Lernen Sie Microsoft Fabric in unseren Webinaren kennen
Einführung
Unsere Termine
In unserem kostenfreien Webinar geben wir Sie eine Einführung in Microsoft Fabric und zeigen live, wie Sie mit Lakehouse, Dataflows und Power BI Dashboards arbeiten.
In unserem kostenfreien Webinar erhalten Sie einen fundierten Einblick mit spannenden Live-Demos in die Erstellung von Echtzeit-Dashboards mit der Kusto Query Language (KQL).
Fast jedes Unternehmen betreibt Forschung und Entwicklung (R&D), um innovative Produkte auf den Markt zu bringen. Die Entwicklung innovativer Produkte ist naturgemäß risikobehaftet: da es um Produkte geht, die noch nie zuvor angeboten wurden, ist meistens unklar, ob und zu welchem Grad erwünschte Eigenschaften der Produkte realisierbar sind und wie genau sie sich realisieren lassen. Der Erfolg von R&D hängt also maßgeblich an der Gewinnung und Verwertung von Wissen über die Realisierbarkeit von Produkteigenschaften.
Scrum ist heute mit Abstand die beliebteste Form des agilen Projektmanagements1. Einige Hauptmerkmale von Scrum sind stetige Transparenz über den Produktfortschritt, Zielorientierung, einfache Abläufe, flexible Arbeitsweisen und effiziente Kommunikation. Scrum ist ein flexibles Rahmenwerk und beinhaltet nur eine Handvoll Aktivitäten und Artefakte2. Scrum lässt absichtlich offen, wie Backlog Items (BLIs) strukturiert sind, was die Definition of Done (DoD) von BLIs ist und wie genau derRefinement-Prozess ablaufen sollte. Diese Aspekte muss ein Scrum Team selbst steuern. Auch durch diese Flexibilität ist Scrum so erfolgreich: Scrum wird in einer Vielzahl von Domänen angewendet und dort mit domänenspezifischen Prozessen oder Artefakten ergänzt3.
Auch in R&D ist Scrum fest etabliert4. Wie oben beschrieben hängt der Erfolg eines R&D Scrum Teams davon ab, wie effizient das Team Wissen gewinnt und verwertet. Zur Wissensgewinnung haben sich im Scrum Kontext sogenannte Spikes etabliert. Spikes sind BLIs, in denen Wissen über die Machbarkeit und den Aufwand von Produkteigenschaften gewonnen wird, ohne die Eigenschaften zu realisieren. In diesem Post wollen wir aufzeigen, worauf es bei der Umsetzung von Spikes in Scrum ankommt und wie ein Scrum Team sicherstellen kann, dass das aus Spikes gewonnene Wissen optimal verwertet wird. Wir illustrieren diese Good Practices mit konkreten Beispielen aus 1,5 Jahren Scrum in einem Forschungsprojekt mit EnBW.
Eine breit etablierte Methode zur Wissensgewinnung in Scrum sind sogenannte Spikes– BLIs, in denen die Machbarkeit und der Aufwand von Produkteigenschaften eingeschätzt werden, ohne die Eigenschaften zu realisieren. Die Idee von Spikes entstammt dem eXtreme Programming (XP)5.
Die Wissensgewinnung durch Spikes dient dem Abbau von übermäßigem Risiko6. Der Anteil von Spikes am Backlog sollte also proportional zum aktuellen Risiko bei der Produktentwicklung sein. In einem R&D Scrum Team kann es viele offene Fragen und Risiken geben und Spikes können mehr als die Hälfte eines Sprints ausmachen, wie z.B. zeitweise im Google AdWords Scrum Team7. Ein übergroßer Anteil von Spikes hemmt allerdings die Produktivität eines Teams, weil zu viel Zeit mit Wissensgewinnung und zu wenig Zeit mit der Umsetzung des Produkts verbracht wird8. Die Priorisierung von Spikes gegenüber regulären BLIs ist also ein wichtiger Faktor für den Erfolg von R&D Scrum Projekten.
Ein weiterer wichtiger Faktor ist die Definition von Qualitätskriterien für Spikes. Konkret kann ein Scrum Team eine Definition of Ready (DoR) und eine Definition of Done (DoD) für Spikes etablieren. Die DoR legt fest, welche Kriterien ein Spike erfüllen muss, um bearbeitet zu werden; die DoD bestimmt welche Kriterien erfüllt sein müssen damit ein Spike abgeschlossen werden kann. Beide Definitionen beeinflussen die Qualität und Menge des erzeugten Wissens und dessen Verwertbarkeit im Scrum Prozess. Die DoD ist ein obligatorischer Bestandteil von Scrum. Die Einführung einer DoR liegt hingegen im Gestaltungsspielraum des Scrum Teams und ist auch nicht immer nützlich9.
Anlass für einen Spike ist fast immer ein akutes und konkretes Risiko bei der Produktentwicklung. Erkenntnisse aus einem Spike können aber über den konkreten Anlass des Spikes hinaus wertvoll sein und langfristig bei Entscheidungen in der Produktentwicklung helfen. Um eine Langzeitwirkung zu entfalten, müssen Erkenntnisse aus Spikes vom Team geeignet aufbewahrt werden.
Die Anwendung von Spikes in R&D Projekten wirft also mindestens drei Fragen auf:
Wie werden Spikes untereinander und gegenüber anderen BLIs priorisiert?
Wie werden DoR und DoD für Spikes formuliert?
Wie wird das in Spikes gewonnene Wissen aufbewahrt?
Die Literatur über Scrum lässt diese Fragen weitgehend offen. In einem mehrjährigen R&D Forschungsprojekt mit EnBW konnten wir verschiedenen Antworten auf die Fragen anwenden und damit Erfahrungen sammeln. Dabei haben wir zwei Good Practices entwickelt, die wir in diesem Blogpost vorstellen: (1) ein Regeltermin zur „Spike-Pflege“, d.h. zum Schärfen konkreter Hypothesen in Spikes und (2) ein leichtgewichtiges Laborbuchzur Protokollierung von Erkenntnissen. Die beiden Praktiken ergänzen wir außerdem durch eine passende DoR und DoD.
Good Practice: Regeltermin für die „Spike-Pflege“ im Backlog
Das Refinement ist eine fortlaufende Aktivität des gesamten Scrum Teams. Dabei werden BLIs aus dem Backlog für die Bearbeitung vorbereitet: BLIs werden präziser reformuliert, in unabhängige BLIs aufgeteilt und in konkrete Arbeitsschritte zerlegt. Viele Scrum Teams nutzen einen Regeltermin, um das Refinement gemeinsam durchzuführen und dabei ein gemeinsames Verständnis des Backlogs zu erlangen.
Unserer Erfahrung nach ist ein gemeinsames Refinement ein häufiger Entstehungsort für Spikes. Denn wenn das Team über das Backlog diskutiert, fallen ungeklärte Fragen und Risiken auf. Offene Risiken in einem BLI äußern sich oft darin, dass das Team Schwierigkeiten hat eine konkrete DoD festzulegen und dass die Aufwandsschätzungen der Teammitglieder stark auseinandergehen. Auch bestimmte Formulierungen von Teammitglieder können auf Risiken hinweisen, z.B.:
„Keine Ahnung, ob das geht.“
„Ich weiß noch nicht, wie ich das machen soll.“
„Da muss ich mich erstmal einlesen.“
Nach der Identifizierung eines Risikos muss das Team entscheiden, ob das Risiko so groß ist, dass es mit einem Spike reduziert werden sollte. Der Spike wird dann im Backlog als BLI-Entwurf angelegt. Um den regulären Refinement-Termin nicht zu sprengen, empfehlen wir, frisch angelegte Spikes nicht in diesem Termin zu refinen und zu priorisieren. Stattdessen empfehlen wir, dass sich das Team regelmäßig ein bis zwei Tage nach dem regulären Refinement trifft, um „Spike-Pflege“ zu betreiben. In der Zwischenzeit können die Spike-Entwürfe auch einzelnen Teammitgliedern zugeteilt werden, die diese dann für den Spike-Pflege-Termin vorbereiten, z.B. durch Sammlung konkreter Hypothesen und Ideen für Experimente.
Natürlich können Spikes auch außerhalb eines gemeinsamen Refinement Termins entstehen, z.B. während der Umsetzung eines BLIs. Auch dann bietet es sich an, die Spikes als Entwürfe zu sammeln und dann im nächsten Spike-Pflege-Termin nachzuschärfen. So geraten die Anlässe der Spikes nicht in Vergessenheit, führen aber auch nicht zu Scope Creep im aktuellen Sprint.
Im Spike-Pflege-Termin müssen die gesammelten Spikes schließlich refined und im Backlog priorisiert werden. Unserer Erfahrung nach haben die meisten Spikes einen direkten Bezug zu einem oder mehreren BLIs – nämlich die BLIs bei deren Umsetzung es akut Risiken gibt. In diesem Fall ist die Priorisierung einfach: man nutzt die bestehende Priorisierung der BLIs und fügt jeden Spike vor seinem zugehörigen BLI in die Liste ein.
Zur Aufbewahrung des gewonnenen Wissens aus Spikes schlagen wir einleichtgewichtiges Laborbuch vor. Das Laborbuch dokumentiert für jeden Spike folgende Aspekte in jeweils 1-2 Sätzen:
Problemstellung: Welches akute Risiko in der Produktentwicklung soll entschärft werden? Welche Fragen müssen dafür geklärt werden?
Hypothesen: Aufstellung möglichst konkreter Hypothesen, die sich entweder recherchieren oder experimentell prüfen lassen.
Erkenntnisse: Zusammenfassung der experimentellen Ergebnisse oder der Recherche.
Konsequenzen: Bedeutung der Erkenntnisse für das Produkt. Z.B. „Produkteigenschaft X kann mithilfe von Y erreicht werden, mit Z aber nicht.“
Relevante Links, z.B. zu detaillierten experimentellen Ergebnissen und BLIs
Entscheidend für den langfristigen Mehrwert des Laborbuchs sind dessen Vollständigkeit und Kompression. Vollständigkeit heißt, dass die Ergebnisse sämtlicher Spikes im Laborbuch landen; Kompression heißt, dass nur die wesentlichen Erkenntnisse und Konsequenzen für das Projekt kurz und knapp in das Laborbuch eingetragen werden. In dieser Qualität kann das Laborbuch als Nachschlagewerk in Diskussionen eingesetzt werden.
Im Projekt mit EnBW haben wir das Laborbuch als eine Wikiseite im Projektwiki des Teams umgesetzt. Die Einträge auf der Seite haben wir absteigend chronologisch sortiert, d.h. das Wissen aus den aktuellen Spikes stand ganz oben. Wir haben das Laborbuch ca. ein Jahr lang angewendet und konnten in dieser Zeit keinerlei Skalierungsprobleme wahrnehmen. Das Laborbuch genoss als Wissensquelle im Team ein hohes Ansehen und wurde regelmäßig in Diskussionen eingesetzt.
Kommen wir nun zu unserer letzten Empfehlung: einer konkreten Definition von DoR und DoD für Spikes, die auf die beiden vorigen Good Practices abgestimmt ist.
Die DoR legt fest, welche Kriterien Spikes erfüllen müssen, bevor sie in einen Sprint aufgenommen und bearbeitet werden können. Wie erwähnt ist die DoR nicht Teil von Scrum, sondern eine häufig genutzte Erweiterung. Manche Scrum Experten sehen die DoR kritisch, weil sie dazu führen kann, dass wichtige BLIs aus „Schönheitsgründen“ nicht in einen Sprint aufgenommen werden10. Wir schlagen deshalb einen Kompromiss vor: wichtige BLIs werden immer in den nächsten Sprint aufgenommen, aber die bearbeitende Person ist dafür verantwortlich, dass das BLI vor der Bearbeitung die DoR erfüllt. Das heißt, die Erfüllung der DoR-Kriterien ist der erste Arbeitsschritt jedes BLIs.
Unser Vorschlag der DoR für Spikes ist simpel: vor Bearbeitung eines Spikes muss der Laborbucheintrag des Spikes möglichst präzise vorausgefüllt werden. Insbesondere müssen die zu untersuchenden Hypothesen klar aufgelistet werden. Im Team mit EnBW haben wir gute Erfahrungen damit gemacht, dass ein Teammitglied vor Bearbeitung des Spikes selbst die Hypothesen formuliert und diese dann von einem anderen Teammitglied kritisch prüfen lässt. Wenn die Hypothesen vollständig, verständlich und klar definiert sind, kann die Bearbeitung des Spikes beginnen.
Der Laborbucheintrag gibt dem Spike einen Rahmen vor. Das ist vergleichbar zum bekannten test-driven development (TDD)in der Softwareentwicklung. Dort wird zuerst mit Unit Tests definiert, was die Software leisten soll, danach wird sie implementiert. Die Erstellung eines Laborbucheintrags vor jedem Spike könnte man analog als hypothesis-driven learning (HDL)bezeichnen: zuerst wird mit Hypothesen definiert, was gelernt werden soll, danach werden die Hypothesen untersucht.
Die Analogie zwischen TDD und HDL eignet sich auch um die Vorteile von HDL zu beschreiben. Genauso wie TDD einen stetigen Anreiz zur Reduktion der Softwarekomplexität setzt, setzt HDL einen Anreiz für einfache und zielgerichtete Experimente. Und genauso wie programmierte Tests in TDD einen Großteil der schriftlichen Dokumentation einer Software ersetzen, so ersetzen die Laborbucheinträge in HDL einen Großteil der schriftlichen Dokumentation des Wissens aus Spikes.
