
 https://www.scieneers.de/wp-content/uploads/2026/05/Screenshot-2026-05-22-090434.jpeg
692
1272
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-26 08:27:482026-05-26 08:35:31Dynamische Disposition in Straßenbahndepots durch Reinforcement Learning
https://www.scieneers.de/wp-content/uploads/2026/05/Screenshot-2026-05-22-090434.jpeg
692
1272
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-26 08:27:482026-05-26 08:35:31Dynamische Disposition in Straßenbahndepots durch Reinforcement Learning
https://www.scieneers.de/wp-content/uploads/2026/05/Screenshot-2026-05-22-090434.jpeg
692
1272
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-26 08:27:482026-05-26 08:35:31Dynamische Disposition in Straßenbahndepots durch Reinforcement Learning
https://www.scieneers.de/wp-content/uploads/2026/05/Screenshot-2026-05-22-090434.jpeg
692
1272
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-26 08:27:482026-05-26 08:35:31Dynamische Disposition in Straßenbahndepots durch Reinforcement Learning https://www.scieneers.de/wp-content/uploads/2026/05/IMG_8452-scaled.jpg
1372
2560
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-18 11:57:432026-05-18 22:56:25Rückblick auf unser Frühlingsevent 2026
https://www.scieneers.de/wp-content/uploads/2026/05/IMG_8452-scaled.jpg
1372
2560
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-18 11:57:432026-05-18 22:56:25Rückblick auf unser Frühlingsevent 2026 https://www.scieneers.de/wp-content/uploads/2026/05/Blog-Post-Bild.png
1080
1920
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-13 16:30:072026-05-13 16:30:12Frühlingskonferenzen 2026: PyCon DE und PyData & Minds Mastering Machines
https://www.scieneers.de/wp-content/uploads/2026/05/Blog-Post-Bild.png
1080
1920
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-05-13 16:30:072026-05-13 16:30:12Frühlingskonferenzen 2026: PyCon DE und PyData & Minds Mastering Machines https://www.scieneers.de/wp-content/uploads/2026/04/MB-BP-Bild-Cropped.png
1080
1920
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-04-22 09:30:362026-05-06 14:36:03Gestaltungsmöglichkeiten für Mitarbeitende bei scieneers
https://www.scieneers.de/wp-content/uploads/2026/04/MB-BP-Bild-Cropped.png
1080
1920
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-04-22 09:30:362026-05-06 14:36:03Gestaltungsmöglichkeiten für Mitarbeitende bei scieneers  https://www.scieneers.de/wp-content/uploads/2026/03/Untitled-design.png
1260
2240
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-03-13 09:47:352026-05-13 13:45:48Bewerbungsprozess bei scieneers
https://www.scieneers.de/wp-content/uploads/2026/03/Untitled-design.png
1260
2240
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-03-13 09:47:352026-05-13 13:45:48Bewerbungsprozess bei scieneers https://www.scieneers.de/wp-content/uploads/2026/03/ms-ai-tour-launch-city.jpg
960
1472
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2026-03-12 22:22:492026-03-13 15:46:22Einblicke von der Microsoft AI Tour 2026 in München – zwischen Vision, Souveränität und konkreten Anwendungen
https://www.scieneers.de/wp-content/uploads/2026/03/ms-ai-tour-launch-city.jpg
960
1472
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2026-03-12 22:22:492026-03-13 15:46:22Einblicke von der Microsoft AI Tour 2026 in München – zwischen Vision, Souveränität und konkreten Anwendungen https://www.scieneers.de/wp-content/uploads/2026/02/PoC-vs-Prototyp-vs-MVP-vs-Pilot.png
1375
2385
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-02-06 13:50:342026-02-27 16:20:32PoC vs Prototyp vs MVP vs Pilot
https://www.scieneers.de/wp-content/uploads/2026/02/PoC-vs-Prototyp-vs-MVP-vs-Pilot.png
1375
2385
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2026-02-06 13:50:342026-02-27 16:20:32PoC vs Prototyp vs MVP vs Pilot https://www.scieneers.de/wp-content/uploads/2026/02/generation-0b7e1601-bb5a-46a3-8ec2-c8fbc34c2c85.png
752
1328
mats.faulborn@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
mats.faulborn@scieneers.de2026-02-05 15:08:342026-03-31 09:12:20KI-Bildgenerierung in der Praxis
https://www.scieneers.de/wp-content/uploads/2026/02/generation-0b7e1601-bb5a-46a3-8ec2-c8fbc34c2c85.png
752
1328
mats.faulborn@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
mats.faulborn@scieneers.de2026-02-05 15:08:342026-03-31 09:12:20KI-Bildgenerierung in der Praxis https://www.scieneers.de/wp-content/uploads/2025/12/IT-Tage-2025.jpg
150
300
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2025-12-19 13:45:202026-01-14 08:23:03IT-Tage 2025
https://www.scieneers.de/wp-content/uploads/2025/12/IT-Tage-2025.jpg
150
300
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2025-12-19 13:45:202026-01-14 08:23:03IT-Tage 2025 https://www.scieneers.de/wp-content/uploads/2025/12/blog_image-1-scaled.png
1445
2560
Arne Grobruegge
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Arne Grobruegge2025-12-15 09:44:152026-01-14 08:22:50Implementierung von RAG mit PostgreSQL
https://www.scieneers.de/wp-content/uploads/2025/12/blog_image-1-scaled.png
1445
2560
Arne Grobruegge
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Arne Grobruegge2025-12-15 09:44:152026-01-14 08:22:50Implementierung von RAG mit PostgreSQL https://www.scieneers.de/wp-content/uploads/2025/10/S4100449-scaled.jpg
1440
2560
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-10-08 15:45:392026-01-14 08:21:54Rückblick auf unser Herbstevent 2025
https://www.scieneers.de/wp-content/uploads/2025/10/S4100449-scaled.jpg
1440
2560
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-10-08 15:45:392026-01-14 08:21:54Rückblick auf unser Herbstevent 2025 https://www.scieneers.de/wp-content/uploads/2025/09/PyData-Berlin-Bild.png
1260
2240
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-09-05 17:43:282026-01-14 08:21:31PyData 2025
https://www.scieneers.de/wp-content/uploads/2025/09/PyData-Berlin-Bild.png
1260
2240
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-09-05 17:43:282026-01-14 08:21:31PyData 2025 https://www.scieneers.de/wp-content/uploads/2025/08/protein_structure_banner-1.png
