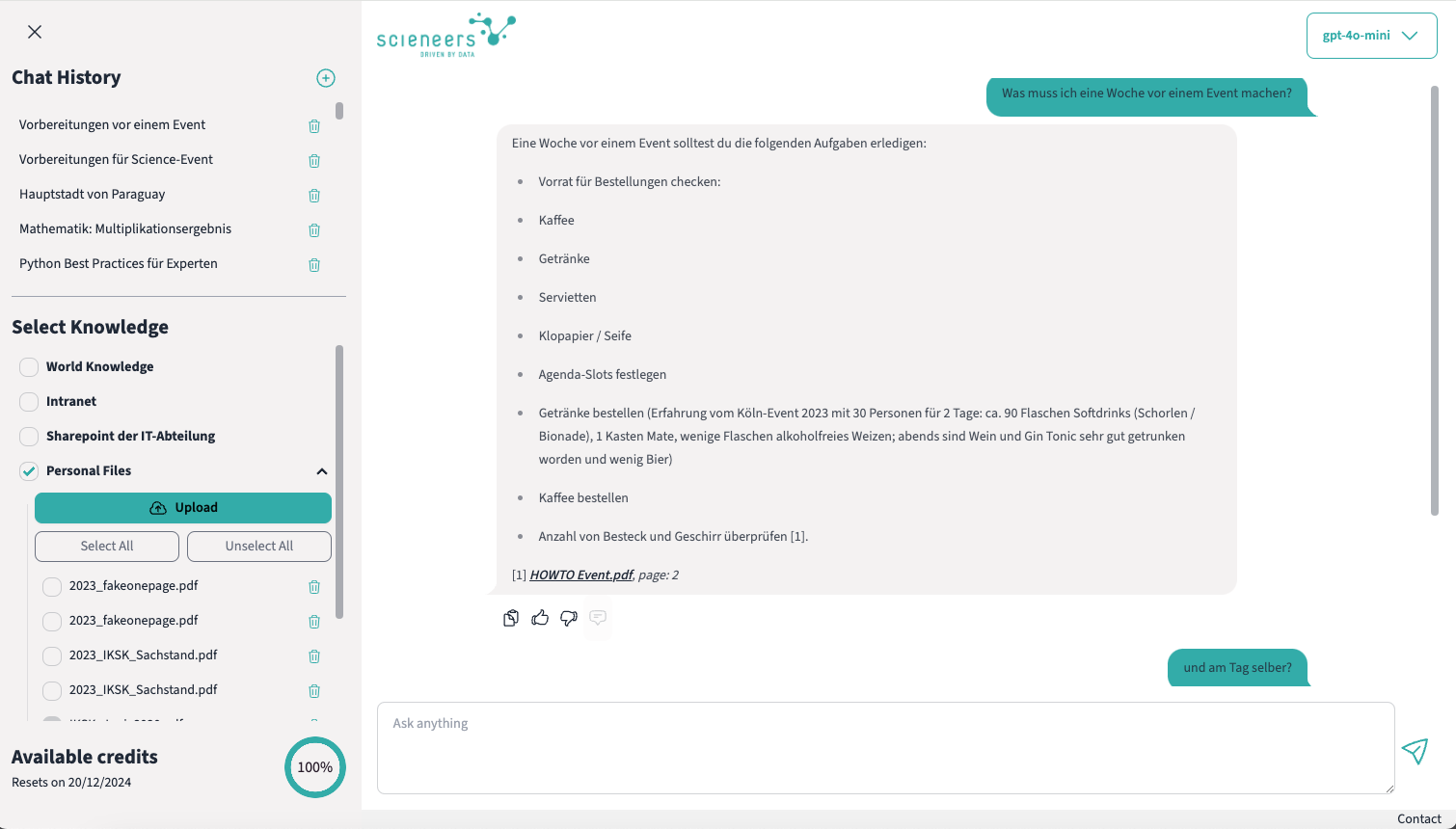
Bei der Wahl eines Arbeitgebers geht es heute nicht nur um den Job selbst, sondern auch um die Werte und Leistungen, die das Unternehmen bieten kann.
Für uns ist es wichtig, dass unsere Mitarbeitenden nicht nur einen Arbeitsplatz finden, sondern auch eine Umgebung, in der sie sich wohlfühlen und entfalten können.
Deshalb legen wir großen Wert darauf, um ein Arbeitsumfeld zu schaffen, das sowohl die berufliche als auch die persönliche Entwicklung fördert.
Unsere Leistungen sind so gestaltet, dass sie das Beste aus beiden Welten bieten. Eine Unternehmenskultur, die auf Transparenz, Inklusion und Nachhaltigkeit setzt und Benefits, die begeistern und Gründe sind, Teil unseres Teams zu werden.
Hier ein Überblick über die Benefits, die dich bei uns erwarten:
1. Tolle Büros & weitreichende Home-Office-Möglichkeit
Wir wissen, wie wichtig Flexibilität im Arbeitsalltag ist. Wir vertrauen darauf, dass unsere Mitarbeitenden selbst am besten wissen, wo und wann sie am besten produktiv arbeiten können.
Ob man den Austausch in einem modernen Büro sucht oder mal in Ruhe im Home-Office arbeiten möchte – bei uns ist beides möglich.
Dafür haben wir drei schöne Büros mit guter Anbindung in Hamburg, Köln und Karlsruhe.
Mit unseren weitreichenden Home-Office-Möglichkeiten bieten wir unseren Mitarbeitenden außerdem die Möglichkeit, ihren Arbeitstag so zu gestalten, dass er optimal zu ihrem individuellen Lebensstil passt.