Mindestens so wichtig wie die DoR ist die DoD eines Spikes. Sie legt fest, welche Kriterien erfüllt sein müssen, damit der Spike abgeschlossen ist. Auch diese Kriterien lassen sich am Laborbucheintrag des Spikes festmachen. Konkret schlagen wir vor, dass ein Spike fertig ist, wenn alle im Laborbucheintrag gelisteten Hypothesen bestätigt oder verworfen sind, der Laborbucheintrag geschrieben ist und die Ergebnisse im Team kommuniziert wurden.
In diesem Blog-Post haben wir einen konkreten Vorschlag gemacht, wie man Spikes in R&D Scrum Projekten einsetzen sollte. Unser Vorschlag befähigt ein R&D Scrum Team dazu, die Realisierbarkeit von innovativen Produkteigenschaften einzuschätzen – rechtzeitig vor der Umsetzung des Produkts und mit angemessenem Aufwand.
Kern unseres Vorschlags sind zwei Good Practices, die sich in unseren eigenen R&D Scrum Projekten bewährt haben: erstens, ein Regeltermin zur Spike-Pflege und zweitens,ein leichtgewichtiges Laborbuch zur Protokollierung von Erkenntnissen. Wir haben gezeigt, wie sich beide Praktiken mithilfe einer simplen DoR und DoD in Scrum einbinden lassen.
Mit den beiden Good Practices befüllen wir eine Lücke in der Scrum Literatur: es gibt bisher kaum konkrete Praktiken zur Erstellung, Priorisierung, Qualitätssicherung und Langzeitverwertung von Spikes. Die vorgeschlagenen Good Practices sind simpel und allgemein genug, um für die meisten R&D Scrum Teams anwendbar und nützlich zu sein. Wir freuen uns, wenn sich andere Scrum Teams davon inspirieren lassen.
https://www.scieneers.de/wp-content/uploads/2025/02/as.png10241024Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2025-03-07 09:06:552025-03-14 12:57:03Mit Scrum erfolgreich sein in Forschung und Entwicklung
Microsoft Fabric ist eine vielseitige und leistungsstarke Plattform für aktuelle Daten- und Analyseanforderungen und genießt derzeit große Aufmerksamkeit bei unseren Kunden. Dabei begegnen wir ganz unterschiedlichen Bedürfnissen – abhängig von Unternehmensgröße, Datenkultur und dem jeweiligen Entwicklungs- und Analysefokus.
Kunden aus dem Power-BI-Umfeld profitieren insbesondere von der Erweiterung des Self-Service-Ansatzes: Über vertraute Weboberflächen und ohne spezialisierte Entwicklungsprogramme können selbst Fachabteilungen oder Enduser schnell in die Datenaufbereitung einsteigen.
Erfahrene Entwickler:innen und IT-Teams möchten hingegen sicherstellen, dass sie in Fabric nicht auf bewährte Abläufe, wie die Entwicklung in einer IDE, Versionsverwaltung via Git oder etablierte Test- und Rollout-Prozesse, verzichten müssen. Dabei stellt sich die Frage, wie zentrale Änderungen robust geprüft und einer Vielzahl von Usern zur Verfügung gestellt werden können.
In diesem Blogpost möchten wir einen Überblick über die Entwicklungs- und Kollaborationsmöglichkeiten sowie die verschiedenen Deployment-Szenarien in Fabric geben. Obwohl wir versuchen, einen allgemeinen Überblick darzustellen, arbeitet Microsoft aktuell mit Hochdruck an neuen Funktionen und Verbesserungen für Fabric, sodass sich technische Einzelheiten mit der Zeit ändern können. Der jeweils aktuelle Stand zur Entwicklung von Fabric ist in der offiziellen Dokumentation oder im Microsoft-Fabric-Blog zu finden.
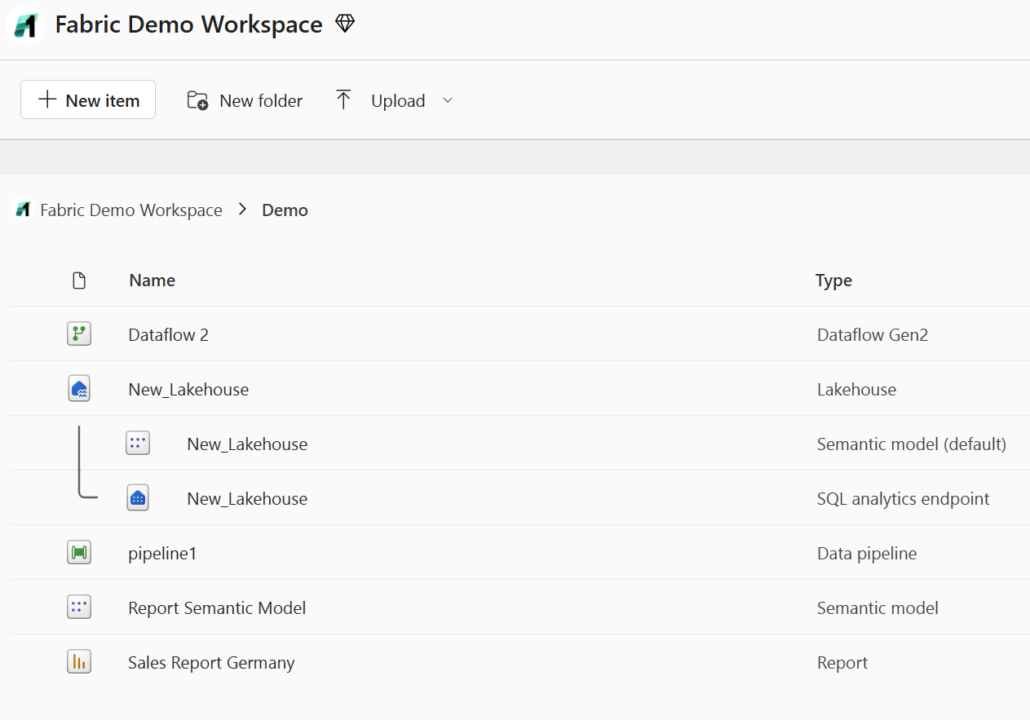
Fabric als Software-as-a-Service wird in der Regel direkt über den Browser bedient.
Wer bereits den Power BI Service kennt, findet sich dank des vertrauten Workspace-Konzepts sofort zurecht. Neue Fabric-Objekte wie Dataflows oder Data Pipelines lassen sich unkompliziert in der Weboberfläche erstellen und bearbeiten – eine lokale Entwicklungsumgebung oder zusätzliche Softwareinstallationen sind dafür nicht nötig.
Ein weiterer wesentlicher Vorteil der browserbasierten Entwicklung in Fabric ist die plattformunabhängige Nutzbarkeit unter Windows und macOS. Allerdings sind Entwicklungsumgebung im Browser allgemein weniger flexibel und anpassbar als eine vollständige Entwicklungsumgebung (IDE), da nur ein eingeschränkter Umfang an Tools und Integrationsmöglichkeiten zur Verfügung steht. Das ist auch in Bezug auf Fabric der Fall.
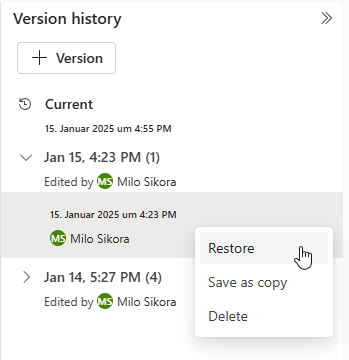
Änderungen an Fabric-Objekten sind sofort live und können direkt von anderen Usern gesehen und getestet werden, wodurch sich die Entwicklungszyklen deutlich beschleunigen. Allerdings bringt diese unmittelbare Sichtbarkeit auch Risiken mit sich: Fehler oder ungewollte Änderungen wirken sich sofort auf alle User aus und lassen sich nicht so einfach rückgängig machen wie in lokal gespeicherten Dateien.
Aus diesem Grund arbeitet Microsoft an einer integrierten Versionierung, inklusive Rollback-Funktionalität für verschiedene Fabric-Objekte. Für Notebooks ist diese Funktion bereits verfügbar, für semantische Modelle befindet sie sich aktuell in der Preview-Phase.
Trotz einiger Einschränkungen bei Flexibilität und Tool-Integration bietet die Weboberfläche damit einen schnellen, bequemen Einstieg in die Entwicklung und vereinfacht die Zusammenarbeit in verteilten Teams. Beispielsweise unterstützt die Notebook-GUI paralleles Arbeiten, einschließlich Kommentaren und Cursor-Highlighting, was Pair Programming, Remotedebugging oder auch Tutoren-Szenarien erleichtert.
Dieser Entwicklungsprozess ist vor allem für Szenarien geeignet, in denen eine isolierte Entwicklung nicht erforderlich ist und Änderungen direkt am Live-Stand vorgenommen werden können – beispielsweise für Enduser in nicht-technischen Fachabteilungen oder weniger kritische Anwendungsfälle.
Benötigt man hingegen eine dedizierte Umgebung, um neue Funktionen oder Anpassungen zu testen, ohne den Live-Stand zu beeinflussen, stehen grundsätzlich zwei Ansätze zur Verfügung.
2. Isolierte Entwicklung mittels lokaler Client-Tools
Für verschiedene Fabric-Objekte stehen Client-Tools zur Verfügung, die auf einem Rechner installiert werden können und mit denen sich diese Objekte lokal bearbeiten lassen. Meist wird dazu eine lokale Kopie des Fabric-Objekts erzeugt, diese wird bearbeitet und nach Fertigstellung aller Änderungen wieder in den Fabric Workspace hochgeladen.
Power-BI-User kennen diesen Ablauf bereits: Ein Power-BI-Report aus Fabric kann als .pbix-Datei heruntergeladen und mit Power BI Desktop lokal bearbeitet werden. Die Änderungen am Report werden in Fabric erst sichtbar, wenn man die lokalen Änderungen veröffentlicht. Vergleichbar läuft das Bearbeiten von Fabric-Notebooks ab, welche als .ipynb-Datei exportiert und lokal mit den präferierten Entwicklungstools bearbeitet werden können. Für VS Code gibt es eine Erweiterung (derzeit noch unter dem Namen „Synapse“) die diesen Prozess vereinfacht.
Hat man diese VS-Code-Erweiterung installiert, kann man direkt über einen Button in der Fabric-GUI eine lokale Kopie des gewünschten Notebooks erzeugen und in VS Code öffnen.
So arbeitet man in einer gewohnten Entwicklungsumgebung. Bei Bedarf kann man den Code über die fabric-spark-runtime sogar auf der Fabric-Kapazität ausführen lassen und damit große Datenmengen verarbeiten. Sobald alle Änderungen am Notebook erfolgt sind, lädt man die angepasste Version einfach wieder über das VS-Code-Plugin in den Fabric Workspace hoch – inklusive praktischer Diff-Funktion, um Unterschiede gegenüber der Version im Fabric Workspace anzuzeigen.
Darüber hinaus kann auch in anderen Bereichen mit lokalen Tools auf die Fabric-Umgebung zugegriffen werden. Beispielsweise lassen sich VS Code oder SQL Server Management Studio verwenden, um SQL-Abfragen zu schreiben oder Views zu definieren. Besonders das Fabric Warehouse ist aktuell gut in diese Tools integriert, eine Verbindung ist grundsätzlich aber mit allen SQL-basierten Fabric-Objekten möglich.
Die vorgestellten Funktionen sind ohne eine Anbindung des Fabric-Workspaces an ein Git-Repository nutzbar. Damit eignet sich dieser Prozess besonders für User, die eine isolierte Entwicklungsumgebung benötigen, jedoch noch keine Erfahrung mit Git haben oder deren Workspaces aus organisatorischen Gründen (noch) nicht an ein Git-Repository angebunden sind.
Für erfahrene Entwickler:innen ist eine Git-Integration jedoch ein zentraler Baustein professioneller Entwicklungsprozesse. Aus diesem Grund bietet Microsoft Fabric auch eine native Integration in Azure DevOps und GitHub.
Einschub: Fabric Git-Integration
Microsoft Fabric ermöglicht es, einen Workspace mit einem Azure DevOps- oder GitHub-Repository zu verbinden, um die Vorteile eines Git -integrierten Entwicklungsprozesses, wie beispielsweise die Versionierung, zu nutzen. Eine ausführliche Erläuterung aller Funktionen und Einschränkungen dieser Funktionalität findet sich hier.
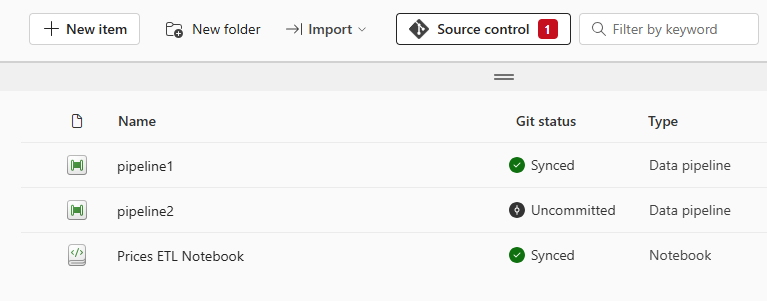
Ist ein Workspace an ein Repository angebunden, kann jederzeit der Git-Status der einzelnen Fabric-Objekte eingesehen werden. Änderungen an Objekten oder das Erstellen neuer Objekte können direkt aus der GUI heraus committet und in dem Repository gespeichert werden. Dadurch ist sicher gestellt, dass versehentlich gelöschte Objekte jederzeit wiederhergestellt werden können.
