
Data Science and Agile in harmony – presenting the Agile Data Science Workflow
Building on practical experience, we developed an Agile Data Science Workflow that can be seamlessly integrated into different Agile frameworks. The workflow aims at fulfilling the needs of data scientists, scrum masters, product owners, and other stakeholders.
Data teams are part of many organizations nowadays and work not only to generate insights but also to develop tools and products. The need for reliable tools and products includes the development of software, which follows Agile principles for years now. Thus, it is not surprising that many organizations aim to build data teams that follow Agile guidelines and that work with other development teams in Agile frameworks, be it Scrum, Kanban, SAFe, LeSS, or any other acronym you can think of. The iterative dimension of data science fits well into any Agile principles; however, the exploratory dimension of data science has hindered the community from finding a suitable solution to fit data science into Agile frameworks. There are standards such as the Cross-industry standard process for data mining (CRISP-DM) and Knowledge Discovery in Databases (KDD). Yet, they are rather abstract and lack integration with Agile methods, e.g. Scrum, and project management tools such as Asana or Jira (or even Trello if you wish).
In our experience, the main challenges that a data science team may face when attempting to integrate data science into Agile frameworks are the following:
Challenge 1: Data science is hard to plan
Product owners and stakeholders need predictability and an estimate when they can expect the release of a new model. On the other hand, data scientists follow a complex and highly experimental process that requires time and care. This makes data science a hard to plan discipline. It is already difficult to plan a single sprint and even harder to plan for months in advance, a must in some Agile setups.
Challenge 2: Iterations are typically too short
If we do Agile, we ought to plan, develop, and deliver software in chunks that can fit within a sprint. Sprints typically last two or three weeks. However, to build a data-driven piece of software we will need a good exploratory data analysis, a model development phase, and a deployment. Kudos if you can fit all that in a two- or three-week sprint. We have tried it before and could not succeed.
Challenge 3: Data Scientists are curious
Data scientists have to ask questions about data, challenge assumptions and be imaginative in their solutions. However, curiosity and creativity also lead to some form of chaos. Data scientists have to execute many experiments to derive a model that helps the business in obtaining value. Often, we encounter one (or a few) rabbit holes in the process, and although we know that exploration is pivotal for the work of a data scientist, we cannot sacrifice predictability when other teams depend on our output.
Challenge 4: Working in a team with other data scientists
When working alone, you do all the work and (hopefully) you know what you did and what you are going to do next. However, if working within a data team, you will more often than not work with other data scientists. This requires a fair amount of coordination to organize the team and distribute the tasks.
Challenge 5: Stakeholders do not fully grasp data science (and the process) yet
Data science is often new to stakeholders. It is our task as data scientists to show how we operate and how we develop solutions that can help stakeholders in their decision making and daily business. By educating and creating transparency, we build trust and understanding, which are both valuable; however, this takes up time which could otherwise be used to develop models or do analyses.
Despite the challenges above, we enjoy regular exchanges with stakeholders and an iterative workflow that is confined to small iterations that suit our motto “start small, iterate fast”. Therefore, instead of turning our backs on Agile, we developed the Agile Data Science Workflow. This workflow helps us to:
- coordinate several data scientists and the implementation of different ideas,
- fit the implementation into sprint cycles,
- make the completion of deliverables more predictable,
- create transparency for the entire team, especially product owners and stakeholders.
The solution we present is not perfect, but we believe it is valuable. We have received feedback and have already gone through some improvement cycles. The version explained below is the result of these efforts.
The Agile Data Science Workflow
The Agile Data Science Workflow consists of different types of iterations and has the goal of reaching useful results in a few sprints. Firstly, one needs to define the business problem in close collaboration with the business partner. This may require several iterations so we recommend starting well ahead. Secondly, one will analyze the datasets available for the modelling and build the features for training in an Exploratory Data Analysis iteration. Thirdly, one will train a model in the Model Development iteration. In addition, a research iteration might be required in case the team faces a new problem or could not obtain satisfying results with the tools at hand. In our opinion, each of the iterations should be completed within one sprint or less. This avoids getting distracted from the goal by, e.g. all the interesting but off-topic new insights or the implementation of that overly complicated neural network architecture you once read in a paper.