Office in KölnOffice in KarlsruheOffice in Hamburg
Aus diesem Grund möchten wir unsere Mitarbeitenden dabei unterstützen, Familie und Beruf unter einen Hut zu bringen.
Dafür bieten wir neben flexiblen Arbeitszeiten auch einen Kita-Zuschuss. So möchten wir die Vereinbarkeit von Beruf und Familie erleichtern.
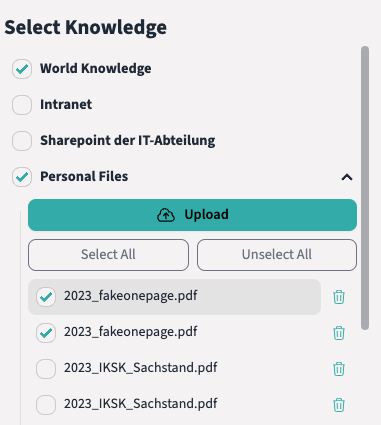
3. Mitarbeiter-Events und Office-Lunches
Ob gemeinsames Essen, sportliche Aktivitäten oder kulturelle Erlebnisse – unser Ziel ist es, eine Arbeitsatmosphäre zu schaffen, in der der Teamgeist und der Austausch zwischen unseren Teammitgliedern im Vordergrund stehen.
Mit regelmäßigen Mitarbeiter-Events, Office-Lunches und weiteren gemeinsamen Aktivitäten fördern wir aktiv den Austausch und stärken den Zusammenhalt im Team.
Auch Erfolge und Feste feiern wir gerne gemeinsam – auf unsere regelmäßigen Zusammenkünfte an wechselnden Orten sowie auf unsere Weihnachtsfeier freuen sich unsere Mitarbeitenden jedes Jahr erneut.
4. Weiterbildungsbudget & Mentoring
Die Technologiebranche ist schnelllebig – entsprechend ist die persönliche Fortbildung ein entscheidender Faktor. Aus diesem Grund bieten wir jedem Mitarbeitenden ein individuelles Fortbildungsbudget, das sie frei in seine Weiterentwicklung investieren kann – egal ob mit Büchern, Online-Kursen, Fortbildungen oder ganz eigenen Ideen.
Die persönliche Weiterentwicklung beschränkt sich aber natürlich nicht nur auf fachliche Kompetenzen. Mit unserem Mentoring-Programm sorgen wir dafür, dass neue Mitarbeitende sich schnell einfinden. Darüber hinaus begleiten wir sie auch langfristig durch regelmäßige Feedbackgespräche und jährliche Rückblicke.
Erfolg ist ein Gemeinschaftsprojekt und unsere Mitarbeitenden ermöglichen diesen. Mit der Mitarbeiterbeteiligung sorgen wir dafür, dass sich Engagement auch langfristig auszahlt und dass sie direkt davon profitieren können.
Für eine sichere Zukunft sorgen wir gemeinsam mit unseren Mitarbeitenden vor. Wir denken mit und unterstützen finanziell bei der betrieblichen Altersvorsorge.
6. Moderne Hardware nach Wahl – die privat genutzt werden kann
Egal ob Mac, Windows oder Linux – unsere Mitarbeitenden entscheiden selbst, mit welcher Hardware sie arbeiten möchten. Dazu gehört natürlich auch ein aktuelles Smartphone mit entsprechendem Telekom-Vertrag zur Standardausstattung unserer Mitarbeitenden.
Unsere Mitarbeitenden können die moderne Hardware ihrer Wahl auch privat nutzen. Wir sorgen dafür, dass es ihnen an nichts fehlt, um produktiv und kreativ zu sein.
7. Job-Ticket, Job-Rad und Firmenwagen-Leasing
Mobilität wird leicht gemacht: Ob mit dem Job-Ticket, dem Job-Rad oder über unser Firmenwagen-Leasing – wir unterstützen alle Mitarbeitenden dabei, mobil und nachhaltig unterwegs zu sein, egal wie sie zur Arbeit kommen möchten.
8. Sportzuschuss
Mit unserem Sport-Zuschuss bei der Mitgliedschaft im Urban Sports Club unterstützen wir alle Mitarbeitenden, die daran interessiert sind, aktiv zu bleiben.
9. Inklusion, Transparenz und Nachhaltigkeit als Firmenwerte
Bei scieneers setzen wir auf eine offene Unternehmenskultur, in der alle willkommen sind. Inklusion, Transparenz und Nachhaltigkeit sind die Werte, die wir aktiv leben.
Wir schaffen ein Arbeitsumfeld, das Vielfalt und Diversität feiert und jedem eine Stimme gibt. Deshalb haben wir als Unternehmen die Charta der Vielfalt unterzeichnet.
Bereit, Teil unseres Teams zu werden?
Unsere Benefits sind nur ein Teil dessen, was scieneers so besonders macht.
Wenn Du eine offene und moderne Unternehmenskultur suchst, die Dich unterstützt und fördert, dann freuen wir uns darauf, von Dir zu hören.
Entdecke unsere aktuellen Stellenangebote und finde heraus, wie Du bei uns durchstarten kannst!
https://www.scieneers.de/wp-content/uploads/2025/01/L1021346-1210x423-1.jpg8442420Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2025-01-31 08:52:002025-03-17 09:15:27Benefits bei scieneers
Jeder kennt ChatGPT – ein Chatbot, der Antworten auf fast jede Frage liefert. Doch in vielen Firmen ist die Nutzung offiziell noch nicht erlaubt oder wird nicht bereitgestellt. Dabei kann ChatGPT komplett datenschutzkonform und sicher betrieben werden und Mitarbeitenden einen einfachen Zugang zu internem Firmenwissen ermöglichen. Basierend auf Erfahrungen aus zahlreichen Retrieval-Augmented Generation (RAG)-Projekten haben wir ein modulares System entwickelt, das speziell auf die Bedürfnisse mittelständischer Unternehmen und Organisationen zugeschnitten ist. In diesem Beitrag stellen wir unseren leichtgewichtigen und anpassbaren Chatbot vor, der einen datenschutzkonformen Zugriff auf Unternehmenswissen ermöglicht.