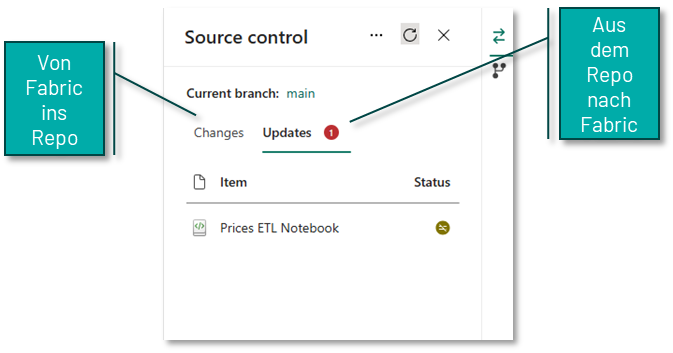
Es ist wichtig zu verstehen, dass diese Synchronisation zwischen Fabric und dem Repository in beide Richtungen erfolgen kann. Es können also Änderungen aus Fabric in das Repository gesichert werden und ebenso Änderungen an den Objekten im Repository (z.B. wenn ein Notebook direkt im Repository bearbeitet wurde) zurück in den Fabric Workspace importiert werden.
Wenn der Fabric Workspace Git-integriert ist, eröffnet das weitere Möglichkeiten, lokal mit verschiedenen Fabric-Elementen zu arbeiten. Durch das Klonen des entsprechenden Repositories kann man alle bekannten Git-Features nutzen, wie zum Beispiel lokale Feature-Branches oder einzelne Commits für wichtige Zwischenstände.
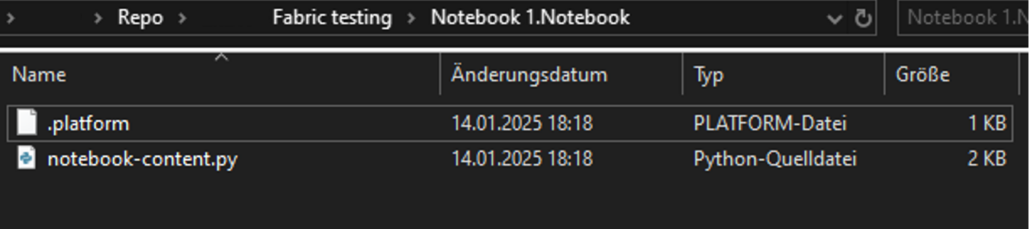
Ein Nachteil dabei ist jedoch, dass einzelne Fabric-Objekte im Repository in Formaten gespeichert werden, die primär auf eine Git-optimierte Speicherung und nicht auf eine komfortable Bearbeitung ausgelegt sind. Notebooks werden beispielsweise nicht als .ipynb-Dateien gespeichert, sondern als reine .py-Dateien, ergänzt durch eine zusätzliche .platform-Datei, die wichtige Metadaten enthält. Das kann das lokale Arbeiten mit Branches im Repository erschweren.
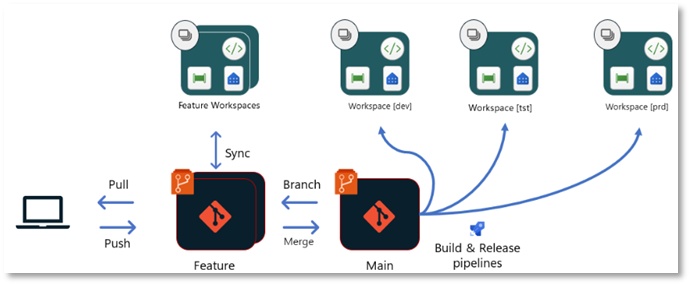
3. Isolierte Entwicklung in Feature-Branch Workspaces
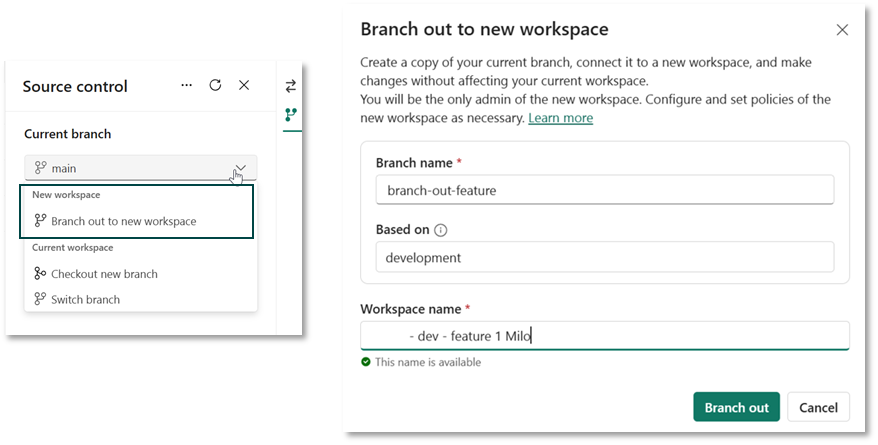
Um eine isolierte Entwicklungsumgebung zu erreichen, muss man in Fabric nicht zwangsläufig auf lokale Tools ausweichen. Fabric bietet – vorausgesetzt, der Workspace ist Git-integriert – auch native Möglichkeiten. Besonders interessant ist hierbei die Funktion “Branch out to a new feature-workspace”, die hier näher beschrieben wird.
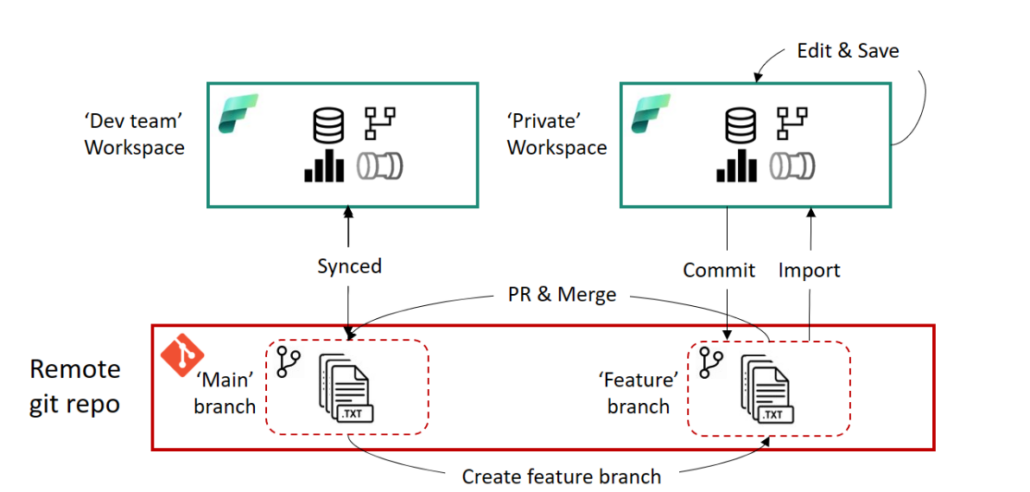
Nutzt man dieses Feature, wird eine Kopie des Workspaces erstellt, auf den zunächst nur man selber Zugriff hat. In diesem kann man isoliert entwickeln, ohne die Funktionalität der Objekte im eigentlichen Workspace zu beeinflussen. Im Hintergrund passiert Folgendes:
Es wird ein neuer, leerer Workspace mit dem definierten Namen angelegt.
In diesen Branch wird der Inhalt des aktuellen Workspaces kopiert.
Im Repository wird ein neuer Branch angelegt, dessen Namen ebenfalls bestimmt werden kann.
Im neu angelegten Workspace werden die Fabric-Objekte basierend auf dem neu angelegten Branch erstellt.
Man kann nun isoliert an den Fabric-Objekten arbeiten und die Änderungen in den neuen Branch committen, beispielsweise wenn man an einem Notebook weiterentwickeln möchte. Wichtig hierbei ist, dass Daten (z.B. in einem Lakehouse) nicht im Repository gespeichert werden und somit auch nicht in dem neuen Workspace zur Verfügung stehen. Das bedeutet, ein Notebook verbindet sich weiterhin mit dem Lakehouse in dem eigentlichen Workspace, wenn dieses im Notebook als Datenquelle genutzt wurde.
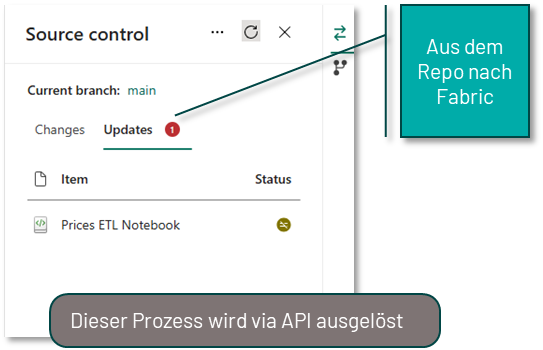
Hat man alle Änderungen in dem Feature-Workspace durchgeführt, muss man diese Änderungen noch zurück in den eigentlichen Workspace übertragen. Dieser Prozess erfolgt primär in Azure DevOps bzw. GitHub und setzt ein grundlegendes Verständnis von Git voraus. Man erstellt hierfür einen Pull-Request (PR), um den Feature-Branch in den Main-Branch des eigentlichen Workspaces zu mergen. Hierbei stehen alle gewohnten Funktionalitäten von DevOps und GitHub zur Verfügung, wie z.B. das Taggen von Reviewern. Ist der PR erfolgreich abgeschlossen, hat der Main-Branch im Repository einen aktuelleren Stand als die Fabric-Objekte im Workspace selbst. Abschließend muss der Stand aus dem Repository also noch in den Workspace übertragen werden. Hierfür kann man den oben beschriebenen Prozess des Updates im Source Control Panel des Fabric Workspaces nutzen oder diesen Prozess via API automatisieren.
Das folgende Diagramm veranschaulicht diesen Prozess.
Dieser Entwicklungsprozess bietet die umfassenden Vorteile einer Git-basierten Entwicklung und lässt sich bei Bedarf zusätzlich mit lokalen Client-Tools ergänzen. So ist es beispielsweise möglich, die Notebooks im Feature-Workspace über den oben beschriebenen Prozess in VS Code zu öffnen.
Dennoch bringt dieser Prozess auch einige Nachteile mit sich. Da Pull-Requests und Merges in Azure DevOps bzw. GitHub durchgeführt werden, setzt dieser Prozess Erfahrung im Umgang mit Git sowie Azure DevOps oder GitHub voraus. Außerdem müssen User, die dieses Feature in Fabric nutzen möchten, die Berechtigung haben, Workspaces zu erstellen, was zunächst von einem Administrator freigegeben werden muss. Zum aktuellen Zeitpunkt werden die Feature-Workspaces zudem nicht automatisch gelöscht, nachdem ein erfolgreicher Merge in den Ausgangs-Workspace durchgeführt wurde. Dies kann dazu führen, dass sich im Laufe der Zeit einige nicht mehr benötigte Workspaces ansammeln, wenn diese nicht manuell gelöscht werden.
Deployment Prozesse
Ein weiterer Schritt zur Professionalisierung des Einsatzes von Microsoft Fabric besteht darin, Workloads in mehreren Umgebungen bzw. Environments zu betreiben. In der Regel wird zwischen einer Entwicklungsumgebung (Dev.) und einer Produktivumgebung (Prod.) unterschieden. Dies ermöglicht es, den Workload in der Entwicklungsumgebung isoliert und iterativ weiterzuentwickeln, während die Enduser in der Produktivumgebung jederzeit eine funktionierende und gut dokumentierte Version des Workloads vorfinden.
Sobald ein zufriedenstellender Punkt im Entwicklungsprozess erreicht ist, wird der Entwicklungsstand von der Entwicklungsumgebung in die Produktivumgebung übertragen. Dieser Vorgang wird als Deployment-Prozess bezeichnet. Microsoft Fabric bietet hierfür verschiedene Möglichkeiten.
1. Fabric Deployment Pipelines
Die einfachste Möglichkeit, einen Deployment-Prozess in Fabric zu integrieren, sind die sogenannten Fabric Deployment Pipelines. Sie sind fester Bestandteil von Fabric und benötigen kein weiteres Tooling – um sie zu benutzen, muss der Entwicklungs-Workspace nicht einmal mit einem Git-Repository verknüpft sein.
Für jede Umgebung wird ein Workspace angelegt, und anschließend wird in dem Entwicklungs-Workspace eine Deployment Pipeline aufgesetzt. Über ein übersichtliches Interface definiert man, welche Fabric-Objekte vom Ausgangs-Workspace (in der Darstellung unten „Development“) in den Ziel-Workspace (in unserem Fall „Test“) übertragen werden sollen, und klickt auf „Deploy“.
Da sich unterschiedliche Umgebungen in der Regel in ihren Eigenschaften unterscheiden – beispielsweise in der Datenbank, auf die sie zugreifen – lassen sich für jedes Fabric-Objekt sogenannte Deployment-Rules definieren. Diese stellen sicher, dass diese Eigenschaften während des Deployment-Prozesses entsprechend angepasst werden.
Zum aktuellen Zeitpunkt sind diese Deployment-Rules jedoch noch nicht für alle Fabric-Objekte einsetzbar und unterstützen nur eine vordefinierte Auswahl an Eigenschaften, die angepasst werden können. So kann man beispielsweise in einem Fabric-Notebook keine zuvor im Code definierten Parameterwerte austauschen.
Insgesamt bieten die Fabric Deployment Pipelines einen einfachen Einstieg in die Entwicklung mit mehreren Umgebungen, ohne dass tiefgreifende Erfahrung mit Git notwendig ist. Sie eignen sich besonders für Workloads, die beispielsweise von nicht-technischen Fachabteilungen verwaltet werden, und stellen eine logische Erweiterung des Self-Service-Prinzips dar.