1024
1792
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2025-08-05 22:51:032025-08-22 13:03:17Machine Learning Workflow zur Bewertung genetischer Varianten auf Basis von Proteinstruktur Embeddings
https://www.scieneers.de/wp-content/uploads/2025/08/protein_structure_banner-1.png
1024
1792
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2025-08-05 22:51:032025-08-22 13:03:17Machine Learning Workflow zur Bewertung genetischer Varianten auf Basis von Proteinstruktur Embeddings https://www.scieneers.de/wp-content/uploads/2025/05/DSCF06962-scaled.jpg
1440
2560
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-06-04 11:18:192025-08-22 13:04:07Rückblick auf unser Frühlingsevent 2025
https://www.scieneers.de/wp-content/uploads/2025/05/DSCF06962-scaled.jpg
1440
2560
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-06-04 11:18:192025-08-22 13:04:07Rückblick auf unser Frühlingsevent 2025 https://www.scieneers.de/wp-content/uploads/2025/06/2025-06-04-085111-dall-e-3.png
819
1024
Rupert Schneider
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Rupert Schneider2025-06-03 16:28:282025-08-22 13:05:31Microsoft Fabric: Mit Eventstreams Echtzeitdaten verarbeiten
https://www.scieneers.de/wp-content/uploads/2025/06/2025-06-04-085111-dall-e-3.png
819
1024
Rupert Schneider
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Rupert Schneider2025-06-03 16:28:282025-08-22 13:05:31Microsoft Fabric: Mit Eventstreams Echtzeitdaten verarbeiten https://www.scieneers.de/wp-content/uploads/2025/05/real_time_intelligence_1030x258.jpg
258
344
Rupert Schneider
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Rupert Schneider2025-05-23 09:37:392025-08-22 13:05:49Real-Time Intelligence: Echtzeitdaten in Microsoft Fabric
https://www.scieneers.de/wp-content/uploads/2025/05/real_time_intelligence_1030x258.jpg
258
344
Rupert Schneider
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Rupert Schneider2025-05-23 09:37:392025-08-22 13:05:49Real-Time Intelligence: Echtzeitdaten in Microsoft Fabric https://www.scieneers.de/wp-content/uploads/2025/05/m3-header.jpg-95618f16427fc555-1.webp
567
1008
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-05-21 14:37:012025-08-22 13:07:07M3 2025
https://www.scieneers.de/wp-content/uploads/2025/05/m3-header.jpg-95618f16427fc555-1.webp
567
1008
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-05-21 14:37:012025-08-22 13:07:07M3 2025 https://www.scieneers.de/wp-content/uploads/2025/05/2025-05-07-112120-dall-e-3.png
1024
1792
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-05-07 14:56:392026-04-29 16:11:49Wärmebedarf prognostizieren mit Temporal Fusion Transformern
https://www.scieneers.de/wp-content/uploads/2025/05/2025-05-07-112120-dall-e-3.png
1024
1792
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-05-07 14:56:392026-04-29 16:11:49Wärmebedarf prognostizieren mit Temporal Fusion Transformern https://www.scieneers.de/wp-content/uploads/2025/03/ChatGPT-Image-Apr-1-2025-09_43_18-PM.png
1024
1536
Sebastian Drewke
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Sebastian Drewke2025-04-02 21:11:072025-08-22 13:07:21Kleinere Docker Images mit uv
https://www.scieneers.de/wp-content/uploads/2025/03/ChatGPT-Image-Apr-1-2025-09_43_18-PM.png
1024
1536
Sebastian Drewke
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Sebastian Drewke2025-04-02 21:11:072025-08-22 13:07:21Kleinere Docker Images mit uv https://www.scieneers.de/wp-content/uploads/2025/03/LinkedIn-Post-Bild.-DEpng.png
1080
1080
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-03-10 12:03:262025-08-22 13:07:33Microsoft Fabric Webinar 2025
https://www.scieneers.de/wp-content/uploads/2025/03/LinkedIn-Post-Bild.-DEpng.png
1080
1080
shinchit.han@scieneers.de
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
shinchit.han@scieneers.de2025-03-10 12:03:262025-08-22 13:07:33Microsoft Fabric Webinar 2025 https://www.scieneers.de/wp-content/uploads/2025/02/as.png
1024
1024
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-03-07 09:06:552026-03-05 09:56:06Mit Scrum erfolgreich sein in Forschung und Entwicklung
https://www.scieneers.de/wp-content/uploads/2025/02/as.png
1024
1024
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-03-07 09:06:552026-03-05 09:56:06Mit Scrum erfolgreich sein in Forschung und Entwicklung https://www.scieneers.de/wp-content/uploads/2025/02/Image-4-1.png
486
843
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-02-26 14:15:122025-08-22 13:08:16Microsoft Fabric Deployment
https://www.scieneers.de/wp-content/uploads/2025/02/Image-4-1.png
486
843
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-02-26 14:15:122025-08-22 13:08:16Microsoft Fabric Deployment https://www.scieneers.de/wp-content/uploads/2025/02/Output-desinfonavigator_0.png
914
1672
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-02-21 11:03:012025-08-22 13:08:30DesinfoNavigator
https://www.scieneers.de/wp-content/uploads/2025/02/Output-desinfonavigator_0.png
914
1672
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-02-21 11:03:012025-08-22 13:08:30DesinfoNavigator https://www.scieneers.de/wp-content/uploads/2025/01/L1021346-1210x423-1.jpg
844
2420
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-01-31 08:52:002025-08-22 13:08:49Benefits bei scieneers
https://www.scieneers.de/wp-content/uploads/2025/01/L1021346-1210x423-1.jpg
844
2420
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2025-01-31 08:52:002025-08-22 13:08:49Benefits bei scieneers https://www.scieneers.de/wp-content/uploads/2024/12/bild.jpg
899
1599
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2024-12-18 15:51:332025-08-22 13:09:04KI trifft Datenschutz: Unsere ChatGPT-Lösung für Unternehmenswissen
https://www.scieneers.de/wp-content/uploads/2024/12/bild.jpg
899
1599
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2024-12-18 15:51:332025-08-22 13:09:04KI trifft Datenschutz: Unsere ChatGPT-Lösung für Unternehmenswissen https://www.scieneers.de/wp-content/uploads/2024/11/aa.jpg