1. Eigene Wissensquellen nutzen
Der Kern unseres RAG-Systems liegt darin, dass ein LLM auf die unternehmensspezifische Wissensquellen zugreifen kann. Dem Chatbot können verschiedene Datenquellen zur Verfügung gestellt werden:
1. Nutzerspezifische Dokumente:
Mitarbeitende können eigene Dateien hochladen, z. B. PDF-Dokumente, Word-Dateien, Excel-Tabellen oder sogar Videos. Diese werden im Hintergrund verarbeitet und stehen nach kurzer Zeit dauerhaft zum Chatten zur Verfügung.
Der Verarbeitungsstatus ist jederzeit einsehbar, damit transparent bleibt, wann die Inhalte für Anfragen genutzt werden können.
Beispiel: Ein Vertriebsmitarbeitender lädt eine Excel-Tabelle mit Preisinformationen hoch. Das System kann daraufhin Fragen zu den Preisen spezifischer Produkte beantworten.
2. Globale unternehmensinterne Wissensquellen:
Das System kann auf zentrale Dokumente aus Plattformen wie SharePoint, OneDrive oder dem Intranet zugreifen. Diese Daten sind für alle Nutzenden zugänglich.
Beispiel: Ein Mitarbeitender möchte nach den Regelungen zur betrieblichen Altersvorsorge suchen. Da die entsprechende Betriebsvereinbarung zugänglich ist, kann der Chatbot die korrekte Antwort geben.
3. Gruppenspezifische Wissensquellen:
Es ist auch möglich, dass Informationen / Dokumente nur für spezifische Teams oder Abteilungen zugänglich gemacht werden.
Beispiel: Nur das HR-Team hat Zugriff auf Richtlinien zum Onboarding. Das System kann Fragen dazu nur HR-Mitarbeitenden beantworten.
Auch wenn Nutzende mit allen verfügbaren Datenquellen arbeiten, stellt das System im Hintergrund sicher, dass nur für eine Anfrage relevante Informationen genutzt werden, um Antworten zu generieren. Durch intelligente Filtermechanismen werden irrelevante Inhalte automatisch ausgeblendet.
Nutzende haben jedoch die Möglichkeit, explizit festzulegen, welche Wissensquellen berücksichtigt werden sollen. Sie können beispielsweise wählen, ob eine Anfrage auf aktuelle Quartalszahlen oder auf allgemeine HR-Richtlinien zugreifen soll. Dadurch wird vermieden, dass irrelevante oder veraltete Informationen in die Antwort einfließen.
2. Feedback-Prozess und kontinuierliche Verbesserung
Ein zentraler Bestandteil unserer RAG-Lösung ist die Möglichkeit, systematisch Feedback der Nutzenden zu erfassen, um die Qualität des Systems verbessern zu können, indem Schwachstellen identifiziert werden. Eine Schwachstelle könnten beispielsweise Dokumente mit uneinheitlichem Format darstellen, wie schlecht gescannte PDFs oder Tabellen mit mehreren verschachtelten Ebenen, die fehlerhaft interpretiert werden.
Nutzende können leichtgewichtig zu jeder Nachricht Feedback geben, indem sie die “Daumen hoch/runter”-Icons nutzen und einen optionalen Kommentar hinzufügen. Dieses Feedback kann entweder von Admins manuell ausgewertet oder durch automatisierte Analysen verarbeitet werden, um gezielt Optimierungspotenziale im System zu identifizieren.
3. Budgetmanagement – Kontrolle über Nutzung und Kosten
Die datenschutzkonforme Nutzung von LLMs im Zusammenhang mit eigenen Wissensquellen bietet Unternehmen enorme Möglichkeiten, bringt aber zugegebenermaßen auch Kosten mit sich. Ein durchdachtes Budgetmanagement hilft, Ressourcen fair und effizient zu nutzen und Kosten im Blick zu behalten.
Wie funktioniert das Budgetmanagement?
Individuelle und gruppenbasierte Budgets: Es wird festgelegt, wie viel Budget einzelnen Mitarbeitenden oder Teams in einem bestimmten Zeitraum zur Verfügung stehen. Dieses Budget muss nicht zwangsläufig ein Euro-Beitrag sein, sondern kann auch in eine virtuelle eigene Währung umgerechnet werden.
Transparenz für Nutzende: Alle Mitarbeitenden können jederzeit ihren aktuellen Budgetstatus einsehen. Das System zeigt an, wie viel des Budgets bereits verbraucht wurde und wie viel noch verfügbar ist. Wird das festgelegte Limit erreicht, pausiert der Chat automatisch, bis das Budget zurückgesetzt oder angepasst wird.
4. Sichere Authentifizierung – Schutz für sensible Daten
Ein wesentlicher Aspekt für Unternehmen ist oftmals die sichere und flexible Authentifizierung. Da RAG-Systeme oft mit sensiblen und vertraulichen Informationen arbeiten, ist ein durchdachtes Authentifizierungskonzept unverzichtbar.
Authentifizierungssysteme: Unsere Lösung ermöglicht die Anbindung unterschiedlicher Authentifizierungsverfahren, darunter weit verbreitete Systeme wie Microsoft Entra ID (ehemals Azure Active Directory). Dies bietet den Vorteil, bestehende Unternehmensstrukturen für die Nutzerverwaltung nahtlos einzubinden.