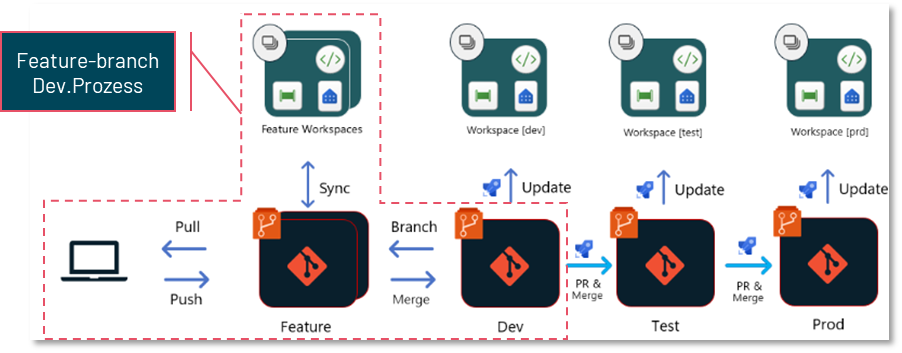
2. Branch-based Deployment
Die zweite Möglichkeit, einen Deployment-Prozess in Fabric umzusetzen, erfordert, dass alle Workspaces, die eine bestimmte Umgebung darstellen (z.B. Dev., Test. und Prod.), mit verschiedenen Branches desselben Git-Repositories verknüpft sind. Die Funktionsweise des branch-basierten Deployments ähnelt dem Feature-Branch-Entwicklungsprozess, der im folgenden Diagramm gekennzeichnet ist. Grundsätzlich ist der branch-basierte Deployment-Prozess jedoch mit allen Entwicklungsprozessen kombinierbar, solange eine Git-Integration eingerichtet ist.
Dieser Prozess nutzt die Funktionalität von Azure DevOps Pipelines (bzw. GitHub Actions), die automatisch auf Änderungen in Repository-Branches reagieren und bestimmte Prozesse anstoßen können.
Sobald ein neuer Entwicklungsstand in der Entwicklungsumgebung (Dev.) entwickelt wurde und bereit für das Deployment ist, wird im Repository ein Pull-Request (PR) in einen Test-Branch eröffnet. In diesem Branch können Reviewer die neuen Änderungen überprüfen und freigeben.
Nach der Freigabe und Aktualisierung des Test-Branches wird automatisch eine DevOps-Pipeline gestartet, die verschiedene Aktionen auf den Objekt-Definitionen in diesem Branch ausführt. Diese Pipeline kann beispielsweise Umgebungsparameter (wie Datenbankverbindungen) anpassen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht.
Der angepasste Code wird dann in einem weiteren Branch, wie z.B. Test-Release, gespeichert. Dieser Test-Release-Branch ist mit dem Test-Workspace in Fabric verbunden. Eine zweite Pipeline reagiert auf die Aktualisierung dieses Branches und sorgt über eine API dafür, dass der Stand aus diesem Branch in den Fabric-Workspace übertragen wird.
Im Test-Workspace können anschließend direkt in Fabric weitere Tests, wie Data-Quality-Tests, durchgeführt werden, bevor der Code über einen analogen Prozess in den produktiven Workspace übertragen wird.
Diese Form des Deployment-Prozesses erfordert neben dem Verständnis von Git auch Erfahrung im Aufsetzen von Azure DevOps Pipelines bzw. GitHub Actions und ist daher für erfahrene Entwickler:innen und kritische Workloads konzipiert. Die Verwendung professioneller Deployment-Tools bietet dann jedoch die volle Flexibilität in der Ausgestaltung des Deployment-Prozesses und der Integration erweiterter Schritte wie Code-Testing.
Die Arbeit mit dedizierten Branches pro Umgebung erlaubt außerdem das einfache Handling verschiedener Versionen in den einzelnen Umgebungen sowie das schnelle Zurückrollen auf vorherige Stände.
3. Release-Pipeline Deployment
Eine weitere Möglichkeit für ein Deployment in Fabric besteht darin, die einzelnen Workspaces nicht direkt über die integrierten Möglichkeiten mit einem Branch in einem Repository zu verbinden, sondern ausgehend von einem geteilten Main-Branch über Build- und Release-pipelines direkt in die einzelnen Workspaces zu deployen.
Bei diesem Ansatz kann – wie im vorherigen Prozess auch – eine Build-Pipeline je nach Zielumgebung Umgebungsparameter (wie Datenbankverbindungen) austauschen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht. Das Ergebnis wird in diesem Ansatz jedoch nicht in einem eigenen Branch gespeichert, sondern beispielsweise als Artefakt an eine Release-Pipeline übergeben. Diese nutzt dann die Fabric Item API, um die jeweiligen Fabric-Objekte oder Änderungen in den Ziel-Workspace zu deployen.
Um die Interaktion mit der Fabric API zu vereinfachen, können Libraries wie die fabric-cicd Python Library verwendet werden.
Genau wie das Branch-based Deployment erfordert dieser Ansatz Erfahrung im Umgang mit Azure DevOps Pipelines, erlaubt deshalb aber auch die volle Flexibilität in der genauen Ausgestaltung des Deploymentprozesses.
Fazit
In diesem Artikel haben wir die gängigsten Entwicklungs- und Deploymentprozesse in Microsoft Fabric exemplarisch vorgestellt. Gerade innerhalb der Deploymentprozesse über Azure DevOps bzw. Github besteht in der konkreten Ausgestaltung aber natürlich die volle Flexibiltät, diese genau auf die eigenen Bedürfnisse anzupassen. Es ist außerdem nicht notwendig sich bei allen Workloads, die auf Fabric abgebildet werden sollen, für einen einzigen Entwicklungs- oder Deploymentprozess zu entscheiden. Die Wahl des passenden Prozesses sollte stets auf die spezifischen Anforderungen und den jeweiligen Workload abgestimmt sein. So ist es sinnvoll einen professionellen Deploymentprozess für zentrale Datenprodukte wie z.B. ein unternehmensweites Datawarehouse zu wählen, während für einzelne Fachbereiche evtl. ein Deployment über Deployment Pipelines ausreicht, oder sogar komplett auf Deploymentprozesse verzichtet werden kann.
Wer noch mehr Tipps und Tricks zu Microsoft Fabric erfahren möchte, sollte einen Blick in unseren Microsoft Fabric Kompakteinführung Workshop werfen!
Verbreiter:innen von Desinformation nutzen verschiedene Strategien, um falsche Aussagen authentisch wirken zu lassen. Um effektiv dagegen vorzugehen und die Glaubwürdigkeit solcher Desinformationen zu mindern, ist es entscheidend, dass die Betroffenen nicht nur die Desinformation als solche erkennen, sondern auch die verwendeten irreführenden rhetorischen Strategien durchschauen.
In unserer heutigen Zeit ist dies wichtiger denn je: Ob in sozialen Medien oder bei Familienfeiern, täglich sind wir einer Flut von Informationen und Meinungen ausgesetzt. Oftmals entscheiden wir in Bruchteilen von Sekunden, ob wir diese als wahr oder fragwürdig einstufen. Die Kenntnis häufig verwendeter rhetorischer Strategien stärkt die Intuition und fördert kritisches Hinterfragen bei zweifelhaften Argumentationen.
Aus diesem Grund haben wir den DesinfoNavigator entwickelt – ein Tool, das Menschen dabei unterstützt, Desinformationen zu erkennen und zu entkräften. Mit dem DesinfoNavigator können Nutzer:innen Textauszüge auf irreführende rhetorische Strategien prüfen und erhalten zugleich Anleitungen, wie sie die Textstellen bezüglich dieser Strategien untersuchen können.
Für die Analyse dieser Strategien verwenden wir im DesinfoNavigator das PLURV-Framwork, welches folgende fünf Kategorien umfasst: Pseudo-Expert:innen, logische Trugschlüsse, unerfüllbare Erwartungen, Rosinenpickerei und Verschwörungsmythen.
In der technischen Umsetzung nutzt der DesinfoNavigator ein großes Sprachmodell (engl. Large Language Model, LLM). Im ersten Schritt analysiert das Tool die Eingaben der Nutzer:innen auf mögliche rhetorische Strategien gemäß des PLURV-Frameworks. Dabei erhält das Sprachmodell neben der Nutzereingabe auch eine detaillierte Beschreibung der Strategien inklusive Beispiele. Als Resultat liefert das Modell Textstellen, bei denen Hinweise auf eine der Strategien vorliegen. Im zweiten Schritt generiert das Sprachmodell für jede identifizierte Textstelle eine Handlungsanweisung, die Anleitungen gibt, wie man die Textstelle hinsichtlich der Strategie überprüfen kann.
Es ist wichtig zu betonen, dass der DesinfoNavigator keine klassischen Faktenchecks durchführt; er analysiert vielmehr, ob und welche rhetorischen Strategien möglicherweise in einem Text verwendet werden. Wir verstehen den DesinfoNavigator somit als logische Ergänzung zu bisher existierenden Faktenchecking-Tools.
Um den größtmöglichen gesellschaftlichen Nutzen zu erzielen, haben wir uns dazu entschieden, den DesinfoNavigator kostenlos und frei zugänglich zu machen. Dies ermöglicht es einem breiten Publikum, sich aktiv mit der Erkennung und Bekämpfung von Desinformation auseinanderzusetzen.
Neugierig geworden? Der DesinfoNavigator kann aktuell unter https://desinfo-navigator.de/ ausprobiert werden. Wir freuen uns über hilfreiche Rückmeldungen sowie über interessierte Kooperationspartner:innen, die uns helfen möchten, den DesinfoNavigator weiterzuentwickeln und einer breiteren Öffentlichkeit zugänglich zu machen.
Indem wir den DesinfoNavigator kontinuierlich weiterentwickeln und verbessern, streben wir danach, einen bedeutenden Beitrag im Kampf gegen die Verbreitung von Desinformation zu leisten. Unser Ziel ist es, ein stärkeres Bewusstsein für einen kritischen Umgang mit der alltäglichen Informationsflut zu schaffen und zu fördern.
Autoren
Dr. Clara Christner
Kommunikationswissenschaftlerin mit Forschungsschwerpunkt Desinformationen
Bei der Wahl eines Arbeitgebers geht es heute nicht nur um den Job selbst, sondern auch um die Werte und Leistungen, die das Unternehmen bieten kann.
Für uns ist es wichtig, dass unsere Mitarbeitenden nicht nur einen Arbeitsplatz finden, sondern auch eine Umgebung, in der sie sich wohlfühlen und entfalten können.
Deshalb legen wir großen Wert darauf, um ein Arbeitsumfeld zu schaffen, das sowohl die berufliche als auch die persönliche Entwicklung fördert.
Unsere Leistungen sind so gestaltet, dass sie das Beste aus beiden Welten bieten. Eine Unternehmenskultur, die auf Transparenz, Inklusion und Nachhaltigkeit setzt und Benefits, die begeistern und Gründe sind, Teil unseres Teams zu werden.
Hier ein Überblick über die Benefits, die dich bei uns erwarten:
1. Tolle Büros & weitreichende Home-Office-Möglichkeit
Wir wissen, wie wichtig Flexibilität im Arbeitsalltag ist. Wir vertrauen darauf, dass unsere Mitarbeitenden selbst am besten wissen, wo und wann sie am besten produktiv arbeiten können.
Ob man den Austausch in einem modernen Büro sucht oder mal in Ruhe im Home-Office arbeiten möchte – bei uns ist beides möglich.
Dafür haben wir drei schöne Büros mit guter Anbindung in Hamburg, Köln und Karlsruhe.
Mit unseren weitreichenden Home-Office-Möglichkeiten bieten wir unseren Mitarbeitenden außerdem die Möglichkeit, ihren Arbeitstag so zu gestalten, dass er optimal zu ihrem individuellen Lebensstil passt.
Office in KölnOffice in KarlsruheOffice in Hamburg
Aus diesem Grund möchten wir unsere Mitarbeitenden dabei unterstützen, Familie und Beruf unter einen Hut zu bringen.
Dafür bieten wir neben flexiblen Arbeitszeiten auch einen Kita-Zuschuss. So möchten wir die Vereinbarkeit von Beruf und Familie erleichtern.
3. Mitarbeiter-Events und Office-Lunches
Ob gemeinsames Essen, sportliche Aktivitäten oder kulturelle Erlebnisse – unser Ziel ist es, eine Arbeitsatmosphäre zu schaffen, in der der Teamgeist und der Austausch zwischen unseren Teammitgliedern im Vordergrund stehen.
Mit regelmäßigen Mitarbeiter-Events, Office-Lunches und weiteren gemeinsamen Aktivitäten fördern wir aktiv den Austausch und stärken den Zusammenhalt im Team.
Auch Erfolge und Feste feiern wir gerne gemeinsam – auf unsere regelmäßigen Zusammenkünfte an wechselnden Orten sowie auf unsere Weihnachtsfeier freuen sich unsere Mitarbeitenden jedes Jahr erneut.
4. Weiterbildungsbudget & Mentoring
Die Technologiebranche ist schnelllebig – entsprechend ist die persönliche Fortbildung ein entscheidender Faktor. Aus diesem Grund bieten wir jedem Mitarbeitenden ein individuelles Fortbildungsbudget, das sie frei in seine Weiterentwicklung investieren kann – egal ob mit Büchern, Online-Kursen, Fortbildungen oder ganz eigenen Ideen.