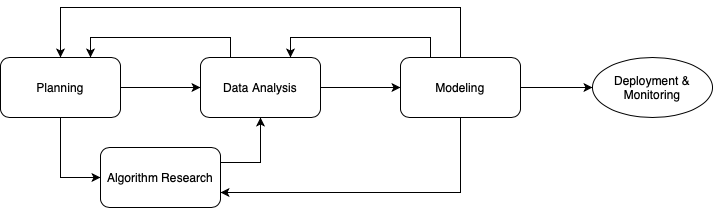
Simplified representation of the workflow depicting its basic building blocks. Image by author.
Within the workflow, one can always go back. Conversely, we strongly advise against skipping any step in the process. Experienced teams normally obtain useful results after one iteration of each type. New problems may require some buffer to account for uncertainty though. After all, we shall not forget that we are doing science.
Importantly, notice that we talk about useful results, not perfect results. The objective is to generate insights and, if relevant to the business problem, to deploy a model to test it live as soon as possible.
The iterations of the Agile Data Science Workflow, together with our “start small, iterate fast” motto, help us to plan our work more easily and to be more predictable.
Iteration type 1: Defining the business problem
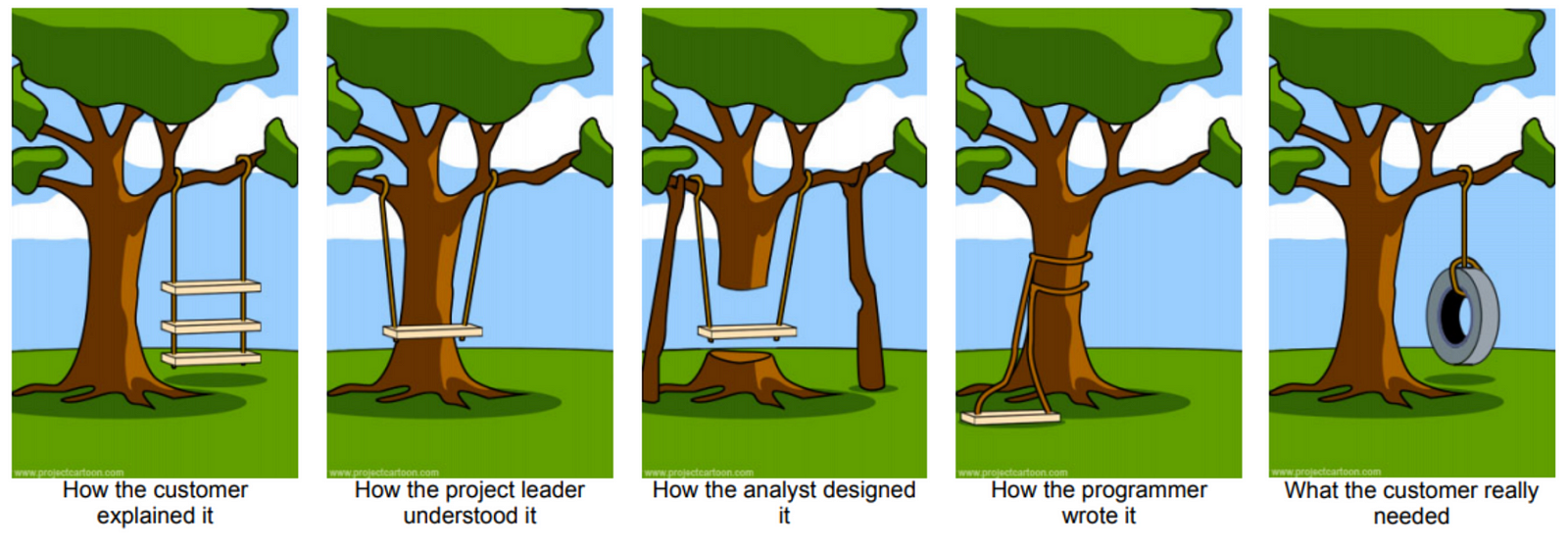
Software development: the tree swing illustration. Simplified by author, original source: https://medium.com/@thx2001r/the-project-cartoon-root-cause-5e82e404ec8a
Take some time to reflect on the image above. Many data science projects identify with one or more of the pictures above. The reasons may be multiple, from teams that misinterpret the requirements to stakeholders that are not aware of what they can expect from data science. Therefore, before jumping into any coding, it is paramount that the team sets the expectations. In addition, please also do ensure that the problem is SMART — i.e. Specific, Measurable, Achievable, Relevant, and Time-bound.