Zugriffskontrolle: Unterschiedliche Berechtigungen können auf Basis von Nutzerrollen definiert werden, z. B. für den Zugriff auf bestimmte Wissensquellen oder Funktionen.
5. Flexible Benutzeroberfläche
Unsere aktuelle Lösung vereint die meistgefragten Frontend-Features aus verschiedenen Projekten und bietet damit eine Benutzeroberfläche, die individuell anpassbar ist. Funktionen können bei Bedarf ausgeblendet oder erweitert werden, um spezifische Anforderungen zu erfüllen.
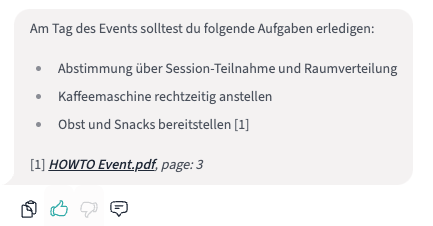
Chat-Applikation inklusive PDF-Viewer zur Anzeige von zitierten Dokumenten
Chat-Historie: Alle Chats werden automatisch benannt und gespeichert. Auf Wunsch können Nutzende Chats vollständig löschen – dies schließt auch ein endgültiges Entfernen aus dem System ein.
Zitationen: Zitationen gewährleisten, dass Informationen nachvollziehbar und überprüfbar bleiben. Gerade bei komplexen oder geschäftskritischen Fragen stärkt dies die Glaubwürdigkeit und ermöglicht es Nutzenden, die Richtigkeit und den Kontext der Antworten direkt zu überprüfen. Jede Antwort des Systems enthält Verweise auf die ursprünglichen Dokumentenquellen, beispielsweise mit Links zu der exakten Seite in einem PDF oder Absprung zur ursprünglichen Dokumentenquelle.
Einfache Anpassung von Prompts: Um die Systemantworten zu steuern, können Prompts über eine benutzerfreundliche Oberfläche angepasst werden – ganz ohne technisches Vorwissen.
Ausgabe von unterschiedlichen Medientypen: in den Antworten werden unterschiedliche Ausgabeformate, wie Codeblöcke oder Formeln, entsprechend angezeigt.
Unsere Chatbot-Lösung basiert auf den Erfahrungen aus zahlreichen Projekten und ermöglicht Unternehmen, Sprachmodelle gezielt und datenschutzkonform zu nutzen. Dabei können spezifische interne Wissensquellen wie SharePoint, OneDrive oder individuelle Dokumente effizient eingebunden werden.
Dank einer flexiblen Codebasis kann das System schnell auf unterschiedliche Anwendungsfälle angepasst werden. Funktionen wie die Feedback-Integration, das Budgetmanagement und die sichere Authentifizierung sorgen dafür, dass Unternehmen jederzeit die Kontrolle behalten – über sensible Daten und auch die Kosten. Damit bietet das System nicht nur eine praxisnahe Lösung für den Umgang mit Unternehmenswissen, sondern auch die nötige Transparenz und Sicherheit für eine nachhaltige Nutzung.
Sie sind neugierig geworden? Dann zeigen wir Ihnen in einem persönlichen Gespräch gerne unser System in einer Live-Demo und beantworten Ihre Fragen. Schreiben Sie uns einfach!
In der modernen Hochschulbildung sind die Optimierung und Personalisierung des Lernprozesses äußerst wichtig. Insbesondere in komplexen Studiengängen wie Jura können Technologien wie Large Language Models (LLMs) und Retrieval Augmented Generation (RAG) eine unterstützende Rolle spielen. Ein Pilotprojekt an der Universität Leipzig mit dem dortigen Rechenzentrum und der Juristenfakultät zeigt, wie diese Technologien erfolgreich in Form eines KI-Chatbots eingesetzt werden.
Hintergrund und Turing
Im Jahr 1950 stellte Alan Turing in seinem Essay „Computing Machinery and Intelligence“ die revolutionäre Frage: Können Maschinen denken? Er schlug das berühmte „Imitation Game“ vor, das heute als Turing-Test bekannt ist. Seiner Ansicht nach könnte eine Maschine als „denkend“ angesehen werden, wenn sie in der Lage ist, einen menschlichen Prüfer zu täuschen.
Dieser Gedanke bildet die theoretische Grundlage für viele moderne KI-Anwendungen. Seitdem ist ein langer Weg zurückgelegt worden, und insbesondere für Studierende eröffnen sich neue Möglichkeiten, KI-Tools wie z.B. LLMs im Rahmen ihres Studiums unterstürzend einzusetzen.
Wie funktioniert so ein Chatbot für das Jura-Studium?
Der KI-basierte Chatbot verwendet die fortschrittlichen Sprachmodelle von OpenAI, die so genannten ‘’Transformer’’. Diese Systeme, wie GPT-4, können mit der sogenannten „Retrieval Augmented Generation“ (RAG) Methode ergänzt werden, um korrekte Antworten auch auf komplexere juristische Fragen zu liefern. Der Prozess dahinter besteht aus mehreren Schritten:
1. Frage stellen (Query): Studierende stellen eine juristische Frage, z.B. “Was ist der Unterschied zwischen einer Hypothek und einer Sicherungsgrundschuld?“
2. Verarbeitung der Anfrage (Embedding): Die Frage wird in Vektoren umgewandelt, damit sie für das LLM lesbar werden und analysiert werden können.
3. Suche in Vektordatenbank:Das Retrieval-System sucht in einer Vektordatenbank nach relevanten Texten, die mit der Frage übereinstimmen. Diese können Skripte, Falllösungen oder Vorlesungsfolien sein.