Die persönliche Weiterentwicklung beschränkt sich aber natürlich nicht nur auf fachliche Kompetenzen. Mit unserem Mentoring-Programm sorgen wir dafür, dass neue Mitarbeitende sich schnell einfinden. Darüber hinaus begleiten wir sie auch langfristig durch regelmäßige Feedbackgespräche und jährliche Rückblicke.
Erfolg ist ein Gemeinschaftsprojekt und unsere Mitarbeitenden ermöglichen diesen. Mit der Mitarbeiterbeteiligung sorgen wir dafür, dass sich Engagement auch langfristig auszahlt und dass sie direkt davon profitieren können.
Für eine sichere Zukunft sorgen wir gemeinsam mit unseren Mitarbeitenden vor. Wir denken mit und unterstützen finanziell bei der betrieblichen Altersvorsorge.
6. Moderne Hardware nach Wahl – die privat genutzt werden kann
Egal ob Mac, Windows oder Linux – unsere Mitarbeitenden entscheiden selbst, mit welcher Hardware sie arbeiten möchten. Dazu gehört natürlich auch ein aktuelles Smartphone mit entsprechendem Telekom-Vertrag zur Standardausstattung unserer Mitarbeitenden.
Unsere Mitarbeitenden können die moderne Hardware ihrer Wahl auch privat nutzen. Wir sorgen dafür, dass es ihnen an nichts fehlt, um produktiv und kreativ zu sein.
7. Job-Ticket, Job-Rad und Firmenwagen-Leasing
Mobilität wird leicht gemacht: Ob mit dem Job-Ticket, dem Job-Rad oder über unser Firmenwagen-Leasing – wir unterstützen alle Mitarbeitenden dabei, mobil und nachhaltig unterwegs zu sein, egal wie sie zur Arbeit kommen möchten.
8. Sportzuschuss
Mit unserem Sport-Zuschuss bei der Mitgliedschaft im Urban Sports Club unterstützen wir alle Mitarbeitenden, die daran interessiert sind, aktiv zu bleiben.
9. Inklusion, Transparenz und Nachhaltigkeit als Firmenwerte
Bei scieneers setzen wir auf eine offene Unternehmenskultur, in der alle willkommen sind. Inklusion, Transparenz und Nachhaltigkeit sind die Werte, die wir aktiv leben.
Wir schaffen ein Arbeitsumfeld, das Vielfalt und Diversität feiert und jedem eine Stimme gibt. Deshalb haben wir als Unternehmen die Charta der Vielfalt unterzeichnet.
Bereit, Teil unseres Teams zu werden?
Unsere Benefits sind nur ein Teil dessen, was scieneers so besonders macht.
Wenn Du eine offene und moderne Unternehmenskultur suchst, die Dich unterstützt und fördert, dann freuen wir uns darauf, von Dir zu hören.
Entdecke unsere aktuellen Stellenangebote und finde heraus, wie Du bei uns durchstarten kannst!
https://www.scieneers.de/wp-content/uploads/2025/01/L1021346-1210x423-1.jpg8442420Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2025-01-31 08:52:002025-03-17 09:15:27Benefits bei scieneers
Jeder kennt ChatGPT – ein Chatbot, der Antworten auf fast jede Frage liefert. Doch in vielen Firmen ist die Nutzung offiziell noch nicht erlaubt oder wird nicht bereitgestellt. Dabei kann ChatGPT komplett datenschutzkonform und sicher betrieben werden und Mitarbeitenden einen einfachen Zugang zu internem Firmenwissen ermöglichen. Basierend auf Erfahrungen aus zahlreichen Retrieval-Augmented Generation (RAG)-Projekten haben wir ein modulares System entwickelt, das speziell auf die Bedürfnisse mittelständischer Unternehmen und Organisationen zugeschnitten ist. In diesem Beitrag stellen wir unseren leichtgewichtigen und anpassbaren Chatbot vor, der einen datenschutzkonformen Zugriff auf Unternehmenswissen ermöglicht.
1. Eigene Wissensquellen nutzen
Der Kern unseres RAG-Systems liegt darin, dass ein LLM auf die unternehmensspezifische Wissensquellen zugreifen kann. Dem Chatbot können verschiedene Datenquellen zur Verfügung gestellt werden:
1. Nutzerspezifische Dokumente:
Mitarbeitende können eigene Dateien hochladen, z. B. PDF-Dokumente, Word-Dateien, Excel-Tabellen oder sogar Videos. Diese werden im Hintergrund verarbeitet und stehen nach kurzer Zeit dauerhaft zum Chatten zur Verfügung.
Der Verarbeitungsstatus ist jederzeit einsehbar, damit transparent bleibt, wann die Inhalte für Anfragen genutzt werden können.
Beispiel: Ein Vertriebsmitarbeitender lädt eine Excel-Tabelle mit Preisinformationen hoch. Das System kann daraufhin Fragen zu den Preisen spezifischer Produkte beantworten.
2. Globale unternehmensinterne Wissensquellen:
Das System kann auf zentrale Dokumente aus Plattformen wie SharePoint, OneDrive oder dem Intranet zugreifen. Diese Daten sind für alle Nutzenden zugänglich.
Beispiel: Ein Mitarbeitender möchte nach den Regelungen zur betrieblichen Altersvorsorge suchen. Da die entsprechende Betriebsvereinbarung zugänglich ist, kann der Chatbot die korrekte Antwort geben.
3. Gruppenspezifische Wissensquellen:
Es ist auch möglich, dass Informationen / Dokumente nur für spezifische Teams oder Abteilungen zugänglich gemacht werden.
Beispiel: Nur das HR-Team hat Zugriff auf Richtlinien zum Onboarding. Das System kann Fragen dazu nur HR-Mitarbeitenden beantworten.
Auch wenn Nutzende mit allen verfügbaren Datenquellen arbeiten, stellt das System im Hintergrund sicher, dass nur für eine Anfrage relevante Informationen genutzt werden, um Antworten zu generieren. Durch intelligente Filtermechanismen werden irrelevante Inhalte automatisch ausgeblendet.
Nutzende haben jedoch die Möglichkeit, explizit festzulegen, welche Wissensquellen berücksichtigt werden sollen. Sie können beispielsweise wählen, ob eine Anfrage auf aktuelle Quartalszahlen oder auf allgemeine HR-Richtlinien zugreifen soll. Dadurch wird vermieden, dass irrelevante oder veraltete Informationen in die Antwort einfließen.
2. Feedback-Prozess und kontinuierliche Verbesserung
Ein zentraler Bestandteil unserer RAG-Lösung ist die Möglichkeit, systematisch Feedback der Nutzenden zu erfassen, um die Qualität des Systems verbessern zu können, indem Schwachstellen identifiziert werden. Eine Schwachstelle könnten beispielsweise Dokumente mit uneinheitlichem Format darstellen, wie schlecht gescannte PDFs oder Tabellen mit mehreren verschachtelten Ebenen, die fehlerhaft interpretiert werden.
Nutzende können leichtgewichtig zu jeder Nachricht Feedback geben, indem sie die “Daumen hoch/runter”-Icons nutzen und einen optionalen Kommentar hinzufügen. Dieses Feedback kann entweder von Admins manuell ausgewertet oder durch automatisierte Analysen verarbeitet werden, um gezielt Optimierungspotenziale im System zu identifizieren.
3. Budgetmanagement – Kontrolle über Nutzung und Kosten
Die datenschutzkonforme Nutzung von LLMs im Zusammenhang mit eigenen Wissensquellen bietet Unternehmen enorme Möglichkeiten, bringt aber zugegebenermaßen auch Kosten mit sich. Ein durchdachtes Budgetmanagement hilft, Ressourcen fair und effizient zu nutzen und Kosten im Blick zu behalten.
Wie funktioniert das Budgetmanagement?
Individuelle und gruppenbasierte Budgets: Es wird festgelegt, wie viel Budget einzelnen Mitarbeitenden oder Teams in einem bestimmten Zeitraum zur Verfügung stehen. Dieses Budget muss nicht zwangsläufig ein Euro-Beitrag sein, sondern kann auch in eine virtuelle eigene Währung umgerechnet werden.
Transparenz für Nutzende: Alle Mitarbeitenden können jederzeit ihren aktuellen Budgetstatus einsehen. Das System zeigt an, wie viel des Budgets bereits verbraucht wurde und wie viel noch verfügbar ist. Wird das festgelegte Limit erreicht, pausiert der Chat automatisch, bis das Budget zurückgesetzt oder angepasst wird.
4. Sichere Authentifizierung – Schutz für sensible Daten
Ein wesentlicher Aspekt für Unternehmen ist oftmals die sichere und flexible Authentifizierung. Da RAG-Systeme oft mit sensiblen und vertraulichen Informationen arbeiten, ist ein durchdachtes Authentifizierungskonzept unverzichtbar.
Authentifizierungssysteme: Unsere Lösung ermöglicht die Anbindung unterschiedlicher Authentifizierungsverfahren, darunter weit verbreitete Systeme wie Microsoft Entra ID (ehemals Azure Active Directory). Dies bietet den Vorteil, bestehende Unternehmensstrukturen für die Nutzerverwaltung nahtlos einzubinden.
Zugriffskontrolle: Unterschiedliche Berechtigungen können auf Basis von Nutzerrollen definiert werden, z. B. für den Zugriff auf bestimmte Wissensquellen oder Funktionen.
5. Flexible Benutzeroberfläche
Unsere aktuelle Lösung vereint die meistgefragten Frontend-Features aus verschiedenen Projekten und bietet damit eine Benutzeroberfläche, die individuell anpassbar ist. Funktionen können bei Bedarf ausgeblendet oder erweitert werden, um spezifische Anforderungen zu erfüllen.
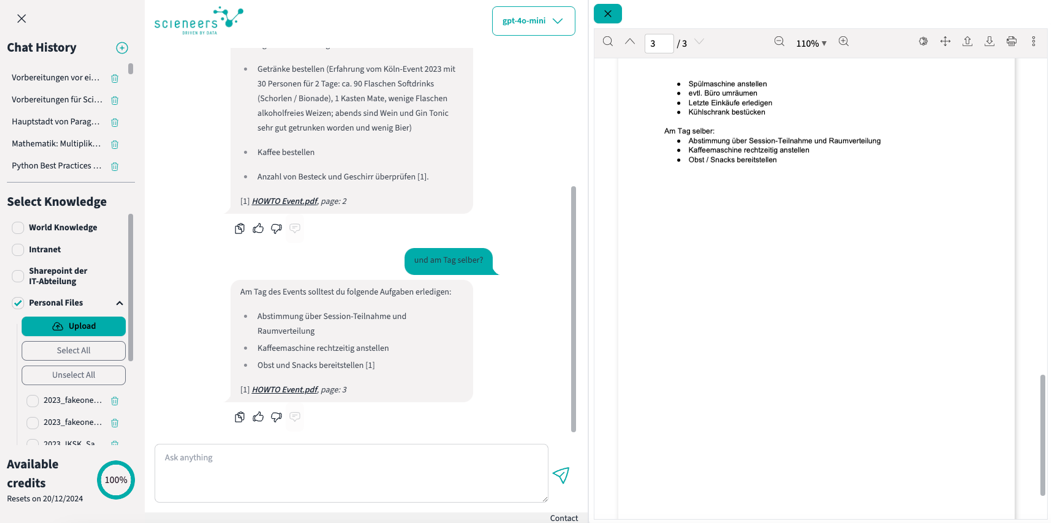
Chat-Applikation inklusive PDF-Viewer zur Anzeige von zitierten Dokumenten
Chat-Historie: Alle Chats werden automatisch benannt und gespeichert. Auf Wunsch können Nutzende Chats vollständig löschen – dies schließt auch ein endgültiges Entfernen aus dem System ein.
Zitationen: Zitationen gewährleisten, dass Informationen nachvollziehbar und überprüfbar bleiben. Gerade bei komplexen oder geschäftskritischen Fragen stärkt dies die Glaubwürdigkeit und ermöglicht es Nutzenden, die Richtigkeit und den Kontext der Antworten direkt zu überprüfen. Jede Antwort des Systems enthält Verweise auf die ursprünglichen Dokumentenquellen, beispielsweise mit Links zu der exakten Seite in einem PDF oder Absprung zur ursprünglichen Dokumentenquelle.
Einfache Anpassung von Prompts: Um die Systemantworten zu steuern, können Prompts über eine benutzerfreundliche Oberfläche angepasst werden – ganz ohne technisches Vorwissen.
Ausgabe von unterschiedlichen Medientypen: in den Antworten werden unterschiedliche Ausgabeformate, wie Codeblöcke oder Formeln, entsprechend angezeigt.
Unsere Chatbot-Lösung basiert auf den Erfahrungen aus zahlreichen Projekten und ermöglicht Unternehmen, Sprachmodelle gezielt und datenschutzkonform zu nutzen. Dabei können spezifische interne Wissensquellen wie SharePoint, OneDrive oder individuelle Dokumente effizient eingebunden werden.
Dank einer flexiblen Codebasis kann das System schnell auf unterschiedliche Anwendungsfälle angepasst werden. Funktionen wie die Feedback-Integration, das Budgetmanagement und die sichere Authentifizierung sorgen dafür, dass Unternehmen jederzeit die Kontrolle behalten – über sensible Daten und auch die Kosten. Damit bietet das System nicht nur eine praxisnahe Lösung für den Umgang mit Unternehmenswissen, sondern auch die nötige Transparenz und Sicherheit für eine nachhaltige Nutzung.
Sie sind neugierig geworden? Dann zeigen wir Ihnen in einem persönlichen Gespräch gerne unser System in einer Live-Demo und beantworten Ihre Fragen. Schreiben Sie uns einfach!