413
744
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-11-08 11:57:012025-08-22 13:09:22Wie Studierende von LLMs und Chatbots profitieren können
https://www.scieneers.de/wp-content/uploads/2024/11/aa.jpg
413
744
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-11-08 11:57:012025-08-22 13:09:22Wie Studierende von LLMs und Chatbots profitieren können https://www.scieneers.de/wp-content/uploads/2024/10/20241022_161307-scaled-e1730281812544.jpg
1224
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2024-10-31 12:50:032025-01-31 13:31:01KI für das Gemeinwohl auf dem Digital-Gipfel 2024
https://www.scieneers.de/wp-content/uploads/2024/10/20241022_161307-scaled-e1730281812544.jpg
1224
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2024-10-31 12:50:032025-01-31 13:31:01KI für das Gemeinwohl auf dem Digital-Gipfel 2024 https://www.scieneers.de/wp-content/uploads/2024/10/neu.jpg
758
1024
Arne Grobruegge
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Arne Grobruegge2024-10-23 09:15:402025-08-22 13:10:04Der Einsatz von VideoRAG für den Wissenstransfer im Unternehmen
https://www.scieneers.de/wp-content/uploads/2024/10/neu.jpg
758
1024
Arne Grobruegge
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Arne Grobruegge2024-10-23 09:15:402025-08-22 13:10:04Der Einsatz von VideoRAG für den Wissenstransfer im Unternehmen https://www.scieneers.de/wp-content/uploads/2024/10/stefan-kriner-sql-konferenz.png
1486
2514
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2024-10-14 16:45:432025-01-31 13:32:21Data Factory in Fabric – the good, the bad and the ugly
https://www.scieneers.de/wp-content/uploads/2024/10/stefan-kriner-sql-konferenz.png
1486
2514
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2024-10-14 16:45:432025-01-31 13:32:21Data Factory in Fabric – the good, the bad and the ugly https://www.scieneers.de/wp-content/uploads/2024/09/DPK_9954-scaled.jpg
1709
2560
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2024-09-24 16:24:462025-01-31 13:32:52Multi-Agenten LLM auf der Data2Day
https://www.scieneers.de/wp-content/uploads/2024/09/DPK_9954-scaled.jpg
1709
2560
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2024-09-24 16:24:462025-01-31 13:32:52Multi-Agenten LLM auf der Data2Day https://www.scieneers.de/wp-content/uploads/2024/09/Unbenannt.png
1080
1920
Maximilian Leist
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Maximilian Leist2024-09-20 16:23:142025-01-31 13:33:43Logic App API Connections – Herausforderungen und Lösungswege in der Verwaltung
https://www.scieneers.de/wp-content/uploads/2024/09/Unbenannt.png
1080
1920
Maximilian Leist
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Maximilian Leist2024-09-20 16:23:142025-01-31 13:33:43Logic App API Connections – Herausforderungen und Lösungswege in der Verwaltung https://www.scieneers.de/wp-content/uploads/2024/09/charta_der_vielfalt-v2-1.1200x630-ms.jpg
630
1064
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-09-12 18:33:452025-01-31 13:35:09Diversity als Chance ➯ scieneers & Charta der Vielfalt
https://www.scieneers.de/wp-content/uploads/2024/09/charta_der_vielfalt-v2-1.1200x630-ms.jpg
630
1064
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-09-12 18:33:452025-01-31 13:35:09Diversity als Chance ➯ scieneers & Charta der Vielfalt European Society of Human Genetics
https://www.scieneers.de/wp-content/uploads/2024/06/53782461515_2a32608750_k.jpg
1320
2048
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2024-06-11 14:48:302024-06-14 09:30:44Einblicke in die European Society of Human Genetics Konferenz 2024
European Society of Human Genetics
https://www.scieneers.de/wp-content/uploads/2024/06/53782461515_2a32608750_k.jpg
1320
2048
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2024-06-11 14:48:302024-06-14 09:30:44Einblicke in die European Society of Human Genetics Konferenz 2024 https://www.scieneers.de/wp-content/uploads/2024/05/S4100729-scaled.jpg
1700
2560
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-05-28 07:51:122024-05-28 08:01:20Diversität bei scieneers
https://www.scieneers.de/wp-content/uploads/2024/05/S4100729-scaled.jpg
1700
2560
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-05-28 07:51:122024-05-28 08:01:20Diversität bei scieneers https://www.scieneers.de/wp-content/uploads/2024/04/fresenius_frontend.png
1327
2551
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-04-23 12:15:432024-06-25 08:52:10NextGeneration:AI – Innovation trifft Datenschutz
https://www.scieneers.de/wp-content/uploads/2024/04/fresenius_frontend.png
1327
2551
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2024-04-23 12:15:432024-06-25 08:52:10NextGeneration:AI – Innovation trifft Datenschutz https://www.scieneers.de/wp-content/uploads/2024/03/Screenshot-2024-03-28-at-17.48.35.png
1770
3108
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2024-03-28 17:49:562025-01-31 13:40:05Multi-Agenten-LLM-Systeme kontrollieren mit LangGraph
https://www.scieneers.de/wp-content/uploads/2024/03/Screenshot-2024-03-28-at-17.48.35.png
1770
3108
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2024-03-28 17:49:562025-01-31 13:40:05Multi-Agenten-LLM-Systeme kontrollieren mit LangGraph https://www.scieneers.de/wp-content/uploads/2024/03/DALL·E-2024-03-24-09.52.46-Revise-the-cover-image-for-the-article-Eine-Einfuehrung-in-Multi-Agent-AI-mit-AutoGen-to-focus-on-small-robot-heads-representing-agents-within-a-mult.webp
1024
1792
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2024-03-24 09:55:552025-01-31 13:40:29Eine Einführung in Multi-Agent-AI mit AutoGen
https://www.scieneers.de/wp-content/uploads/2024/03/DALL·E-2024-03-24-09.52.46-Revise-the-cover-image-for-the-article-Eine-Einfuehrung-in-Multi-Agent-AI-mit-AutoGen-to-focus-on-small-robot-heads-representing-agents-within-a-mult.webp
1024
1792
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2024-03-24 09:55:552025-01-31 13:40:29Eine Einführung in Multi-Agent-AI mit AutoGen https://www.scieneers.de/wp-content/uploads/2024/03/Screenshot-2024-03-14-at-14.29.46.png