Checkpoints:
- Appoint the contact person on the business side and the development team side
- Work with the business to define the business KPI to optimize
- Determine the business value — even if it is only an approximation
- Assess data availability and data privacy requirements
Iteration type 2: EDA (Exploratory Data Analysis) and data preparation
An EDA is low-hanging fruit and stakeholders love it for three reasons: (i) many of them may not have the time or the knowledge to explore the data so they appreciate seeing the results of an EDA, and (ii) they feel involved into the data science process, (iii) they will be more likely to understand future and more complex reports.
What to do during this iteration? Understand the logic of the data, build a data dictionary and report the data quirks, so that your current team members — and the ones to come — are aware of them. Do also search for outliers, trends and patterns. Getting familiar with the data helps to build better models, to evaluate assumptions, and to identify new hypotheses. Feature engineering also belongs to this iteration. Gather information from stakeholders and other people with expertise in the field: which features can carry more predictive power?
Team alignment:
Discuss the results with your peers and define how to proceed. We recommend jumping into the modelling unless you need to re-plan, do research, or the EDA did not provide the grounds to develop a model. This should avoid getting trapped in a rabbit hole.
Checkpoints:
- Enquire the data and formulate new hypotheses
- Create target and predictive features
- Commit the code into a version control system, e.g. GitHub
- Let another team member review your code, especially in terms of logic and the definition of features and address their comments
- Document your work
Iteration type 3: Modelling
If you followed the guidelines above you already know which features are being considered. The next natural step is to discuss with your peers which metric you want to use to optimize your model. Afterwards, you need to figure out which algorithms you would like to test. Aim to use the simplest algorithm you know and resist the urge to start with a fancy algorithm in the first iteration. In the absence of a baseline, e.g. a business rule or a previous model, the first iteration will become your baseline.
Next, start building your workflow. Once you are ready, fit all your models and evaluate them based on the optimizing metric. Choose the best model and interpret its output: Which variables are the most important? How do the plots of the evaluation metrics look like? Can you identify clusters of misclassified data points? A good model interpretation will prevent you from running into premature conclusions, will help to identify problems such as data leakage early enough, and might provide some hints on which features to implement next in order to improve performance.
Team alignment:
Discuss the results with your peers, choose the best model and define how to proceed. Be realistic and accept that useful results do not need to be perfect results. If you have useful results then you are ready to proceed with e.g. a deployment or an A/B test iteration (not covered in this post).
Checkpoints:
- Decide on optimizing metric
- Train and evaluate models
- Select the best performing model
- Save training and validation data
- Save model artifacts
- Commit the code into a version control system
- Let another team member review your code and address their comments
- Document your work
- Present the results to the stakeholders
Ad hoc iteration: research
Data science and model development are highly experimental disciplines and sometimes the team will face problems that they cannot solve with their current knowledge. The project manager has to acknowledge that the team needs time to do some research. As a team member, aim to find the simplest approach to solve your problem.
Team alignment:
Discuss the methods you researched with your peers and evaluate the pros and cons of each method. Provide feedback to your peers about their research.
Checkpoints:
- Document all research in a shared folder or tool that everyone can access
- If there is any code produced in this iteration, commit the code into a version control system and let another team member review your code and documentation
After model development
If the aim is to deploy the model (which we hope it is), the team has to wait a couple of iterations more to celebrate. However, after this point, the process becomes slightly easier and resembles more the typical software development process. The upcoming steps include model deployment, A/B test if applicable and necessary, and continuous monitoring.
A code and a map to follow the model development process
Roles such as the product owner or scrum master appreciate a visualization and some code to track the advances of the team. As a visualization of the workflow, we drew a detailed process map with each of the steps of the workflow. These steps can be seen as tasks within each iteration.