In der modernen Hochschulbildung sind die Optimierung und Personalisierung des Lernprozesses äußerst wichtig. Insbesondere in komplexen Studiengängen wie Jura können Technologien wie Large Language Models (LLMs) und Retrieval Augmented Generation (RAG) eine unterstützende Rolle spielen. Ein Pilotprojekt an der Universität Leipzig mit dem dortigen Rechenzentrum und der Juristenfakultät zeigt, wie diese Technologien erfolgreich in Form eines KI-Chatbots eingesetzt werden.
Hintergrund und Turing
Im Jahr 1950 stellte Alan Turing in seinem Essay „Computing Machinery and Intelligence“ die revolutionäre Frage: Können Maschinen denken? Er schlug das berühmte „Imitation Game“ vor, das heute als Turing-Test bekannt ist. Seiner Ansicht nach könnte eine Maschine als „denkend“ angesehen werden, wenn sie in der Lage ist, einen menschlichen Prüfer zu täuschen.
Dieser Gedanke bildet die theoretische Grundlage für viele moderne KI-Anwendungen. Seitdem ist ein langer Weg zurückgelegt worden, und insbesondere für Studierende eröffnen sich neue Möglichkeiten, KI-Tools wie z.B. LLMs im Rahmen ihres Studiums unterstürzend einzusetzen.
Wie funktioniert so ein Chatbot für das Jura-Studium?
Der KI-basierte Chatbot verwendet die fortschrittlichen Sprachmodelle von OpenAI, die so genannten ‘’Transformer’’. Diese Systeme, wie GPT-4, können mit der sogenannten „Retrieval Augmented Generation“ (RAG) Methode ergänzt werden, um korrekte Antworten auch auf komplexere juristische Fragen zu liefern. Der Prozess dahinter besteht aus mehreren Schritten:
1. Frage stellen (Query): Studierende stellen eine juristische Frage, z.B. “Was ist der Unterschied zwischen einer Hypothek und einer Sicherungsgrundschuld?“
2. Verarbeitung der Anfrage (Embedding): Die Frage wird in Vektoren umgewandelt, damit sie für das LLM lesbar werden und analysiert werden können.
3. Suche in Vektordatenbank:Das Retrieval-System sucht in einer Vektordatenbank nach relevanten Texten, die mit der Frage übereinstimmen. Diese können Skripte, Falllösungen oder Vorlesungsfolien sein.
4. Antwortgenerierung: Das LLM analysiert die gefundenen Daten und liefert eine präzise Antwort. Die Antwort kann mit Quellenangaben versehen werden, z.B. mit der Seite im Skript oder der entsprechenden Folie in der Vorlesung.
Für Jurastudierende ist dies ein mächtiges Tool, da sie nicht nur schnell Antworten auf sehr individuelle Fragen erhalten, sondern diese auch direkt auf die entsprechenden Lehrmaterialien verweisen. Dies erleichtert das Verständnis komplexer juristischer Konzepte und fördert das selbstständige Lernen.
Vorteile für Studierenden und Lehrenden
Chatbots bieten verschiedene Vorteile für das Lehren und Lernen an Universitäten. Für die Studierenden bedeutet dies:
Personalisierte Lernunterstützung: Die Studierenden können individuelle Fragen stellen und erhalten maßgeschneiderte Antworten.
Anpassung an unterschiedliche Themen: Man kann den Chatbot leicht an verschiedene Rechtsgebiete wie Zivilrecht, Strafrecht oder öffentliches Recht anpassen. Er kann auch schwierigere juristische Konzepte erklären oder bei der Prüfungsvorbereitung helfen.
Flexibilität und Kostentransparenz: Ob zu Hause oder unterwegs, der Chatbot steht jederzeit zur Verfügung und bietet Zugang zu den wichtigsten Informationen – über ein Learning Management System (LMS) wie Moodle oder direkt als App. Darüber hinaus sorgen monatliche Token-Budgets für eine klare Kostenkontrolle.
Auch für die Lehrenden bringt der Einsatz von LLMs in Kombination mit RAG Vorteile mit sich:
Unterstützung bei der Planung: KI-Tools können dabei helfen, Lehrveranstaltungen besser zu strukturieren.
Entwicklung von Lehrmaterialien: Die KI kann bei der Erstellung von Aufgaben, Lehrmaterialien, Fallbeispielen oder Klausurfragen unterstützen.
Herausforderungen beim Einsatz von LLMs
Trotz der vielen Vorteile und Möglichkeiten, die Chatbots und andere KI-basierte Lernsysteme bieten, gibt es auch Herausforderungen, die in Betracht gezogen werden müssen:
Ressourcenintensiv: Der Betrieb solcher Systeme erfordert einen hohen Rechenaufwand und verursacht entsprechende Kosten.
Abhängigkeit von Anbietern: Derzeit setzen viele solcher System auf Schnittstellen zu externen Anbietern wie Microsoft Azure oder OpenAI, was die Unabhängigkeit von Hochschulen einschränken kann.
Qualität der Antworten: KI-Systeme liefern nicht immer korrekte Ergebnisse. Es kann zu „Halluzinationen“ (falschen oder unsinnigen Antworten) kommen. Wie alle datenbasierten Systeme können auch LLMs Verzerrungen (Biases) aufweisen, die auf die verwendeten Trainingsdaten zurückzuführen sind. Daher muss sowohl die Genauigkeit der Antworten als auch die Vermeidung von Biases sichergestellt werden.
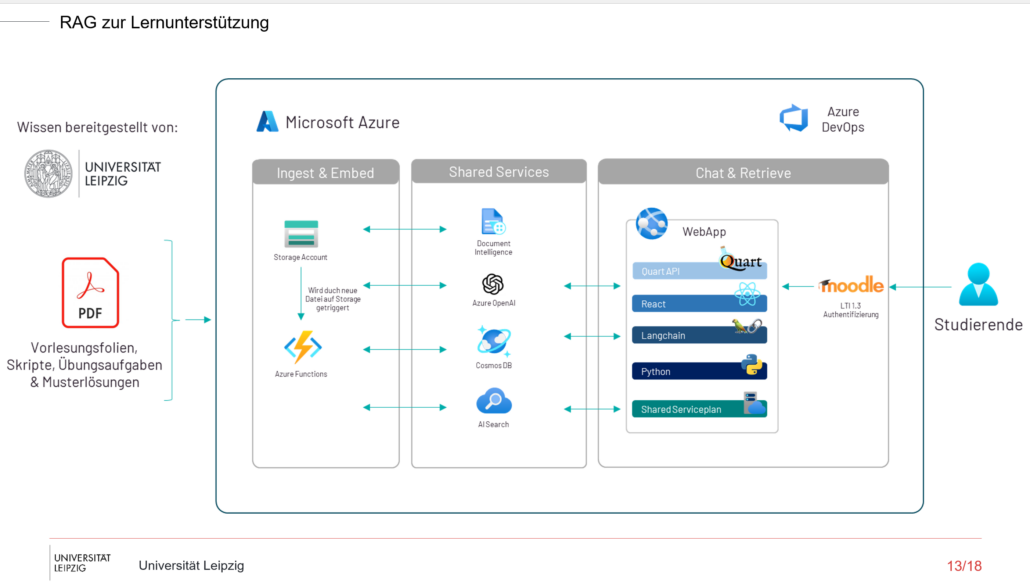
Der technische Hintergrund: Azure und OpenAI
Der oben vorgestellte Chatbot basiert auf der Cloud-Infrastruktur von Microsoft Azure. Azure bietet verschiedene Services, die eine sichere und effiziente Datenverarbeitung ermöglichen. Dazu gehören:
AI Search: Eine hybride Suche, die sowohl Vektorsuche als auch Volltextsuche kombiniert, um relevante Daten schnell zu finden..
Document Intelligence: Extrahiert Informationen aus PDF-Dokumenten und ermöglicht den direkten Zugriff auf Vorlesungsfolien, Skripte oder andere Lehrmaterialien.
OpenAI: Azure bietet Zugriff auf die leistungsfähigen Sprachmodelle von OpenAI. So wurden bei der Implementierung beispielsweise GPT-4 Turbo und das ada-002 Modell für Text Embeddings verwendet, um effizient korrekte Antworten zu generieren.
Darstellung des Datenverarbeitungsprozesses
Fazit
Das Pilotprojekt mit der Universität Leipzig zeigt wie der Einsatz von LLMs und RAG die Hochschulbildung unterstützen kann. Mithilfe dieser Technologien können Lernprozesse nicht nur effizienter, sondern auch flexibler und zielgerichteter gestaltet werden.
Durch den Einsatz von Microsoft Azure wird zudem eine sichere und DSGVO-konforme Datenverarbeitung gewährleistet.
Die Kombination aus leistungsfähigen Sprachmodellen und innovativen Suchmethoden bietet sowohl Studierenden als auch Lehrenden neue und effektive Wege, das Lernen und Lehren zu verbessern. Die Zukunft des Lernens wird damit personalisierbar, skalierbar und jederzeit verfügbar.
https://www.scieneers.de/wp-content/uploads/2024/11/aa.jpg413744Florence Lopezhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngFlorence Lopez2024-11-08 11:57:012024-12-12 16:25:00Wie Studierende von LLMs und Chatbots profitieren können
Wir waren für den zweiten Tag des diesjährigen Digital-Gipfels der Bundesregierung in Frankfurt am Main eingeladen. Ziel des Digital-Gipfels ist es, Menschen aus Politik, Wirtschaft, Forschung und Zivilgesellschaft zusammenzubringen, um Ideen, Lösungen und Herausforderungen in Bezug auf die digitale Transformation in Deutschland zu diskutieren.
Themen des Digital-Gipfels
Angeboten wurden verschiedene Vorträge und Diskussionsformate in Themenbereichen wie Vernetzte und datengetriebene Wirtschaft und Gesellschaft, Lernende Systeme und Kultur und Medien. So konnten wir beispielsweise mehr über die Organisation und Arbeitsweise der Datenlabore der Bundesregierung erfahren, die seit drei Jahren Datenprodukte und -projekte für die Bundesverwaltung umsetzen und damit den Einsatz von Daten und KI dort vorantreiben.
Ein weiteres wichtiges Thema war die Digitalisierungsstrategie der Bundesregierung, die Fortschritte und Herausforderungen aufzeigte, insbesondere hinsichtlich der Ausfinanzierung der sogenannten Leuchtturmprojekte und der Rolle des Beirats. Mehrere dieser Leuchtturmprojekte haben sich in anderen Sessions ebenfalls präsentiert und über ihre Arbeit informiert.
Pitch & Connect: Gemeinwohlorientierte KI-Projekte im Rampenlicht
Das Highlight für uns war das Event Pitch & Connect, bei dem sich 12 gemeinwohlorientierte KI-Projekte, die sich unter anderem mit Teilhabe, Desinformation oder Umwelt- und Wasserschutz befassen, einem engagierten Publikum vorstellen durften. Wir waren dort mit unserem Projekt StaatKlar: Dein digitaler Assistent für die Beantragung staatlicher Unterstützung vertreten.
StaatKlar dient dazu, Wissenslücken zu überbrücken und bürokratische Hürden bei der Beantragung staatlicher Ansprüche durch Bürger:innen abzubauen. Mit dem Talk to your Data-Ansatz, den wir bereits in vielen weiteren Projekten erfolgreich umgesetzt haben, werden für die Anwendung relevante Dokumente wie Informationsbroschüren zu staatlichen Leistungen als Datenbasis verwendet. Ein Large Language Model nutzt diese Datenbasis für die Generierung seiner Antworten. In der Folge können Bürger:innen in einer intuitiven webbasierten Chat-Anwendung mit dem Modell „sprechen“ und Antworten auf ihre Fragen und Hilfestellung zu ihren Herausforderungen in Bezug auf staatliche Unterstützung bekommen.
Mehr Informationen zu StaatKlar gibt es im 5-minütigen Pitch aus dem aufgezeichneten Livestream des Digital-Gipfels sowie einer kurzen Demo der Anwendung:
https://www.scieneers.de/wp-content/uploads/2024/10/20241022_161307-scaled-e1730281812544.jpg12242560Alexandra Wörnerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngAlexandra Wörner2024-10-31 12:50:032025-01-31 13:31:01KI für das Gemeinwohl auf dem Digital-Gipfel 2024
Vielen Unternehmen mangelt es nicht an Daten, sondern an Möglichkeiten diese zu verwalten und verfügbar zu machen. Eine besonders drängende Herausforderung ist der Wissenstransfer von älteren Mitarbeiter*Innen zur jüngeren Generation, der zum großen Teil von solchen Daten abhängig ist. Dabei geht es nicht nur um das in in Handbüchern dokumentierte Wissen sondern auch um das implizite Wissen, das „zwischen den Zeilen“ vorhanden ist – die Erkenntnisse und Erfahrungen, die in den Köpfe langjähriger Mitarbeiter*Innen stecken.
Diese Herausforderung besteht seit Jahren in vielen Branchen, und mit der rasanten Entwicklung von Künstlichen Intelligenz (KI), insbesondere der generativen KI, entstehen auch neue Möglichkeiten, dieses wertvolle Unternehmenswissen einzusetzen.
Der Aufstieg der generativen KI
Generative KI, insbesondere Large Language Models (LLMs) wie GPT-4o von OpenAI, Claude 3.5 Sonnet von Anthropic oder Llama3.2 von Meta, bieten neue Möglichkeiten, große Mengen unstrukturierter Daten zu verarbeiten und zugänglich zu machen. Mit diesen Modellen können Nutzer über Chatbot-Anwendungen mit Unternehmensdaten interagieren, wodurch der Wissenstransfer dynamischer und benutzerfreundlicher wird.