4. Antwortgenerierung: Das LLM analysiert die gefundenen Daten und liefert eine präzise Antwort. Die Antwort kann mit Quellenangaben versehen werden, z.B. mit der Seite im Skript oder der entsprechenden Folie in der Vorlesung.
Für Jurastudierende ist dies ein mächtiges Tool, da sie nicht nur schnell Antworten auf sehr individuelle Fragen erhalten, sondern diese auch direkt auf die entsprechenden Lehrmaterialien verweisen. Dies erleichtert das Verständnis komplexer juristischer Konzepte und fördert das selbstständige Lernen.
Vorteile für Studierenden und Lehrenden
Chatbots bieten verschiedene Vorteile für das Lehren und Lernen an Universitäten. Für die Studierenden bedeutet dies:
Personalisierte Lernunterstützung: Die Studierenden können individuelle Fragen stellen und erhalten maßgeschneiderte Antworten.
Anpassung an unterschiedliche Themen: Man kann den Chatbot leicht an verschiedene Rechtsgebiete wie Zivilrecht, Strafrecht oder öffentliches Recht anpassen. Er kann auch schwierigere juristische Konzepte erklären oder bei der Prüfungsvorbereitung helfen.
Flexibilität und Kostentransparenz: Ob zu Hause oder unterwegs, der Chatbot steht jederzeit zur Verfügung und bietet Zugang zu den wichtigsten Informationen – über ein Learning Management System (LMS) wie Moodle oder direkt als App. Darüber hinaus sorgen monatliche Token-Budgets für eine klare Kostenkontrolle.
Auch für die Lehrenden bringt der Einsatz von LLMs in Kombination mit RAG Vorteile mit sich:
Unterstützung bei der Planung: KI-Tools können dabei helfen, Lehrveranstaltungen besser zu strukturieren.
Entwicklung von Lehrmaterialien: Die KI kann bei der Erstellung von Aufgaben, Lehrmaterialien, Fallbeispielen oder Klausurfragen unterstützen.
Herausforderungen beim Einsatz von LLMs
Trotz der vielen Vorteile und Möglichkeiten, die Chatbots und andere KI-basierte Lernsysteme bieten, gibt es auch Herausforderungen, die in Betracht gezogen werden müssen:
Ressourcenintensiv: Der Betrieb solcher Systeme erfordert einen hohen Rechenaufwand und verursacht entsprechende Kosten.
Abhängigkeit von Anbietern: Derzeit setzen viele solcher System auf Schnittstellen zu externen Anbietern wie Microsoft Azure oder OpenAI, was die Unabhängigkeit von Hochschulen einschränken kann.
Qualität der Antworten: KI-Systeme liefern nicht immer korrekte Ergebnisse. Es kann zu „Halluzinationen“ (falschen oder unsinnigen Antworten) kommen. Wie alle datenbasierten Systeme können auch LLMs Verzerrungen (Biases) aufweisen, die auf die verwendeten Trainingsdaten zurückzuführen sind. Daher muss sowohl die Genauigkeit der Antworten als auch die Vermeidung von Biases sichergestellt werden.
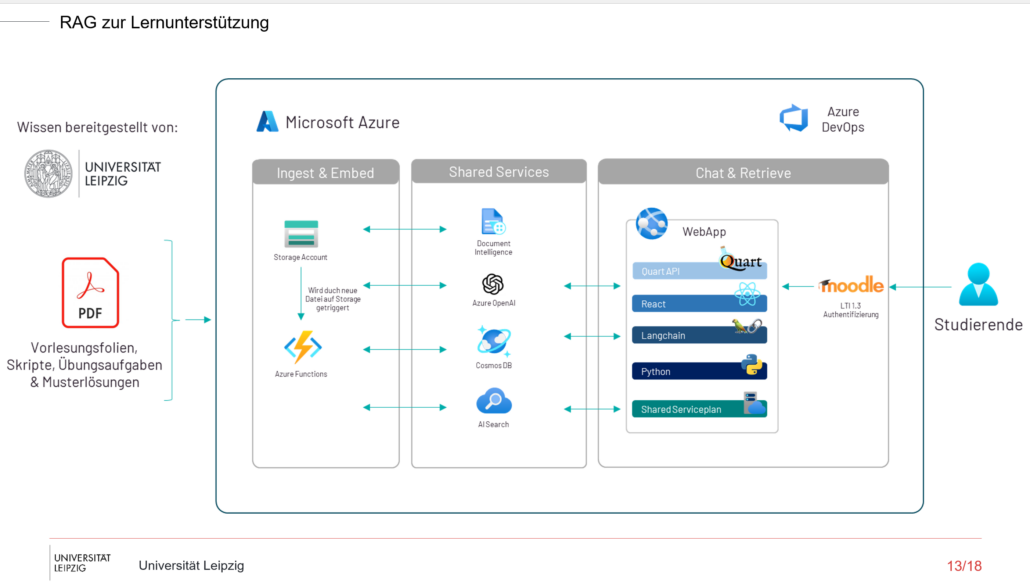
Der technische Hintergrund: Azure und OpenAI
Der oben vorgestellte Chatbot basiert auf der Cloud-Infrastruktur von Microsoft Azure. Azure bietet verschiedene Services, die eine sichere und effiziente Datenverarbeitung ermöglichen. Dazu gehören:
AI Search: Eine hybride Suche, die sowohl Vektorsuche als auch Volltextsuche kombiniert, um relevante Daten schnell zu finden..
Document Intelligence: Extrahiert Informationen aus PDF-Dokumenten und ermöglicht den direkten Zugriff auf Vorlesungsfolien, Skripte oder andere Lehrmaterialien.