1618
3004
Maximilian Leist
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Maximilian Leist2024-03-19 08:48:562025-01-31 13:40:57Power BI Sicherheit: Wie Power Apps die Verwaltung von Row-Level-Security auf das nächste Level hebt
https://www.scieneers.de/wp-content/uploads/2024/03/Screenshot-2024-03-14-at-14.29.46.png
1618
3004
Maximilian Leist
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Maximilian Leist2024-03-19 08:48:562025-01-31 13:40:57Power BI Sicherheit: Wie Power Apps die Verwaltung von Row-Level-Security auf das nächste Level hebt https://www.scieneers.de/wp-content/uploads/2024/03/DALL·E-2024-03-06-09.27.00-Visualize-the-concept-of-self-service-business-intelligence-BI-without-including-any-text-in-the-image-for-use-as-a-blog-post-title-image.-The-desi.webp
1024
1792
Milo Sikora
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Milo Sikora2024-03-06 09:19:482024-03-19 08:48:08Die fünf Schritte des Power BI-Workflows: Ein praktischer Leitfaden mit Tipps
https://www.scieneers.de/wp-content/uploads/2024/03/DALL·E-2024-03-06-09.27.00-Visualize-the-concept-of-self-service-business-intelligence-BI-without-including-any-text-in-the-image-for-use-as-a-blog-post-title-image.-The-desi.webp
1024
1792
Milo Sikora
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Milo Sikora2024-03-06 09:19:482024-03-19 08:48:08Die fünf Schritte des Power BI-Workflows: Ein praktischer Leitfaden mit Tipps https://www.scieneers.de/wp-content/uploads/2024/02/dna-3539309_1920.jpg
960
1920
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2024-02-29 16:55:032024-03-01 12:56:49Erforschung des Dark Genome mit Machine Learning zur Entwicklung neuartiger Krankheitsinterventionen
https://www.scieneers.de/wp-content/uploads/2024/02/dna-3539309_1920.jpg
960
1920
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2024-02-29 16:55:032024-03-01 12:56:49Erforschung des Dark Genome mit Machine Learning zur Entwicklung neuartiger Krankheitsinterventionen https://www.scieneers.de/wp-content/uploads/2024/02/Screenshot-2024-02-05-at-11.21.57.png
956
952
Alina Bickel
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Bickel2024-02-05 08:49:562025-01-31 13:00:47Personalisierte Stellenausschreibungen durch LLMs auf Grundlage einer Personenbeschreibung
https://www.scieneers.de/wp-content/uploads/2024/02/Screenshot-2024-02-05-at-11.21.57.png
956
952
Alina Bickel
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Bickel2024-02-05 08:49:562025-01-31 13:00:47Personalisierte Stellenausschreibungen durch LLMs auf Grundlage einer Personenbeschreibung https://www.scieneers.de/wp-content/uploads/2023/11/rwthgpt_1.png
1024
1024
Jan Höllmer
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jan Höllmer2023-12-02 10:00:002025-01-31 13:02:22rwthGPT – Eine datenschutzkonforme Plattform für OpenAI-Modelle
https://www.scieneers.de/wp-content/uploads/2023/11/rwthgpt_1.png
1024
1024
Jan Höllmer
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jan Höllmer2023-12-02 10:00:002025-01-31 13:02:22rwthGPT – Eine datenschutzkonforme Plattform für OpenAI-Modelle https://www.scieneers.de/wp-content/uploads/2021/02/cloud-security-800x.jpg
533
800
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2023-11-15 11:22:102025-01-31 13:12:13Data Platform auf Azure – aber bitte sicher!
https://www.scieneers.de/wp-content/uploads/2021/02/cloud-security-800x.jpg
533
800
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2023-11-15 11:22:102025-01-31 13:12:13Data Platform auf Azure – aber bitte sicher! https://www.scieneers.de/wp-content/uploads/2023/09/cw28_mainbanner_intel-xeon-processor-de.jpeg
480
1440
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2023-09-29 12:08:372025-01-31 13:15:26Optimize an AI Powered Recommendation Engine
https://www.scieneers.de/wp-content/uploads/2023/09/cw28_mainbanner_intel-xeon-processor-de.jpeg
480
1440
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2023-09-29 12:08:372025-01-31 13:15:26Optimize an AI Powered Recommendation Engine https://www.scieneers.de/wp-content/uploads/2023/09/otto_3.png
1024
1024
Moritz Renftle
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Moritz Renftle2023-09-16 18:19:112023-09-19 08:54:10LLMs und Cloud-Technologien zur Vernetzung von Onlineshops der Otto-Gruppe
https://www.scieneers.de/wp-content/uploads/2023/09/otto_3.png
1024
1024
Moritz Renftle
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Moritz Renftle2023-09-16 18:19:112023-09-19 08:54:10LLMs und Cloud-Technologien zur Vernetzung von Onlineshops der Otto-Gruppe https://www.scieneers.de/wp-content/uploads/2023/08/district_heating.jpg
512
512
Jan Höllmer
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jan Höllmer2023-08-30 09:19:132023-10-22 15:18:42Wärmebedarf prognostizieren mit Temporal Fusion Transformern
https://www.scieneers.de/wp-content/uploads/2023/08/district_heating.jpg
512
512
Jan Höllmer
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jan Höllmer2023-08-30 09:19:132023-10-22 15:18:42Wärmebedarf prognostizieren mit Temporal Fusion Transformern https://www.scieneers.de/wp-content/uploads/2023/08/moodle2gpt_blog_thumbnail.png
1024
1024
Jan Höllmer
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jan Höllmer2023-08-17 15:00:252023-09-28 08:06:55Moodle Chatbot – KI als persönlicher Uni-Dozent
https://www.scieneers.de/wp-content/uploads/2023/08/moodle2gpt_blog_thumbnail.png
1024
1024
Jan Höllmer
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jan Höllmer2023-08-17 15:00:252023-09-28 08:06:55Moodle Chatbot – KI als persönlicher Uni-Dozent https://www.scieneers.de/wp-content/uploads/2023/08/digitization-5180477_1920.jpg
1280
1920
Lars Perchalla
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Lars Perchalla2023-08-14 10:59:382025-01-31 13:20:20KI-basierte Textanalyse für die Energiewirtschaft
https://www.scieneers.de/wp-content/uploads/2023/08/digitization-5180477_1920.jpg
