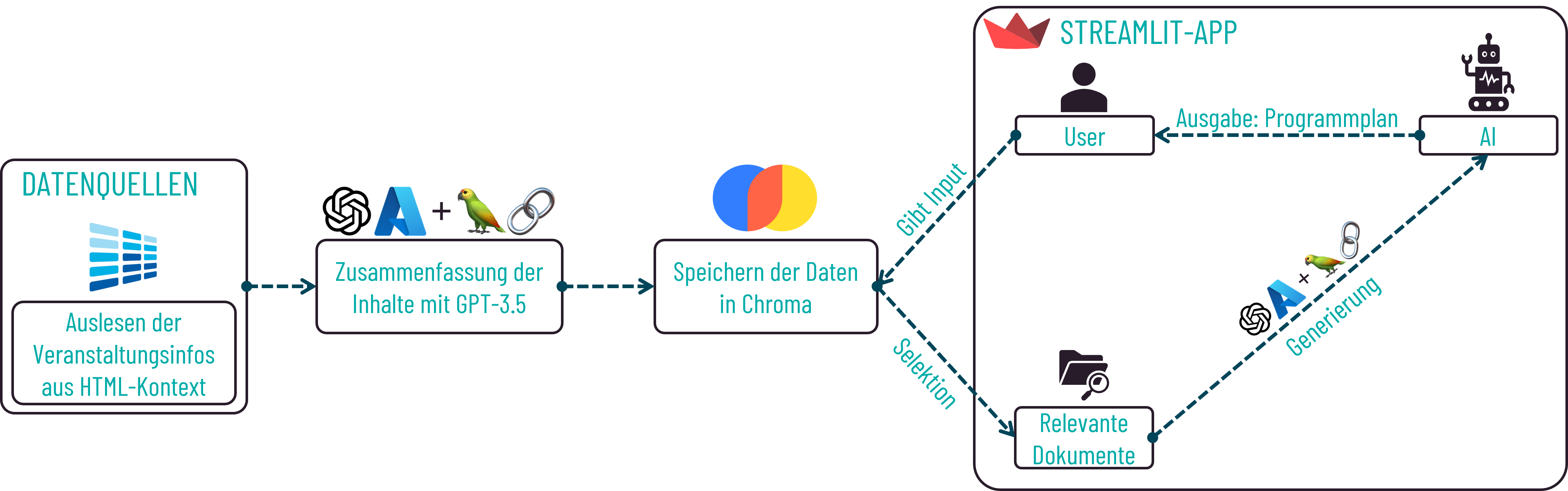
Architektur zur Erstellung individueller Programmpläne
Um Programmpläne zu erstellen, ist es zunächst erforderlich, spezifische Informationen zu den einzelnen Veranstaltungen der IT-Tage 2023 zu sammeln. Ohne die Veranstaltungsinformationen ist eine Generierung durch GPT-3.5 mit korrekten und tatsächlichen Vorträgen nicht möglich, da bisher keine Daten in Bezug darauf vorhanden sind. Die notwendigen Informationen werden daher extrahiert, zusammengefasst und als Dokumente in Chroma gespeichert. Bei der Generierung werden die Dokumente dann aus der Datenbank abgerufen. Basierend auf den relevanten Daten und den angegebenen Interessen der User wird durch die Anwendung von GPT-3.5 ein personalisierter Programmplan erstellt.
Verwendung von GPT-3.5 mit eigenen Daten
Daten werden mittels Beautiful Soup ausgelesen
Damit wir spezifische Programmplänen für die IT-Tage 2023 generieren können, müssen wir GPT-3.5 die notwendigen Informationen zur Verfügung stellen. Daher ist der erste Schritt der Entwicklung das Auslesen der benötigten Informationen. Das beinhaltet beispielsweise Titel und Beschreibung der Veranstaltung oder aber auch zeitliche Angaben.
Auf der Homepage der IT-Tage können wir das Programm einsehen. Jede der Veranstaltungen ist dabei einem oder mehreren Themengebieten zugeordnet, nach denen auch gefiltert werden kann. Beispielsweise ist der Talk „Wie Generative KI eine Personalisierungs-Revolution auslöst“ von Nico Kreiling für all jene interessant, die Interesse an KI/Machine Learning haben. Das zeigt der Tag oberhalb des Titels an.