OpenAI: Azure bietet Zugriff auf die leistungsfähigen Sprachmodelle von OpenAI. So wurden bei der Implementierung beispielsweise GPT-4 Turbo und das ada-002 Modell für Text Embeddings verwendet, um effizient korrekte Antworten zu generieren.
Darstellung des Datenverarbeitungsprozesses
Fazit
Das Pilotprojekt mit der Universität Leipzig zeigt wie der Einsatz von LLMs und RAG die Hochschulbildung unterstützen kann. Mithilfe dieser Technologien können Lernprozesse nicht nur effizienter, sondern auch flexibler und zielgerichteter gestaltet werden.
Durch den Einsatz von Microsoft Azure wird zudem eine sichere und DSGVO-konforme Datenverarbeitung gewährleistet.
Die Kombination aus leistungsfähigen Sprachmodellen und innovativen Suchmethoden bietet sowohl Studierenden als auch Lehrenden neue und effektive Wege, das Lernen und Lehren zu verbessern. Die Zukunft des Lernens wird damit personalisierbar, skalierbar und jederzeit verfügbar.
https://www.scieneers.de/wp-content/uploads/2024/11/aa.jpg413744Florence Lopezhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngFlorence Lopez2024-11-08 11:57:012024-12-12 16:25:00Wie Studierende von LLMs und Chatbots profitieren können
Wir waren für den zweiten Tag des diesjährigen Digital-Gipfels der Bundesregierung in Frankfurt am Main eingeladen. Ziel des Digital-Gipfels ist es, Menschen aus Politik, Wirtschaft, Forschung und Zivilgesellschaft zusammenzubringen, um Ideen, Lösungen und Herausforderungen in Bezug auf die digitale Transformation in Deutschland zu diskutieren.
Themen des Digital-Gipfels
Angeboten wurden verschiedene Vorträge und Diskussionsformate in Themenbereichen wie Vernetzte und datengetriebene Wirtschaft und Gesellschaft, Lernende Systeme und Kultur und Medien. So konnten wir beispielsweise mehr über die Organisation und Arbeitsweise der Datenlabore der Bundesregierung erfahren, die seit drei Jahren Datenprodukte und -projekte für die Bundesverwaltung umsetzen und damit den Einsatz von Daten und KI dort vorantreiben.
Ein weiteres wichtiges Thema war die Digitalisierungsstrategie der Bundesregierung, die Fortschritte und Herausforderungen aufzeigte, insbesondere hinsichtlich der Ausfinanzierung der sogenannten Leuchtturmprojekte und der Rolle des Beirats. Mehrere dieser Leuchtturmprojekte haben sich in anderen Sessions ebenfalls präsentiert und über ihre Arbeit informiert.
Pitch & Connect: Gemeinwohlorientierte KI-Projekte im Rampenlicht
Das Highlight für uns war das Event Pitch & Connect, bei dem sich 12 gemeinwohlorientierte KI-Projekte, die sich unter anderem mit Teilhabe, Desinformation oder Umwelt- und Wasserschutz befassen, einem engagierten Publikum vorstellen durften. Wir waren dort mit unserem Projekt StaatKlar: Dein digitaler Assistent für die Beantragung staatlicher Unterstützung vertreten.
StaatKlar dient dazu, Wissenslücken zu überbrücken und bürokratische Hürden bei der Beantragung staatlicher Ansprüche durch Bürger:innen abzubauen. Mit dem Talk to your Data-Ansatz, den wir bereits in vielen weiteren Projekten erfolgreich umgesetzt haben, werden für die Anwendung relevante Dokumente wie Informationsbroschüren zu staatlichen Leistungen als Datenbasis verwendet. Ein Large Language Model nutzt diese Datenbasis für die Generierung seiner Antworten. In der Folge können Bürger:innen in einer intuitiven webbasierten Chat-Anwendung mit dem Modell „sprechen“ und Antworten auf ihre Fragen und Hilfestellung zu ihren Herausforderungen in Bezug auf staatliche Unterstützung bekommen.
Mehr Informationen zu StaatKlar gibt es im 5-minütigen Pitch aus dem aufgezeichneten Livestream des Digital-Gipfels sowie einer kurzen Demo der Anwendung:
https://www.scieneers.de/wp-content/uploads/2024/10/20241022_161307-scaled-e1730281812544.jpg12242560Alexandra Wörnerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngAlexandra Wörner2024-10-31 12:50:032025-01-31 13:31:01KI für das Gemeinwohl auf dem Digital-Gipfel 2024
Vielen Unternehmen mangelt es nicht an Daten, sondern an Möglichkeiten diese zu verwalten und verfügbar zu machen. Eine besonders drängende Herausforderung ist der Wissenstransfer von älteren Mitarbeiter*Innen zur jüngeren Generation, der zum großen Teil von solchen Daten abhängig ist. Dabei geht es nicht nur um das in in Handbüchern dokumentierte Wissen sondern auch um das implizite Wissen, das „zwischen den Zeilen“ vorhanden ist – die Erkenntnisse und Erfahrungen, die in den Köpfe langjähriger Mitarbeiter*Innen stecken.
Diese Herausforderung besteht seit Jahren in vielen Branchen, und mit der rasanten Entwicklung von Künstlichen Intelligenz (KI), insbesondere der generativen KI, entstehen auch neue Möglichkeiten, dieses wertvolle Unternehmenswissen einzusetzen.