1280
1920
Lars Perchalla
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Lars Perchalla2023-08-14 10:59:382025-01-31 13:20:20KI-basierte Textanalyse für die Energiewirtschaft https://www.scieneers.de/wp-content/uploads/2023/08/wind-offshore-v2.jpeg
864
1536
Dr. Philip Witte
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Dr. Philip Witte2023-08-10 12:14:162023-08-11 11:05:00Anomalieerkennung bei Windkraftanlagen mit Temporal Fusion Transformern für Iqony
https://www.scieneers.de/wp-content/uploads/2023/08/wind-offshore-v2.jpeg
864
1536
Dr. Philip Witte
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Dr. Philip Witte2023-08-10 12:14:162023-08-11 11:05:00Anomalieerkennung bei Windkraftanlagen mit Temporal Fusion Transformern für Iqony https://www.scieneers.de/wp-content/uploads/2023/06/iX-Special-KI-Kopie-e1687939279592.png
422
1000
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2023-06-28 15:07:162025-01-31 13:22:01Mit scikit-learn Modelle erstellen
https://www.scieneers.de/wp-content/uploads/2023/06/iX-Special-KI-Kopie-e1687939279592.png
422
1000
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2023-06-28 15:07:162025-01-31 13:22:01Mit scikit-learn Modelle erstellen https://www.scieneers.de/wp-content/uploads/2023/05/pyCon-blog-title-2023.jpg
675
1200
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2023-05-10 15:08:522025-01-31 13:11:17scieneers at PyCon DE & PyData Berlin 2023
https://www.scieneers.de/wp-content/uploads/2023/05/pyCon-blog-title-2023.jpg
675
1200
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2023-05-10 15:08:522025-01-31 13:11:17scieneers at PyCon DE & PyData Berlin 2023 https://www.scieneers.de/wp-content/uploads/2023/03/power_bi_laptop.jpg
848
1500
Milo Sikora
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Milo Sikora2023-04-04 12:55:382023-04-20 09:44:49Einführung in Microsofts Power BI Plattform
https://www.scieneers.de/wp-content/uploads/2023/03/power_bi_laptop.jpg
848
1500
Milo Sikora
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Milo Sikora2023-04-04 12:55:382023-04-20 09:44:49Einführung in Microsofts Power BI Plattform https://www.scieneers.de/wp-content/uploads/2023/03/glass_production_shutterstock.png
618
1500
Paul Krueckemeier
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Paul Krueckemeier2023-03-28 09:49:542025-01-31 11:42:13Kooperation SCHOTT AG – scieneers: MIP Reporting mit Power BI
https://www.scieneers.de/wp-content/uploads/2023/03/glass_production_shutterstock.png
618
1500
Paul Krueckemeier
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Paul Krueckemeier2023-03-28 09:49:542025-01-31 11:42:13Kooperation SCHOTT AG – scieneers: MIP Reporting mit Power BI scieneers
https://www.scieneers.de/wp-content/uploads/2023/01/Bildschirmfoto-2023-01-19-um-09.19.39.png
406
618
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2023-01-20 12:22:222025-01-31 11:47:41Einführung in Unittesting mit Python für Data Scientists
scieneers
https://www.scieneers.de/wp-content/uploads/2023/01/Bildschirmfoto-2023-01-19-um-09.19.39.png
406
618
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2023-01-20 12:22:222025-01-31 11:47:41Einführung in Unittesting mit Python für Data Scientists https://www.scieneers.de/wp-content/uploads/2022/12/Demodaten.png
675
3055
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2023-01-11 13:29:472025-01-31 11:48:56Explorative Geodaten-Analyse mit Power BI bei Ämtern und Behörden
https://www.scieneers.de/wp-content/uploads/2022/12/Demodaten.png
675
3055
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2023-01-11 13:29:472025-01-31 11:48:56Explorative Geodaten-Analyse mit Power BI bei Ämtern und Behörden https://www.scieneers.de/wp-content/uploads/2022/11/data_science_crisp_prozess.jpg
1262
1920
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2022-12-14 15:00:232025-01-31 11:54:47Entwicklung nach SCRUM und CRISP-DM am Fallbeispiel Wärmeprognose bei STEAG New Energies
https://www.scieneers.de/wp-content/uploads/2022/11/data_science_crisp_prozess.jpg
1262
1920
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2022-12-14 15:00:232025-01-31 11:54:47Entwicklung nach SCRUM und CRISP-DM am Fallbeispiel Wärmeprognose bei STEAG New Energies Free for commercial use, photo by Kevin Ku on Unsplash
https://www.scieneers.de/wp-content/uploads/2022/11/code-review-scaled-e1669798428762.jpg
1715
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2022-11-30 10:50:062025-01-31 11:55:10Effektive Code Reviews für Data-Science-Projekte
Free for commercial use, photo by Kevin Ku on Unsplash
https://www.scieneers.de/wp-content/uploads/2022/11/code-review-scaled-e1669798428762.jpg
1715
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2022-11-30 10:50:062025-01-31 11:55:10Effektive Code Reviews für Data-Science-Projekte https://www.scieneers.de/wp-content/uploads/2022/10/SQLDays2023_Vortrag.jpg
1280
1920
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-11-02 13:16:442025-01-31 11:56:44SQLDays – Vortrag Azure Data Factory 2022 – whats new?
https://www.scieneers.de/wp-content/uploads/2022/10/SQLDays2023_Vortrag.jpg
1280
1920
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-11-02 13:16:442025-01-31 11:56:44SQLDays – Vortrag Azure Data Factory 2022 – whats new? Adi Goldstein
https://www.scieneers.de/wp-content/uploads/2022/10/AdiGoldstein_plantine.png
837
1920
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2022-10-27 12:29:222025-01-31 11:57:39Kooperation mit Intel®: Quantisierung von ML-Modellen und Performance-Boost im Pre-Processing
Adi Goldstein
https://www.scieneers.de/wp-content/uploads/2022/10/AdiGoldstein_plantine.png
837
1920
Martin Danner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Martin Danner2022-10-27 12:29:222025-01-31 11:57:39Kooperation mit Intel®: Quantisierung von ML-Modellen und Performance-Boost im Pre-Processing https://www.scieneers.de/wp-content/uploads/2022/09/Folie1.png
540
720