Zuordnung einer Veranstaltung zu bestimmten Themengebieten
Um später relevante und passende Veranstaltungen in Bezug auf die Interessen der User finden zu können, ist die Information über zugehörige Themengebiete eine nützliche und wichtige Angabe. Daher wollen wir die Veranstaltungsinformationen möglichst so auslesen, dass diese Information zusätzlich extrahiert werden kann. Das erreichen wir, indem wir alle URLs zu den verfügbaren Themengebieten extrahieren und anschließend für jedes der Themengebiete die entsprechenden Veranstaltungen abrufen.
Mittels der Python-Bibliothek Beautiful Soup lesen wir zunächst alle auf der Seite vorhandenen Links aus, deren URL „programm“ beinhaltet. Zurückgegeben werden dadurch alle Links, die auf die verschiedenen Themengebieten verweisen. Durch die Liste an ausgewählten URLs ist es nun möglich, für jede Veranstaltung sämtliche benötigten Informationen zu extrahieren. Neben den zugehörigen Themengebieten werden auch zeitliche Informationen und Ortsangaben, Titel der Veranstaltung, zugehörige URL sowie die Namen der Sprecher:innen und die angegebene Beschreibung über den Inhalt der Veranstaltung ausgelesen. Für den Vortrag „Wie Generative KI eine Personalisierungs-Revolution auslöst“ entspricht das den Informationen aus den farbig hinterlegten Umrandungen.
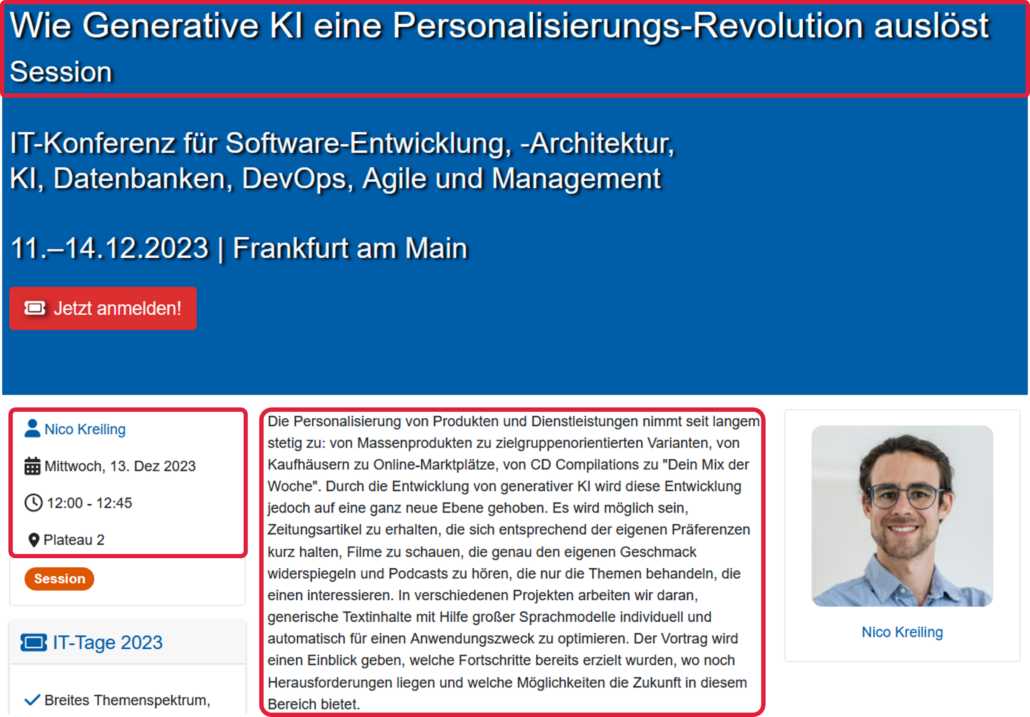
Relevante Informationen zu einer Veranstaltung
Zusätzlich werden die Veranstaltungsart, Titel, zeitliche und räumliche Angaben sowie die URL als Metadaten gespeichert.