Der Aufstieg der generativen KI
Generative KI, insbesondere Large Language Models (LLMs) wie GPT-4o von OpenAI, Claude 3.5 Sonnet von Anthropic oder Llama3.2 von Meta, bieten neue Möglichkeiten, große Mengen unstrukturierter Daten zu verarbeiten und zugänglich zu machen. Mit diesen Modellen können Nutzer über Chatbot-Anwendungen mit Unternehmensdaten interagieren, wodurch der Wissenstransfer dynamischer und benutzerfreundlicher wird.
Die Frage ist jedoch, wie dem Chatbot die richtigen Daten zur Verfügung gestellt werden können. Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel.
Retrieval-Augmented Generation (RAG) für textuelle Daten
RAG hat sich als zuverlässige Lösung für den Umgang mit Textdaten erwiesen. Das Konzept ist einfach: Alle verfügbaren Unternehmensdaten werden in kleinere Datenblöcke (sogenannte Chunks) aufgeteilt und in (Vektor-)Datenbanken gespeichert, wo sie in numerische Embeddings umgewandelt werden. Wenn ein Benutzer eine Anfrage stellt, sucht das System nach relevanten Datenblöcken, indem es die Embeddings der Anfrage mit den gespeicherten Daten vergleicht.
Diese Methode erfordert kein Fine-Tuning der LLMs. Stattdessen werden relevante Daten abgerufen und an die Benutzeranfrage in der Prompt and das LLM angehängt, um sicherzustellen, dass die Antworten des Chatbots auf den unternehmensspezifischen Daten basieren. Dieser Ansatz funktioniert effektiv mit allen Arten von Textdaten, einschließlich PDFs, Webseiten und sogar mittels multimodaler Einbettung mit Bildern.
Auf diese Weise wird das in Handbüchern gespeicherte Unternehmenswissen für Mitarbeiter*Innen, Kunden oder andere Interessengruppen über KI-gestützte Chatbots leicht zugänglich.
Erweiterung des RAG um Videodaten
Während RAG für textbasiertes Wissen gut funktioniert, ist es für komplexe, prozessbasierte Aufgaben, die sich oft besser visuell darstellen lassen, nicht vollständig geeignet. Für Aufgaben wie die Wartung von Maschinen, bei denen es schwierig ist, alles durch schriftliche Anweisungen zu erfassen, bieten Video-Tutorials eine praktische Lösung, ohne dass zeitaufwändige Dokumentationen geschrieben werden müssen.
Videos bilden implizites Wissen ab, indem sie Prozesse Schritt für Schritt mit Kommentaren aufzeichnen. Im Gegensatz zu Text ist die automatische Beschreibung eines Videos jedoch alles andere als einfach. Selbst Menschen gehen hierbei unterschiedlich vor und konzentrieren sich oft auf unterschiedliche Aspekte desselben Videos, je nach Perspektive, Fachwissen oder Zielsetzung. Diese Variabilität verdeutlicht die Herausforderung, vollständige und konsistente Informationen aus Videodaten zu extrahieren.
Aufschlüsseln von Videodaten
Um das in den Videos enthaltene Wissen den Nutzern über einen Chatbot zugänglich zu machen, ist unser Ziel, einen strukturierten Prozess für die Umwandlung von Videos in Text bereitzustellen. Dabei steht die Extraktion möglichst vieler relevanter Informationen im Vordergrund.
Videos bestehen aus drei Hauptkomponenten:
Metadaten: Metadaten sind in der Regel einfach zu handhaben, da sie oft in strukturierter Textform vorliegen.
Audio: Audiodaten können mit Hilfe von Sprach-zu-Text (STT) Modellen wie Whisper von OpenAI in Text umgewandelt werden. Für branchenspezifische Kontexte ist es auch möglich, die Genauigkeit zu verbessern, indem benutzerdefinierte Terminologie in diese Modelle integriert wird.