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2022-10-17 15:12:322023-02-08 15:33:28Tipps & Tricks bei der Entwicklung eines Dashboards mit Streamlit & Plotly
https://www.scieneers.de/wp-content/uploads/2022/09/Folie1.png
540
720
Alina Dallmann
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alina Dallmann2022-10-17 15:12:322023-02-08 15:33:28Tipps & Tricks bei der Entwicklung eines Dashboards mit Streamlit & Plotly https://www.scieneers.de/wp-content/uploads/2022/09/ifbw22.png
600
800
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2022-09-29 07:34:182025-01-31 11:58:52informatica feminale Baden-Württemberg 2022 – ein Rückblick
https://www.scieneers.de/wp-content/uploads/2022/09/ifbw22.png
600
800
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2022-09-29 07:34:182025-01-31 11:58:52informatica feminale Baden-Württemberg 2022 – ein Rückblick https://www.scieneers.de/wp-content/uploads/2022/07/2022-06-03-09.39.24-scaled.jpg
1505
2560
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2022-08-03 13:51:492022-08-03 13:55:12Konferenz-Rückblick: DataLift Summit
https://www.scieneers.de/wp-content/uploads/2022/07/2022-06-03-09.39.24-scaled.jpg
1505
2560
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2022-08-03 13:51:492022-08-03 13:55:12Konferenz-Rückblick: DataLift Summit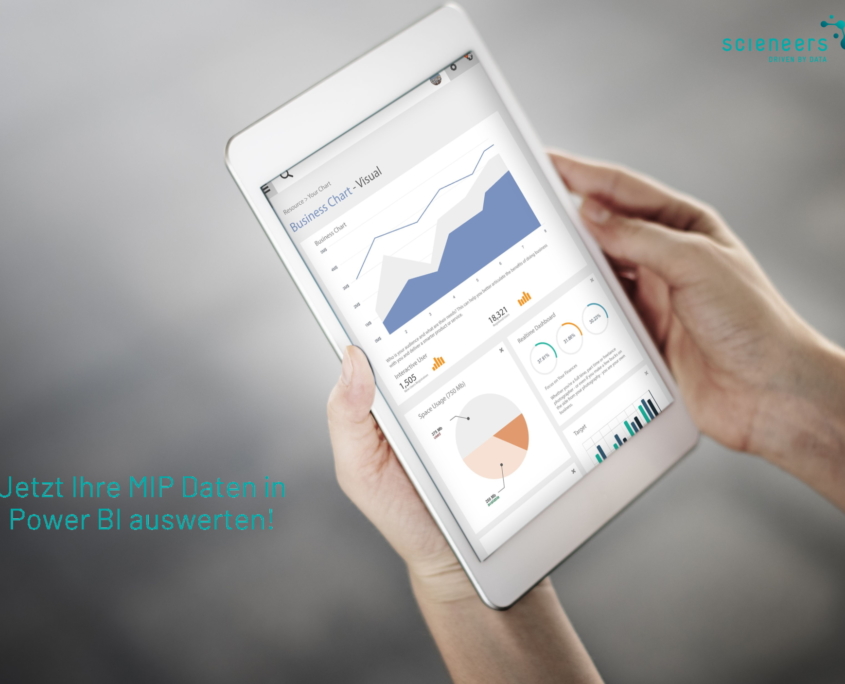 https://www.scieneers.de/wp-content/uploads/2022/07/MIP-Ihre-Daten-in-Power-BI.jpg
1407
1920
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-07-20 09:25:482025-01-31 12:51:02Partnerschaft MPDV – scieneers: MIP smart factory Daten in Power BI
https://www.scieneers.de/wp-content/uploads/2022/07/MIP-Ihre-Daten-in-Power-BI.jpg
1407
1920
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-07-20 09:25:482025-01-31 12:51:02Partnerschaft MPDV – scieneers: MIP smart factory Daten in Power BI https://www.scieneers.de/wp-content/uploads/2022/07/Pass_Camp_smaller.jpg
787
1918
Milo Sikora
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Milo Sikora2022-07-15 09:53:072025-01-31 12:53:02PASS Camp 2022 – Ein Einblick
https://www.scieneers.de/wp-content/uploads/2022/07/Pass_Camp_smaller.jpg
787
1918
Milo Sikora
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Milo Sikora2022-07-15 09:53:072025-01-31 12:53:02PASS Camp 2022 – Ein Einblick Steag New Energies GmbH
https://www.scieneers.de/wp-content/uploads/2022/05/steag-040.jpg
1280
1920
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-07-07 14:05:352025-01-31 12:55:19Voll auf Kurs: optimierte Energieerzeugung dank KI
Steag New Energies GmbH
https://www.scieneers.de/wp-content/uploads/2022/05/steag-040.jpg
1280
1920
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-07-07 14:05:352025-01-31 12:55:19Voll auf Kurs: optimierte Energieerzeugung dank KI https://www.scieneers.de/wp-content/uploads/2022/06/Gruppenfoto-scaled.jpg
1685
2560
Jonas Meier
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jonas Meier2022-06-22 15:08:122025-01-31 12:55:46Frühlingserwachen 2022
https://www.scieneers.de/wp-content/uploads/2022/06/Gruppenfoto-scaled.jpg
1685
2560
Jonas Meier
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Jonas Meier2022-06-22 15:08:122025-01-31 12:55:46Frühlingserwachen 2022 https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
0
0
Daniela Wecker
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Daniela Wecker2022-06-01 10:24:142025-01-31 12:56:50BI Consultant Getting Started mit PySpark Notebooks
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
0
0
Daniela Wecker
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Daniela Wecker2022-06-01 10:24:142025-01-31 12:56:50BI Consultant Getting Started mit PySpark Notebooks Photo courtesy of Lwala Community Alliance
https://www.scieneers.de/wp-content/uploads/2022/05/DSCF3688-scaled.jpeg
1748
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2022-05-25 21:03:382025-01-31 12:57:12Good data quality can save lives
Photo courtesy of Lwala Community Alliance
https://www.scieneers.de/wp-content/uploads/2022/05/DSCF3688-scaled.jpeg
1748
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2022-05-25 21:03:382025-01-31 12:57:12Good data quality can save lives https://www.scieneers.de/wp-content/uploads/2022/04/pyCon-blog-title.jpg
675
1200
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2022-05-18 11:00:432025-01-31 11:30:51Our talks at PyCon DE/PyData Berlin
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
0
0
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-03-11 15:00:432025-01-31 11:31:48Live Demo: MIP Daten in Power BI
https://www.scieneers.de/wp-content/uploads/2022/04/pyCon-blog-title.jpg
675
1200
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2022-05-18 11:00:432025-01-31 11:30:51Our talks at PyCon DE/PyData Berlin
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
0
0
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2022-03-11 15:00:432025-01-31 11:31:48Live Demo: MIP Daten in Power BI https://www.scieneers.de/wp-content/uploads/2021/12/20210910_scieneers_0257-scaled.jpg
1706
2560
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2021-12-23 10:11:582025-01-31 11:32:39Review 2021
https://www.scieneers.de/wp-content/uploads/2021/12/20210910_scieneers_0257-scaled.jpg
1706
2560
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2021-12-23 10:11:582025-01-31 11:32:39Review 2021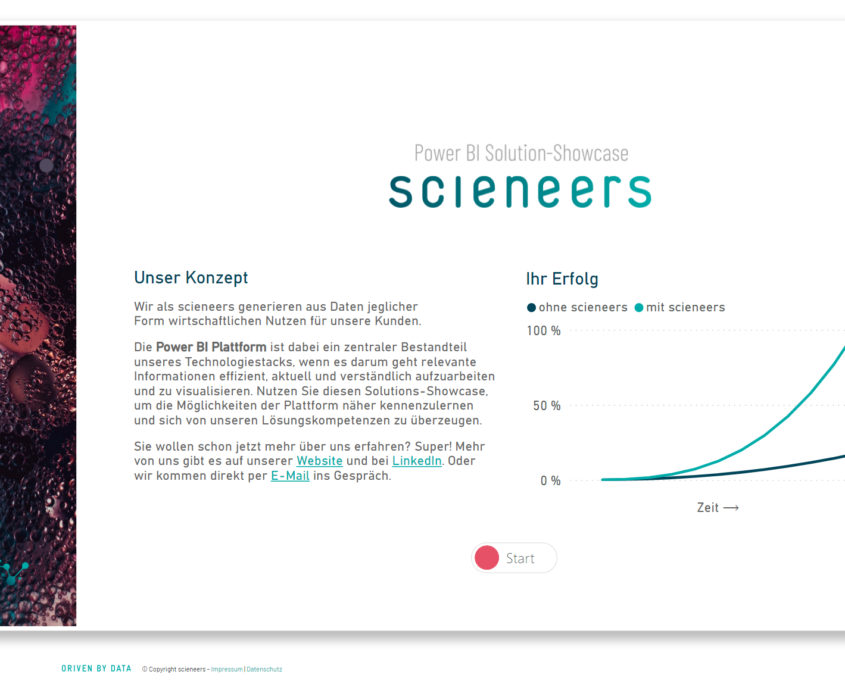 https://www.scieneers.de/wp-content/uploads/2021/11/pbi-solution-showcase3.png
1149
1938
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-11-16 14:30:012025-01-31 11:33:07Power BI Solution Deutsch
https://www.scieneers.de/wp-content/uploads/2021/11/pbi-solution-showcase3.png
1149
1938
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-11-16 14:30:012025-01-31 11:33:07Power BI Solution Deutsch https://www.scieneers.de/wp-content/uploads/2021/10/Bild-Stefan-Speaking.jpg
1224
1837
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-10-20 09:47:122021-10-20 09:47:12Reicht auch Power BI only für mein Projekt?