Zusammenfassen der Beschreibungen, um nicht relevanten Kontext zu entfernen
Nicht selten unterscheiden sich die einzelnen Veranstaltungsbeschreibungen hinsichtlich ihrer Länge und ihres Inhalts. Besonders umfangreiche Texte oder ausführliche Beschreibungen mit weniger relevanten Informationen zur Veranstaltung können bei der späteren Erstellung der Programmpläne problematisch sein:
- Ist eine Beschreibung sehr lang, dann sollte der Text während der Speicherung in die Vektordatenbank in kleinere Chunks zerlegt werden. Das kann zur Folge haben, dass während der Selektion relevanter Dokumente, für die Erstellung des Programmplans, die Beschreibungen mehrerer Veranstaltungen zusammengeführt werden.
- Findet keine Unterteilung großer Texte in Chunks statt, besteht die Gefahr, dass schnell die maximale Tokenlänge von GPT-3.5 erreicht wird und dadurch keine Antwort generiert werden kann.
- Nicht relevanter Kontext, wie beispielsweise die ausführliche Beschreibung eines Frameworks, kann möglicherweise zu einer Verschlechterung der Antwortqualität führen. Für die Erstellung der Programmpläne ist lediglich wichtig, worum es inhaltlich während einer Veranstaltung geht. Alle weiteren Informationen sind an dieser Stelle für uns uninteressant.
Daher ist es sinnvoll, die einzelnen Beschreibungen auf die Kernaspekte, d.h. den Inhalt der Veranstaltung, zusammenzufassen. Für 224 Veranstaltungsbeschreibungen ist die manuelle Erstellung von Zusammenfassungen jedoch eine zeitlich nicht durchführbare Aufgabe. Aus diesem Grund lassen wir GPT-3.5 die Aufgabe lösen. Für die technische Umsetzung verwenden wir den Azure OpenAI Service in Verbindung mit LangChain. Als System-Prompt wird unter anderem angegeben, dass der Text in maximal drei Sätzen zusammengefasst werden soll. Für den oben genannten Talk erstellt GPT-3.5 folgende Zusammenfassung:
Der Vortrag behandelt die Personalisierung von Produkten und Dienstleistungen mithilfe generativer KI. Es werden Fortschritte und Herausforderungen bei der Optimierung von Textinhalten für individuelle Bedürfnisse aufgezeigt sowie zukünftige Möglichkeiten in diesem Bereich aufgezeigt.
Speichern der Daten in der Vektordatenbank Chroma
Sobald für alle Veranstaltungen eine Zusammenfassung erstellt wurde, werden alle Informationen inklusive ihrer Metadaten in einer Vektordatenbank gespeichert. Wir verwenden hierfür die Vektordatenbank Chroma, die auch bei LangChain enthalten ist. Anhand eines Embedding-Modells werden während des Speicherprozesses Embeddings für die übergebenen Texte berechnet. Die Embeddings werden für die spätere Selektion relevanter Dokumente verwendet.
streamlit-Anwendung als User-Interface
Nachdem wir nun alle relevanten Daten für die Generierung von Programmplänen haben, fehlt noch eine Oberfläche, über die User chatten können.
Hierfür verwenden wir die Open-Source-Python-Bibliothek streamlit. Mit streamlit können Webanwendungen für maschinelles Lernen und Data Science erstellt werden. Durch die zugehörige Streamlit Community Cloud können die entwickelten Anwendungen bereitgestellt und mit Anwendern geteilt werden.
User haben über das entwickelte Interface die Möglichkeit neben der Auswahl einer der Konferenztage in einem Textfeld ihre Interessen und Wünsche bezüglich der IT-Tage zu formulieren. Das Hauptfenster der Anwendung stellt dabei ein Chat-Fenster dar.