Die Frage ist jedoch, wie dem Chatbot die richtigen Daten zur Verfügung gestellt werden können. Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel.
Retrieval-Augmented Generation (RAG) für textuelle Daten
RAG hat sich als zuverlässige Lösung für den Umgang mit Textdaten erwiesen. Das Konzept ist einfach: Alle verfügbaren Unternehmensdaten werden in kleinere Datenblöcke (sogenannte Chunks) aufgeteilt und in (Vektor-)Datenbanken gespeichert, wo sie in numerische Embeddings umgewandelt werden. Wenn ein Benutzer eine Anfrage stellt, sucht das System nach relevanten Datenblöcken, indem es die Embeddings der Anfrage mit den gespeicherten Daten vergleicht.
Diese Methode erfordert kein Fine-Tuning der LLMs. Stattdessen werden relevante Daten abgerufen und an die Benutzeranfrage in der Prompt and das LLM angehängt, um sicherzustellen, dass die Antworten des Chatbots auf den unternehmensspezifischen Daten basieren. Dieser Ansatz funktioniert effektiv mit allen Arten von Textdaten, einschließlich PDFs, Webseiten und sogar mittels multimodaler Einbettung mit Bildern.
Auf diese Weise wird das in Handbüchern gespeicherte Unternehmenswissen für Mitarbeiter*Innen, Kunden oder andere Interessengruppen über KI-gestützte Chatbots leicht zugänglich.
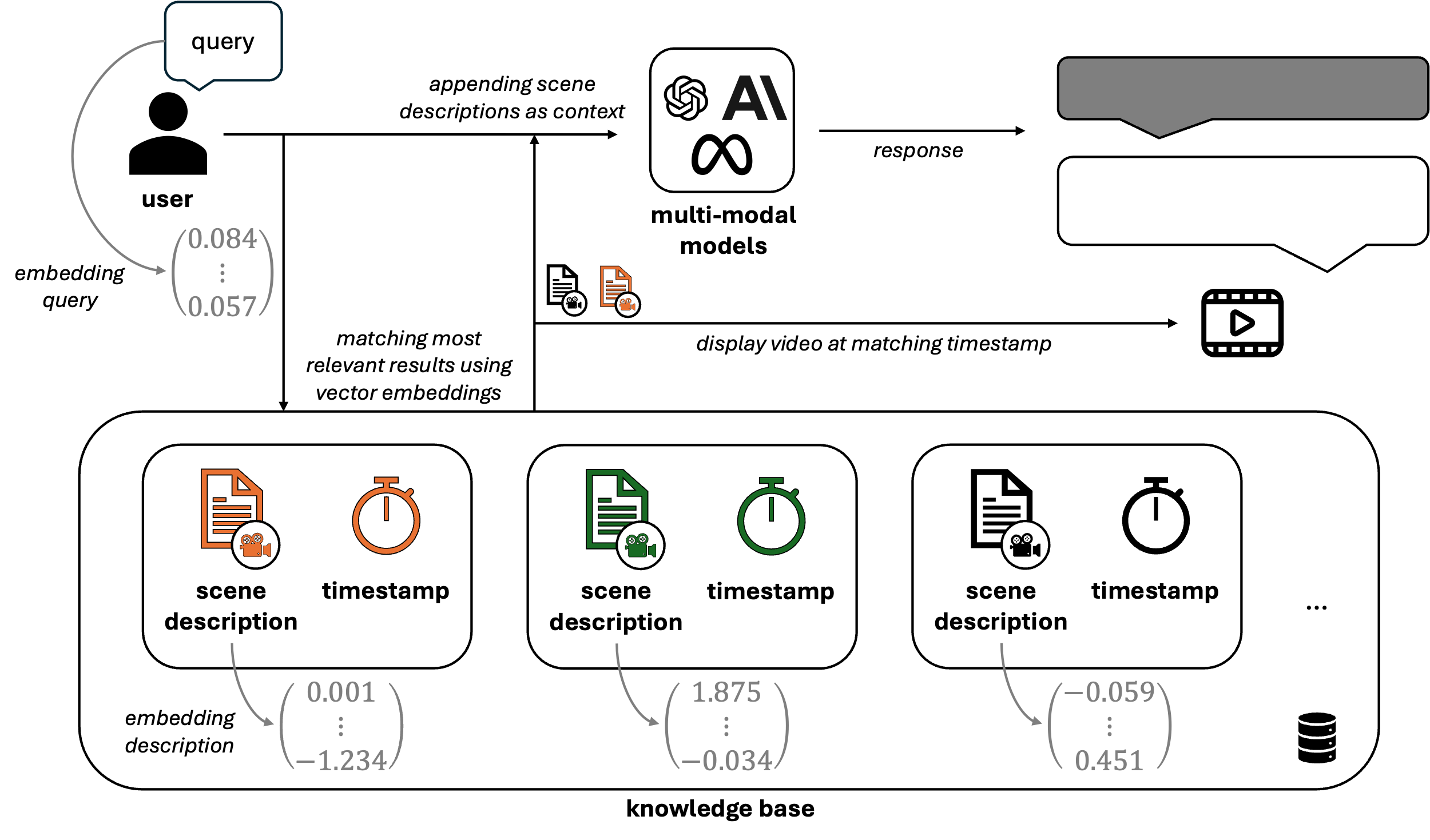
Erweiterung des RAG um Videodaten
Während RAG für textbasiertes Wissen gut funktioniert, ist es für komplexe, prozessbasierte Aufgaben, die sich oft besser visuell darstellen lassen, nicht vollständig geeignet. Für Aufgaben wie die Wartung von Maschinen, bei denen es schwierig ist, alles durch schriftliche Anweisungen zu erfassen, bieten Video-Tutorials eine praktische Lösung, ohne dass zeitaufwändige Dokumentationen geschrieben werden müssen.
Videos bilden implizites Wissen ab, indem sie Prozesse Schritt für Schritt mit Kommentaren aufzeichnen. Im Gegensatz zu Text ist die automatische Beschreibung eines Videos jedoch alles andere als einfach. Selbst Menschen gehen hierbei unterschiedlich vor und konzentrieren sich oft auf unterschiedliche Aspekte desselben Videos, je nach Perspektive, Fachwissen oder Zielsetzung. Diese Variabilität verdeutlicht die Herausforderung, vollständige und konsistente Informationen aus Videodaten zu extrahieren.
Aufschlüsseln von Videodaten
Um das in den Videos enthaltene Wissen den Nutzern über einen Chatbot zugänglich zu machen, ist unser Ziel, einen strukturierten Prozess für die Umwandlung von Videos in Text bereitzustellen. Dabei steht die Extraktion möglichst vieler relevanter Informationen im Vordergrund.
Videos bestehen aus drei Hauptkomponenten:
Metadaten: Metadaten sind in der Regel einfach zu handhaben, da sie oft in strukturierter Textform vorliegen.
Audio: Audiodaten können mit Hilfe von Sprach-zu-Text (STT) Modellen wie Whisper von OpenAI in Text umgewandelt werden. Für branchenspezifische Kontexte ist es auch möglich, die Genauigkeit zu verbessern, indem benutzerdefinierte Terminologie in diese Modelle integriert wird.
Frames (visuelle Elemente): Die eigentliche Herausforderung besteht darin, die Frames (Bilder) sinnvoll in die Audiotranskription zu integrieren. Beide Komponenten sind voneinander abhängig – ohne Audiokommentare fehlt den Frames oft der Kontext und umgekehrt.
Bewältigung der Herausforderungen bei der Beschreibung von Videos
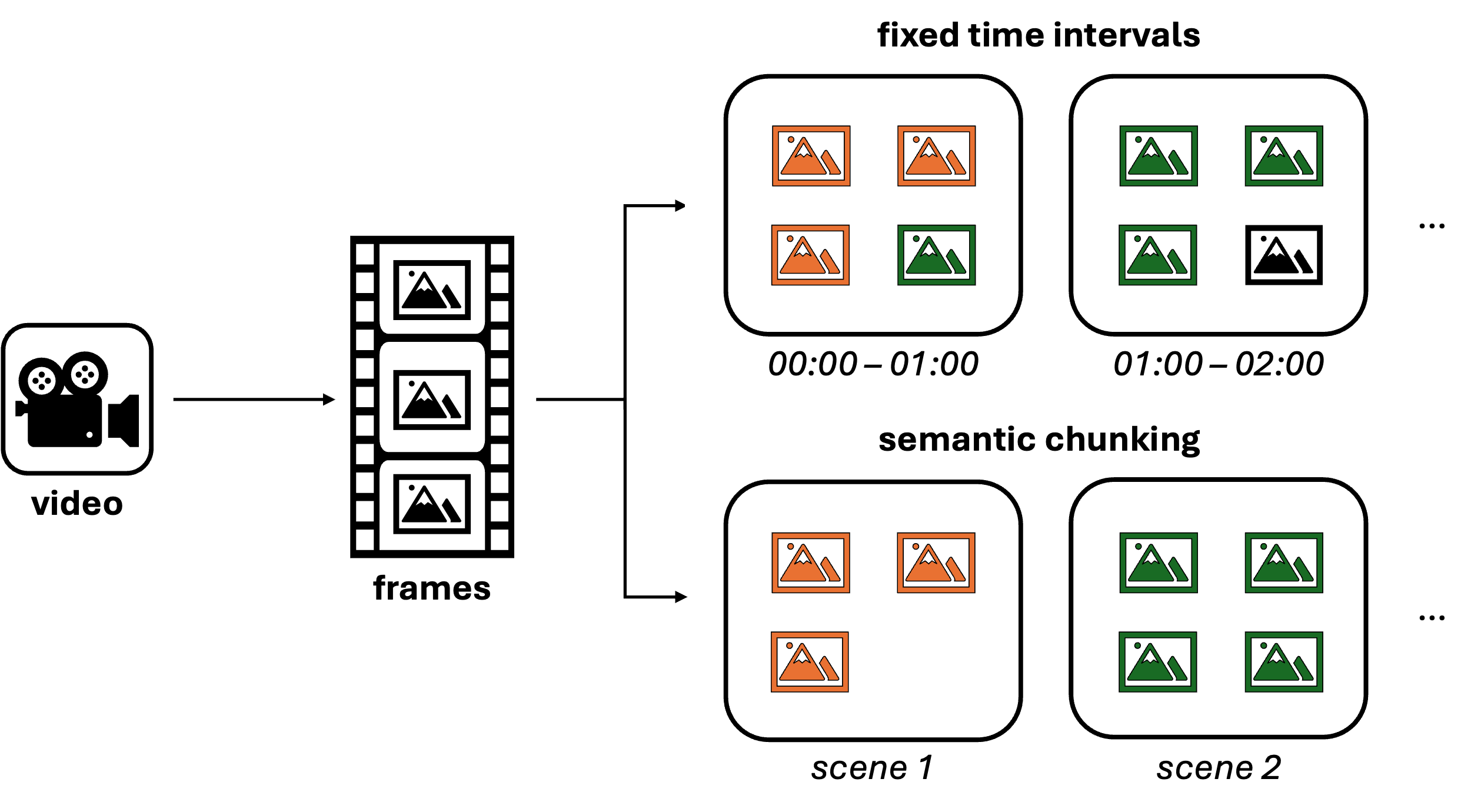
Abbildung 1: Chunking-Verfahren von VideoRAG.
Bei der Arbeit mit Videodaten bestehen drei wesentlichen Herausforderungen:
Beschreibung der einzelnen Bilder (Frames)
Erhaltung des Kontextes, da nicht jedes Bild unabhängig von den anderen relevant ist
Integration der Audiotranskription für ein besseres Verständnis des Videoinhalts
Um diese Probleme zu lösen, können multimodale Modelle wie GPT-4o verwendet werden, die sowohl Text als auch Bilder verarbeiten können. Durch die Verwendung von Videobildern und transkribiertem Audio als Input für diese Modelle kann eine vollständige Beschreibung von Videosegmenten erstellt werden.
Entscheidend ist jedoch, dass der Kontext zwischen den einzelnen Frames erhalten bleibt. Hier wird die Gruppierung von Frames (oft auch als Chunking bezeichnet) wichtig. Zwei Methoden, um Frames zu gruppieren sind:
Feste Zeitintervalle: Ein einfacher Ansatz, bei dem aufeinanderfolgende Frames auf der Grundlage vordefinierter Zeitintervalle gruppiert werden. Diese Methode ist einfach zu implementieren und für viele Anwendungsfälle gut geeignet.
Semantisches Chunking: Ein anspruchsvollerer Ansatz, bei dem Frames auf der Grundlage ihrer visuellen oder kontextuellen Ähnlichkeit gruppiert werden, um sie effektiv in Szenen zu organisieren. Es gibt verschiedene Möglichkeiten, semantisches Chunking zu implementieren, wie z.B. die Verwendung von Convolutional Neural Networks (CNNs) zur Berechnung der Ähnlichkeit von Frames oder die Verwendung von multimodalen Modellen wie GPT-4o zur Vorverarbeitung. Durch die Festlegung eines Ähnlichkeitsschwellenwertes können verwandte Bilder gruppiert werden, um das Wesentliche jeder Szene besser zu erfassen.
Sobald die Bilder gruppiert sind, können sie zu Bildrastern kombiniert werden. Diese Technik ermöglicht es dem Modell, die Beziehung und Abfolge zwischen verschiedenen Frames zu verstehen, während die narrative Struktur des Videos erhalten bleibt.