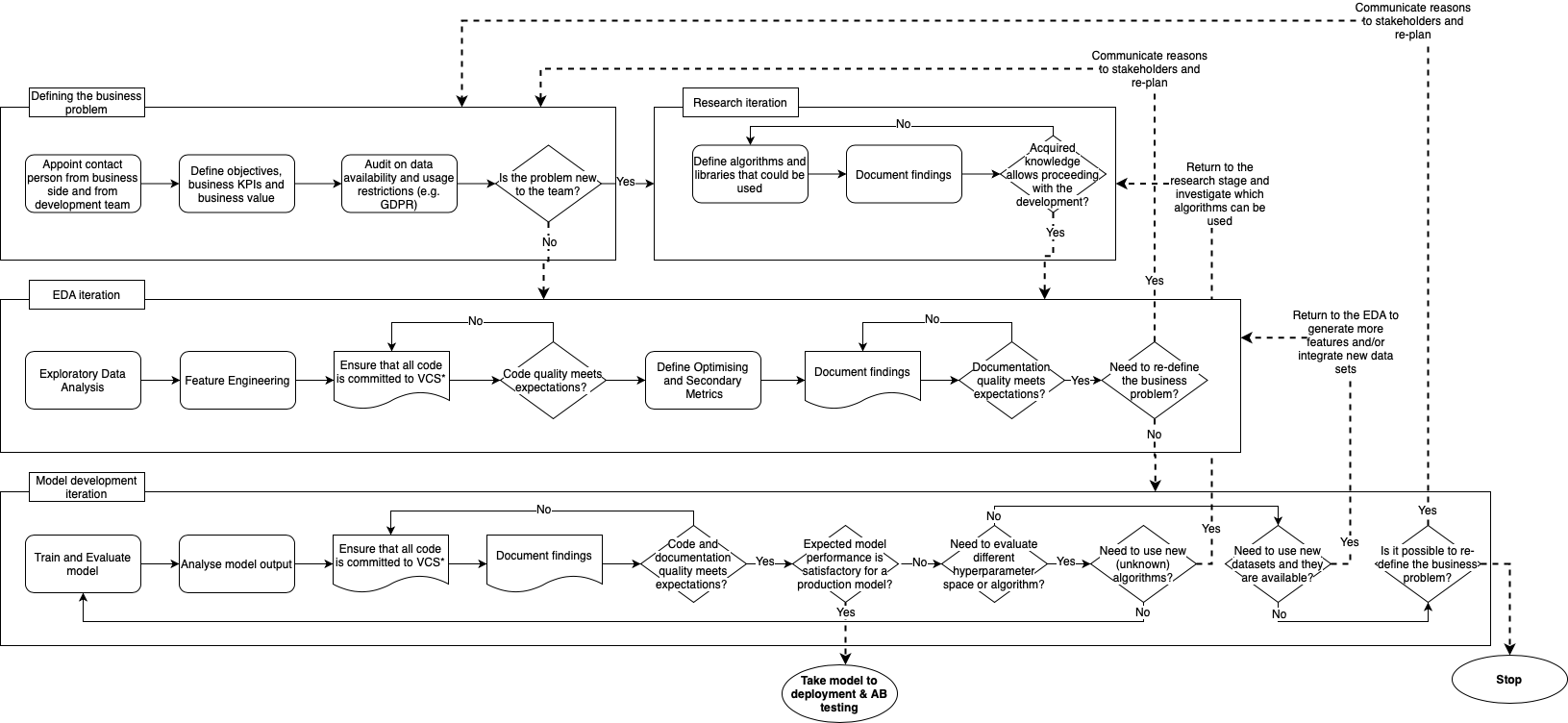
Full representation of the diagram. Dashed lines represent steps between different iteration types whereas solid lines represent steps within the same iteration type. VCS: Version Control System. Image by author.
We suggest to enumerate each iteration type with independent lists of ordinal integers plus a keyword, where the keyword can be anything such as “weather data”, “purchase records”, or “logistic regression”. Using an easy-to-understand code, and with the help of a map, project managers and other team members can track where the team is and the number of iterations that the team has completed. Furthermore, the code helps the team to map the iteration to the corresponding source code and the documentation that usually spreads across several tools.
Conclusion
Overall, breaking the workload into these iterations simplifies (1) the estimation of individual task load, (2) the planning of Agile cycles, and (3) the estimation of what we can deliver. It is still difficult, we know it. However, in our experience, we see a clearer path to our goal of e.g. developing a new model and we spend less time estimating story points, which — let’s be honest — makes us all happier.
Just as our way of working, this piece is Agile and should serve as a guide, not an obstacle. It is a living document that can be adjusted to your and your team’s needs.
Thank you for reading; we welcome and appreciate any feedback!
This article first appeared on Medium.