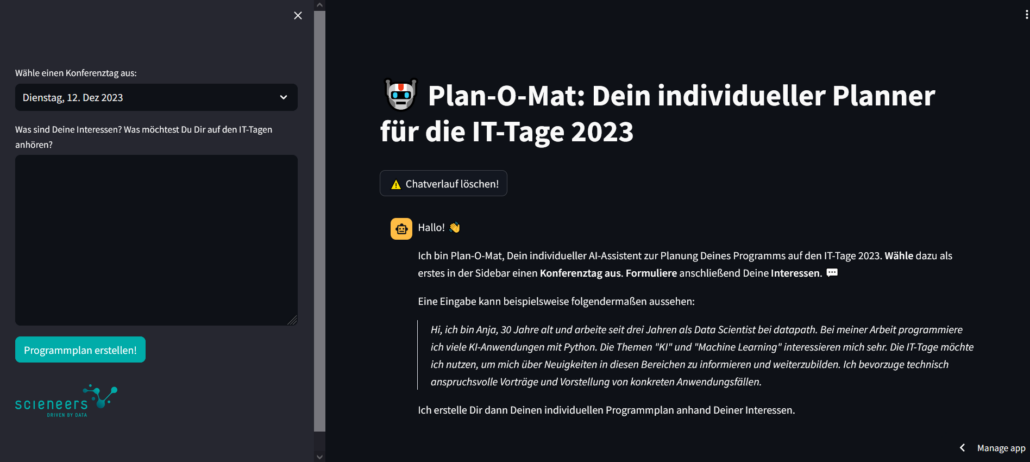
Streamlit-Anwendung als User-Interface
Durch Betätigung des Buttons „Programmplan erstellen!“ wird im Hintergrund die Eingabe und Auswahl des Konferenztages ausgelesen. Die Angabe des Tages wird verwendet, um eine erste Vorauswahl der Dokumente zu treffen und dadurch zu vermeiden, dass zu viele nicht benötigte Daten extrahiert werden. Für jeden Zeitslot des Konferenztages wird nun eine Veranstaltung ausgewählt, basierend auf den angegebenen Interessen und den Dokumenten als Kontext. Hierzu verwenden wir ebenfalls den Azure OpenAI Service in Verbindung mit LangChain. LangChain bietet die Klasse ConversationalRetrievalChain an, um Konversationen basierend auf abgerufenen Dokumenten führen zu können. Entscheidend für die Verwendung der Dokumente ist die Angabe des Retrievers in Zeile 3 des Code-Ausschnittes.
model = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=db.as_retriever(
search_kwargs={
"k": 2,
"filter": {"$and": [{"day": selected_option_day}, {"time": time_slot},]},
}
),
return_source_documents=True,
verbose=False,
combine_docs_chain_kwargs={"prompt": PROMPT_TEMPLATE},
)
Je nach ausgewähltem Tag sind unterschiedlich viele Zeitslots verfügbar. Um zu vermeiden, dass die maximale Tokenlänge erreicht wird, iterrieren wir daher über die einzelnen Zeitfenster und ersetzen bei jeder Iteration den Filter des Retrievers mit dem entsprechenden Slot.
Nach jeder Auswahl einer Veranstaltung wird die Antwort des Modells an den finalen Antwortstring gehängt. Am Ende kann dann der vollständig erstellte Programmplan über die streamlit-Oberfläche an den User ausgegeben werden.
Take Aways
Abschließend lässt sich festhalten, dass insbesondere Entscheidungen über das Speichern der Daten und das Herunterbrechen der Antwortgenerierung auf einzelne Zeitslots eine wichtige Rolle für eine gute Qualität der Ausgabe spielen. Viele Veranstaltungsbeschreibungen enthalten Informationen, die für den eigentlichen Anwendungsfall nicht interessant sind, dennoch zunächst ausgelesen werden. Werden solch lange Texte gespeichert, kann es zum Auftreten der oben genannten Problematiken kommen. Das Zusammenfassen der Texte stellte daher eine Lösung dar, die für uns gut funktionierte.
Auch die Verfassung der System-Message hatte entscheidende Auswirkungen auf die Antwortqualität. So half es beispielsweise anhand eines Beispiels das Antwortformat vorzugeben, um eine einheitliche Struktur zu erreichen oder anzugeben, dass Begründungen kursiv formatiert werden sollen.
Anmerkung:
Die Implementierung der Anwendung entstand im Rahmen meiner aktuellen Bachelorarbeit zum Thema „Personalisierte Textgestaltung durch die Verwendung großer Sprachmodelle“.
In diesem Rahmen suchen wir aktuell noch einen Kooperationspartner, der mit uns gemeinsam testen möchte, ob die Akzeptanz von Usern durch automatische Personalisierungstechniken verbessert werden kann. Wir benötigen hierfür einen populären Informationskanal (z.B. Newsletter, Blog), der eine große Reichweite an Tausenden von Usern bietet. Über die Nutzer sollten Informationen vorliegen.
Falls Sie einen solchen Informationskanal bieten und an einer Zusammenarbeit interessiert sind, würden wir uns über eine Kontaktaufnahme freuen.
Autorin
Alina Bickel