Die Wahl zwischen festen Zeitintervallen und semantischem Chunking hängt von den spezifischen Anforderungen des Anwendungsfalls ab. Unserer Erfahrung nach sind feste Intervalle für die meisten Szenarien ausreichend. Obwohl semantisches Chunking die zugrundeliegende Semantik des Videos besser erfasst, erfordert es die Abstimmung mehrerer Hyperparameter und kann ressourcenintensiver sein, da jeder Anwendungsfall eine eigene Konfiguration erfordern kann.
Mit zunehmender Leistungsfähigkeit von LLMs und der Zunahme von Kontextfenstern könnte man versucht sein, alle Bilder in einem einzigen Aufruf an das Modell zu übergeben. Dieser Ansatz sollte jedoch mit Vorsicht gewählt werden. Wenn zu viele Informationen auf einmal übergeben werden, kann das Modell überfordert werden und wichtige Details übersehen. Darüber hinaus sind aktuelle LLMs durch die Begrenzung ihrer Token-Ausgabe eingeschränkt (z.B. erlaubt GPT-4o 4096 Token), was die Notwendigkeit gut durchdachter Verarbeitungs- und Framing-Strategien noch unterstreicht.
Erstellung von Videobeschreibungen mit multimodalen Modellen
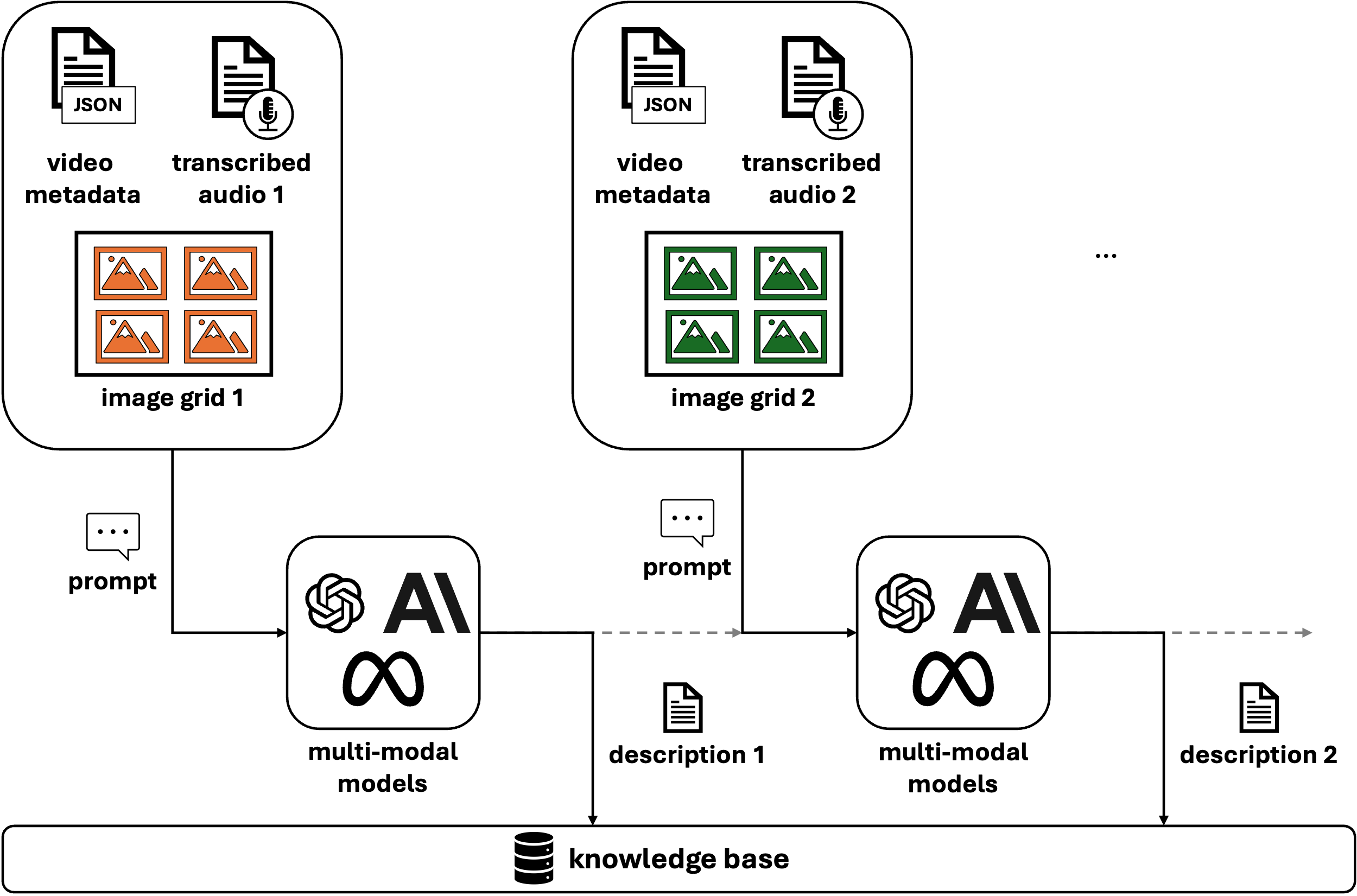
Abbildung 2: VideoRAG Ingestion Pipeline.
Sobald die Bilder gruppiert und mit der entsprechenden Audiotranskription verknüpft sind, kann das multimodale Modell geprompted werden, Beschreibungen für diese Teile des Videos zu erzeugen. Um die Kontinuität zu wahren, können Beschreibungen von früheren Teilen des Videos auf spätere Teile übertragen werden, so dass ein kohärenter Fluss entsteht (siehe Abbildung 2). Am Ende hat man Beschreibungen für jeden Teil des Videos, die zusammen mit Zeitstempeln in einer Wissensdatenbank gespeichert werden können, um eine einfache Referenz zu ermöglichen.
VideoRAG zum Leben erwecken
Abbildung 3: Retrieval-Prozess von VideoRAG.
Wie in Abbildung 3 dargestellt, werden alle Szenenbeschreibungen der in der Wissensbasis gespeicherten Videos in numerische Embeddings umgewandelt. Dies ermöglicht ein ähnliches Embedding der Benutzeranfragen und damit eine effiziente Suche nach relevanten Videoszenen anhand von Vektorähnlichkeiten (z.B. Kosinus-Ähnlichkeit). Sobald die relevantesten Szenen identifiziert sind, werden die entsprechenden Beschreibungen der Anfrage hinzugefügt, um dem LLM einen auf dem tatsächlichen Videoinhalt basierenden Kontext zu liefern. Zusätzlich zur generierten Antwort ruft das System die zugehörigen Zeitstempel und Videosegmente ab, so dass der Benutzer die Informationen direkt im Quellmaterial überprüfen und validieren kann.
Durch die Kombination von RAG-Technologien mit Videoverarbeitungsfunktionen können Unternehmen eine umfassende Wissensbasis aufbauen, die sowohl Text- als auch Videodaten enthält. Vor allem neu eingestellte Mitarbeiter*Innen können schnell auf kritische Erkenntnisse älterer Kollegen zugreifen – egal ob diese dokumentiert oder per Video demonstriert wurden – und so den Wissenstransfer effizienter gestalten.
Lessons Learned
Während der Entwicklung von VideoRAG hatten wir einige wichtige Learnings, von denen zukünftige Projekte in diesem Bereich profitieren können. Hier sind einige der wichtigsten Lektionen, die wir gelernt haben:
1. Optimierung der Prompts mit dem CO-STAR Framework
Wie bei den meisten Anwendungen, an denen LLMs beteiligt sind, hat sich das Prompt-Engineering als entscheidende Komponente für unseren Erfolg erwiesen. Die Erstellung präziser und kontextbezogener Eingabeaufforderungen hat einen großen Einfluss auf die Leistung des Modells und die Qualität der Ausgabe. Wir haben festgestellt, dass die Verwendung des CO-STAR Frameworks – eine Struktur, die den Schwerpunkt auf Context, Goal, Style, Tone, Audience und Response legt – einen soliden Leitfaden für das Prompt-Engineering darstellt.
Durch die systematische Berücksichtigung aller Elemente von CO-STAR konnten wir die Konsistenz der Antworten sicherstellen, insbesondere in Bezug auf das Format der Beschreibung. Durch die Verwendung dieser Struktur konnten wir zuverlässigere und individuellere Ergebnisse erzielen und Mehrdeutigkeiten in den Videobeschreibungen minimieren.
2. Einführung von Leitplanken zur Vermeidung von Halluzinationen
Einer der schwierigsten Aspekte bei der Arbeit mit LLM ist der Umgang mit ihrer Tendenz, Antworten zu generieren, auch wenn keine relevanten Informationen in der Wissensbasis vorhanden sind (sogenannte Hullunizationen). Wenn eine Frage außerhalb der verfügbaren Daten liegt, können LLMs auf Halluzinationen oder ihr implizites Wissen zurückgreifen, was oft zu ungenauen oder unvollständigen Antworten führt.
Um dieses Risiko zu verringern, haben wir einen zusätzlichen Überprüfungsschritt eingeführt. Bevor eine Benutzeranfrage beantwortet wird, lassen wir das Modell die Relevanz jedes aus der Wissensbasis abgerufenen Chunks bewerten. Wenn keine der abgerufenen Daten die Anfrage sinnvoll beantworten kann, wird das Modell angewiesen, nicht fortzufahren. Diese Strategie wirkt wie eine Leitplanke, die nicht fundierte oder sachlich falsche Antworten verhindert und sicherstellt, dass nur relevante und fundierte Informationen verwendet werden. Diese Methode ist besonders wirksam, um die Integrität der Antworten zu wahren, wenn die Wissensbasis keine Informationen zu bestimmten Themen enthält.
3. Umgang mit der Fachterminologie bei der Transkription
Ein weiterer kritischer Punkt war die Schwierigkeit der STT-Modelle, mit branchenspezifischen Begriffen umzugehen. Diese Begriffe, zu denen oft Firmennamen, Fachjargon, Maschinenspezifikationen und Codes gehören, sind für eine genaue Suche und Transkription unerlässlich. Leider werden sie oft missverstanden oder falsch transkribiert, was zu ineffektiven Suchen oder Antworten führen kann.
Um dieses Problem zu lösen, haben wir eine kuratierte Sammlung von branchenspezifischen Begriffen erstellt, die für unseren Anwendungsfall relevant sind. Durch die Integration dieser Begriffe in den Prompt des STT- Modells konnten wir die Qualität der Transkription und die Genauigkeit der Antworten erheblich verbessern. Das Whisper-Modell von OpenAI unterstützt z.B. die Einbeziehung domänenspezifischer Terminologie, wodurch wir den Transkriptionsprozess effizienter steuern und sicherstellen konnten, dass wichtige technische Details erhalten bleiben.
Fazit
VideoRAG ist der nächste Schritt in der Nutzung generativer KI für den Wissenstransfer, insbesondere in Branchen, in denen praktische Aufgaben mehr als nur Text zur Erklärung erfordern. Durch die Kombination von multimodalen Modellen und RAG-Techniken können Unternehmen sowohl explizites als auch implizites Wissen über Generationen hinweg effektiv bewahren und weitergeben.
https://www.scieneers.de/wp-content/uploads/2024/10/neu.jpg7581024Arne Grobrueggehttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngArne Grobruegge2024-10-23 09:15:402025-01-31 13:31:35Der Einsatz von VideoRAG für den Wissenstransfer im Unternehmen
Die neue Version der aus Azure bekannten Data Factory in Microsoft Fabric stand in letzter Zeit im Fokus zweier Vorträge, die scieneers auf renommierten Veranstaltungen präsentieren durften. Stefan Kirner hat auf der SQL Konferenz in Hanau, ausgerichtet von Datamonster, sowie auf den SQLDays, organisiert von ppedv, gesprochen.
Die Präsentation beleuchtete die technischen und konzeptionellen Unterschiede zwischen der Azure Data Factory und jener in Microsoft Fabric. Ebenso wurden die Auswirkungen dieser Unterschiede auf die Entwicklung sowie wichtige Aspekte des Application Lifecycle Managements beim Teamwork in Fabric thematisiert.
Hier eine kurze Zusammenfassung der gewonnenen Erkenntnisse:
Das Gute:
– Die Data Factory entwickelt sich weiter, bietet erweiterte Features und ist besser in das Gesamtsystem integriert.
– Das Software-as-a-Service Modell und ein berechenbares Preismodell erleichtern gerade Neulingen den Einstieg.
– Viel des bereits vorhandenen technischen Know-hows und Methodenwissens rund um die Azure Data Factory ist weiterhin anwendbar.
– Die Migration von bestehenden Data Engineering Projekten ist in den meisten Fällen problemlos möglich.
Das Schlechte:
– Für sehr kleine Projekte ist die Data Factory in Fabric nicht effizient einsetzbar.
– Spark Notebooks sind in den kleinsten verfügbaren Kapazitäten nicht wirklich nutzbar.
Das Hässliche:
– Es mangelt noch immer an Unterstützung für Git und Deployment Pipelines für Data Flows der zweiten Generation.
– Es existieren viele GUI Bugs und die Stabilität lässt zu wünschen übrig.
– Die noch eingeschränkte Anzahl von Datenquellen bei der Copy Activity führt zu Verwirrung.
Trotz der genannten Schwachstellen entwickelt sich Fabric in eine sehr positive Richtung. Microsoft arbeitet mit Hochdruck an den aktuellen Herausforderungen. Scieneers freut sich darauf, diese Technologie in zukünftigen Kundenprojekten weiterhin erfolgreich einzusetzen.
https://www.scieneers.de/wp-content/uploads/2024/10/stefan-kriner-sql-konferenz.png14862514Stefan Kirnerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngStefan Kirner2024-10-14 16:45:432025-01-31 13:32:21Data Factory in Fabric – the good, the bad and the ugly