https://www.scieneers.de/wp-content/uploads/2021/10/Bild-Stefan-Speaking.jpg
1224
1837
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-10-20 09:47:122021-10-20 09:47:12Reicht auch Power BI only für mein Projekt?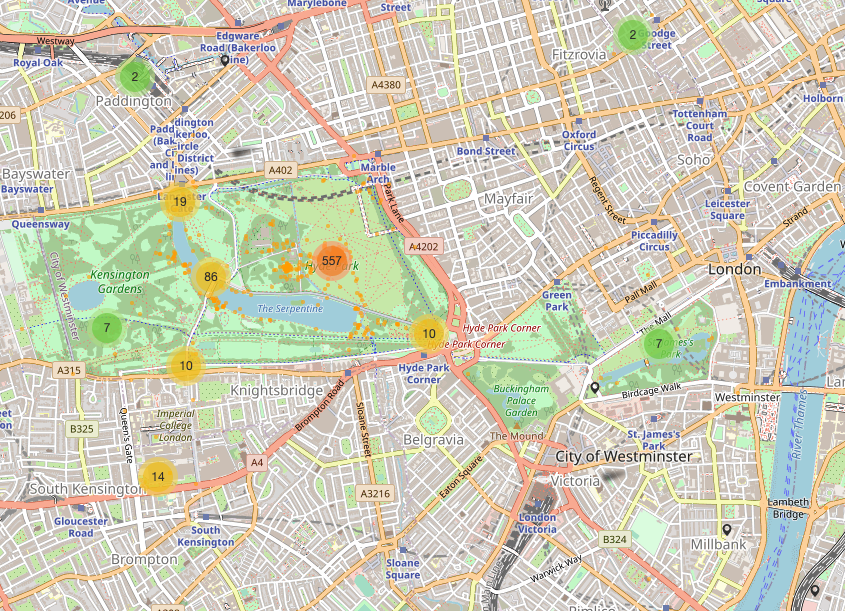 https://www.scieneers.de/wp-content/uploads/2021/10/london_2019.png
611
2305
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2021-10-12 09:21:422025-01-31 11:33:45User Behavior in iNaturalist’s City Nature Challenges
https://www.scieneers.de/wp-content/uploads/2021/10/london_2019.png
611
2305
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2021-10-12 09:21:422025-01-31 11:33:45User Behavior in iNaturalist’s City Nature Challenges https://www.scieneers.de/wp-content/uploads/2021/09/ian-schneider-TamMbr4okv4-unsplash-2-scaled.jpg
1709
2560
Lena Beck
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Lena Beck2021-09-27 16:30:582025-01-31 11:34:06Wie finde ich eine zu mir passende Stelle?
https://www.scieneers.de/wp-content/uploads/2021/09/ian-schneider-TamMbr4okv4-unsplash-2-scaled.jpg
1709
2560
Lena Beck
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Lena Beck2021-09-27 16:30:582025-01-31 11:34:06Wie finde ich eine zu mir passende Stelle? https://www.scieneers.de/wp-content/uploads/2021/06/Sascha-Goetz-Realtime-Data-Integration-mit-Azure-Logic-Apps-und-Azure-Service-Bus.jpg
720
1280
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-06-18 15:46:392025-01-31 11:34:43Realtime Data Integration mit Azure Service Bus & Azure Logic Apps & Dataverse
https://www.scieneers.de/wp-content/uploads/2021/06/Sascha-Goetz-Realtime-Data-Integration-mit-Azure-Logic-Apps-und-Azure-Service-Bus.jpg
720
1280
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-06-18 15:46:392025-01-31 11:34:43Realtime Data Integration mit Azure Service Bus & Azure Logic Apps & Dataverse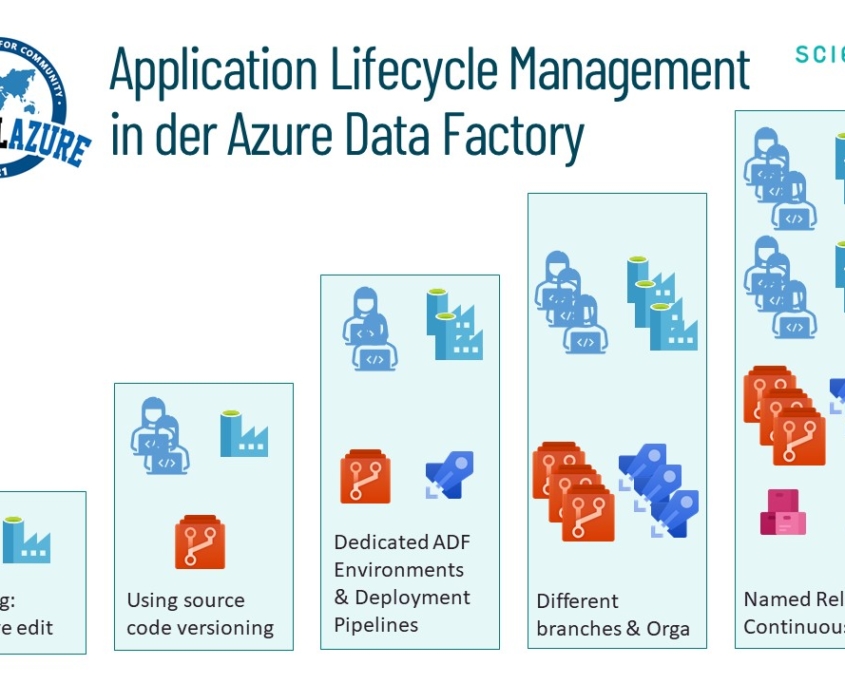 https://www.scieneers.de/wp-content/uploads/2021/06/Global-Azure-Application-Lifecycle-Management-in-Azure-Data-Factory.jpg
720
1280
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-06-11 11:51:192025-01-31 11:35:06Application Lifecycle Management in der Azure Data Factory
https://www.scieneers.de/wp-content/uploads/2021/06/Global-Azure-Application-Lifecycle-Management-in-Azure-Data-Factory.jpg
720
1280
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-06-11 11:51:192025-01-31 11:35:06Application Lifecycle Management in der Azure Data Factory https://www.scieneers.de/wp-content/uploads/2021/03/enbw_cnn-1-scaled.jpg
1347
2560
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2021-03-03 09:47:072025-01-31 11:35:50Künstliche Intelligenz in der Betriebsoptimierung von erneuerbaren Erzeugungsanlagen bei der EnBW
https://www.scieneers.de/wp-content/uploads/2021/02/cloud-security-800x.jpg
533
800
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:52:512025-01-31 11:37:20Advanced security of PaaS based Azure data applications – from setup to ALM
https://www.scieneers.de/wp-content/uploads/2021/03/enbw_cnn-1-scaled.jpg
1347
2560
Florence Lopez
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Florence Lopez2021-03-03 09:47:072025-01-31 11:35:50Künstliche Intelligenz in der Betriebsoptimierung von erneuerbaren Erzeugungsanlagen bei der EnBW
https://www.scieneers.de/wp-content/uploads/2021/02/cloud-security-800x.jpg
533
800
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:52:512025-01-31 11:37:20Advanced security of PaaS based Azure data applications – from setup to ALM https://www.scieneers.de/wp-content/uploads/2021/01/data-eng-in-adf-800x300-1.png
302
800
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:51:112025-01-31 11:37:41Data engineering pattern in der Azure Data Factory
https://www.scieneers.de/wp-content/uploads/2021/01/data-eng-in-adf-800x300-1.png
302
800
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:51:112025-01-31 11:37:41Data engineering pattern in der Azure Data Factory https://www.scieneers.de/wp-content/uploads/2021/01/Talk-MS-Certified-Data-Monster.png
552
1290
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:49:452025-01-31 11:38:05Microsoft Certified Data Monster
https://www.scieneers.de/wp-content/uploads/2021/01/Talk-MS-Certified-Data-Monster.png
552
1290
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:49:452025-01-31 11:38:05Microsoft Certified Data Monster https://www.scieneers.de/wp-content/uploads/2021/02/jupyter-logo300x.png
300
300
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:45:512025-01-31 11:38:29Professionelles Arbeiten mit Jupyter Notebooks/Lab
https://www.scieneers.de/wp-content/uploads/2021/02/jupyter-logo300x.png
300
300
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 16:45:512025-01-31 11:38:29Professionelles Arbeiten mit Jupyter Notebooks/Lab https://www.scieneers.de/wp-content/uploads/2020/12/flyer-Five-shades-of-data-flow-640x360-1.png
360
640
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 14:36:592025-01-31 11:39:13Five shades of dataflow
https://www.scieneers.de/wp-content/uploads/2020/12/flyer-Five-shades-of-data-flow-640x360-1.png
360
640
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2021-02-09 14:36:592025-01-31 11:39:13Five shades of dataflow https://www.scieneers.de/wp-content/uploads/2021/01/IMG_6574-scaled.jpg
1455
2560
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2021-02-03 13:11:312025-01-31 11:27:03Daten-Grundlagenarbeit in Python
https://www.scieneers.de/wp-content/uploads/2021/01/IMG_6574-scaled.jpg
1455
2560
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2021-02-03 13:11:312025-01-31 11:27:03Daten-Grundlagenarbeit in Python https://www.scieneers.de/wp-content/uploads/2020/12/recap-2020-2.png
2953
4725
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-12-21 11:00:292025-01-31 11:27:23Ein kurzer Blick zurück
https://www.scieneers.de/wp-content/uploads/2020/12/recap-2020-2.png
2953
4725
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-12-21 11:00:292025-01-31 11:27:23Ein kurzer Blick zurück https://www.scieneers.de/wp-content/uploads/2020/12/imageedit_7_2581858440-scaled.jpg
1008
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2020-12-11 14:32:042025-01-31 11:28:02The political discourse on discrimination – how to use natural language processing for good
https://www.scieneers.de/wp-content/uploads/2020/12/imageedit_7_2581858440-scaled.jpg
1008
2560
Alexandra Wörner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Alexandra Wörner2020-12-11 14:32:042025-01-31 11:28:02The political discourse on discrimination – how to use natural language processing for good https://www.scieneers.de/wp-content/uploads/2020/08/cover.png
731
1500
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2020-08-19 12:00:062025-01-31 11:28:24AutoML – A Comparison of cloud offerings
https://www.scieneers.de/wp-content/uploads/2020/08/cover.png
731
1500
Nico Kreiling
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Nico Kreiling2020-08-19 12:00:062025-01-31 11:28:24AutoML – A Comparison of cloud offerings https://www.scieneers.de/wp-content/uploads/2020/07/shutterstock_129657923-scaled.jpg
2560
2558
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-07-15 14:37:202025-01-31 11:28:41Die scieneers community wächst!
https://www.scieneers.de/wp-content/uploads/2020/07/shutterstock_129657923-scaled.jpg
2560
2558
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-07-15 14:37:202025-01-31 11:28:41Die scieneers community wächst! https://www.scieneers.de/wp-content/uploads/2020/05/agence-olloweb-qfp4-Ud6Fyg-unsplash-scaled.jpg
1700
2560
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2020-05-13 09:17:592025-01-31 11:29:30Was ist die Microsoft Data Platform?
https://www.scieneers.de/wp-content/uploads/2020/05/agence-olloweb-qfp4-Ud6Fyg-unsplash-scaled.jpg
1700
2560
Stefan Kirner
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Stefan Kirner2020-05-13 09:17:592025-01-31 11:29:30Was ist die Microsoft Data Platform? https://www.scieneers.de/wp-content/uploads/2020/04/shutterstock_1044017923-scaled.jpg
1709
2560
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-04-28 12:00:252025-01-31 11:29:58Der Anfang ist gemacht.
https://www.scieneers.de/wp-content/uploads/2020/03/team-thumbnail-post.jpg
300
300
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-03-30 08:41:242025-01-31 11:30:27Hello World, wir sind die scieneers! Wir sind “driven by data”.
https://www.scieneers.de/wp-content/uploads/2020/04/shutterstock_1044017923-scaled.jpg
1709
2560
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-04-28 12:00:252025-01-31 11:29:58Der Anfang ist gemacht.
https://www.scieneers.de/wp-content/uploads/2020/03/team-thumbnail-post.jpg
300
300
Patrick Thoma
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png
Patrick Thoma2020-03-30 08:41:242025-01-31 11:30:27Hello World, wir sind die scieneers! Wir sind “driven by data”.