Frames (visuelle Elemente): Die eigentliche Herausforderung besteht darin, die Frames (Bilder) sinnvoll in die Audiotranskription zu integrieren. Beide Komponenten sind voneinander abhängig – ohne Audiokommentare fehlt den Frames oft der Kontext und umgekehrt.
Bewältigung der Herausforderungen bei der Beschreibung von Videos
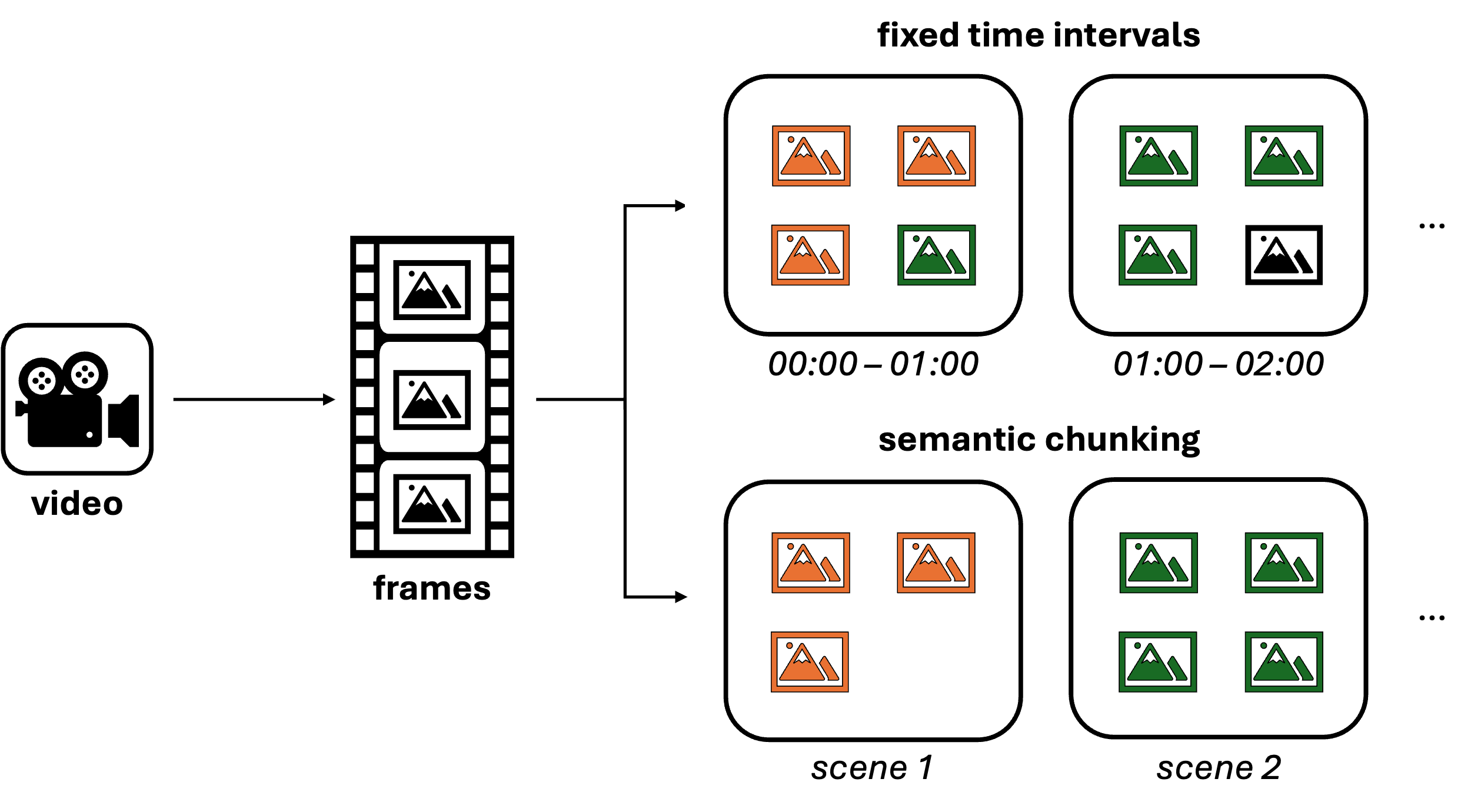
Abbildung 1: Chunking-Verfahren von VideoRAG.
Bei der Arbeit mit Videodaten bestehen drei wesentlichen Herausforderungen:
Beschreibung der einzelnen Bilder (Frames)
Erhaltung des Kontextes, da nicht jedes Bild unabhängig von den anderen relevant ist
Integration der Audiotranskription für ein besseres Verständnis des Videoinhalts
Um diese Probleme zu lösen, können multimodale Modelle wie GPT-4o verwendet werden, die sowohl Text als auch Bilder verarbeiten können. Durch die Verwendung von Videobildern und transkribiertem Audio als Input für diese Modelle kann eine vollständige Beschreibung von Videosegmenten erstellt werden.
Entscheidend ist jedoch, dass der Kontext zwischen den einzelnen Frames erhalten bleibt. Hier wird die Gruppierung von Frames (oft auch als Chunking bezeichnet) wichtig. Zwei Methoden, um Frames zu gruppieren sind:
Feste Zeitintervalle: Ein einfacher Ansatz, bei dem aufeinanderfolgende Frames auf der Grundlage vordefinierter Zeitintervalle gruppiert werden. Diese Methode ist einfach zu implementieren und für viele Anwendungsfälle gut geeignet.
Semantisches Chunking: Ein anspruchsvollerer Ansatz, bei dem Frames auf der Grundlage ihrer visuellen oder kontextuellen Ähnlichkeit gruppiert werden, um sie effektiv in Szenen zu organisieren. Es gibt verschiedene Möglichkeiten, semantisches Chunking zu implementieren, wie z.B. die Verwendung von Convolutional Neural Networks (CNNs) zur Berechnung der Ähnlichkeit von Frames oder die Verwendung von multimodalen Modellen wie GPT-4o zur Vorverarbeitung. Durch die Festlegung eines Ähnlichkeitsschwellenwertes können verwandte Bilder gruppiert werden, um das Wesentliche jeder Szene besser zu erfassen.
Sobald die Bilder gruppiert sind, können sie zu Bildrastern kombiniert werden. Diese Technik ermöglicht es dem Modell, die Beziehung und Abfolge zwischen verschiedenen Frames zu verstehen, während die narrative Struktur des Videos erhalten bleibt.
Die Wahl zwischen festen Zeitintervallen und semantischem Chunking hängt von den spezifischen Anforderungen des Anwendungsfalls ab. Unserer Erfahrung nach sind feste Intervalle für die meisten Szenarien ausreichend. Obwohl semantisches Chunking die zugrundeliegende Semantik des Videos besser erfasst, erfordert es die Abstimmung mehrerer Hyperparameter und kann ressourcenintensiver sein, da jeder Anwendungsfall eine eigene Konfiguration erfordern kann.
Mit zunehmender Leistungsfähigkeit von LLMs und der Zunahme von Kontextfenstern könnte man versucht sein, alle Bilder in einem einzigen Aufruf an das Modell zu übergeben. Dieser Ansatz sollte jedoch mit Vorsicht gewählt werden. Wenn zu viele Informationen auf einmal übergeben werden, kann das Modell überfordert werden und wichtige Details übersehen. Darüber hinaus sind aktuelle LLMs durch die Begrenzung ihrer Token-Ausgabe eingeschränkt (z.B. erlaubt GPT-4o 4096 Token), was die Notwendigkeit gut durchdachter Verarbeitungs- und Framing-Strategien noch unterstreicht.
Erstellung von Videobeschreibungen mit multimodalen Modellen
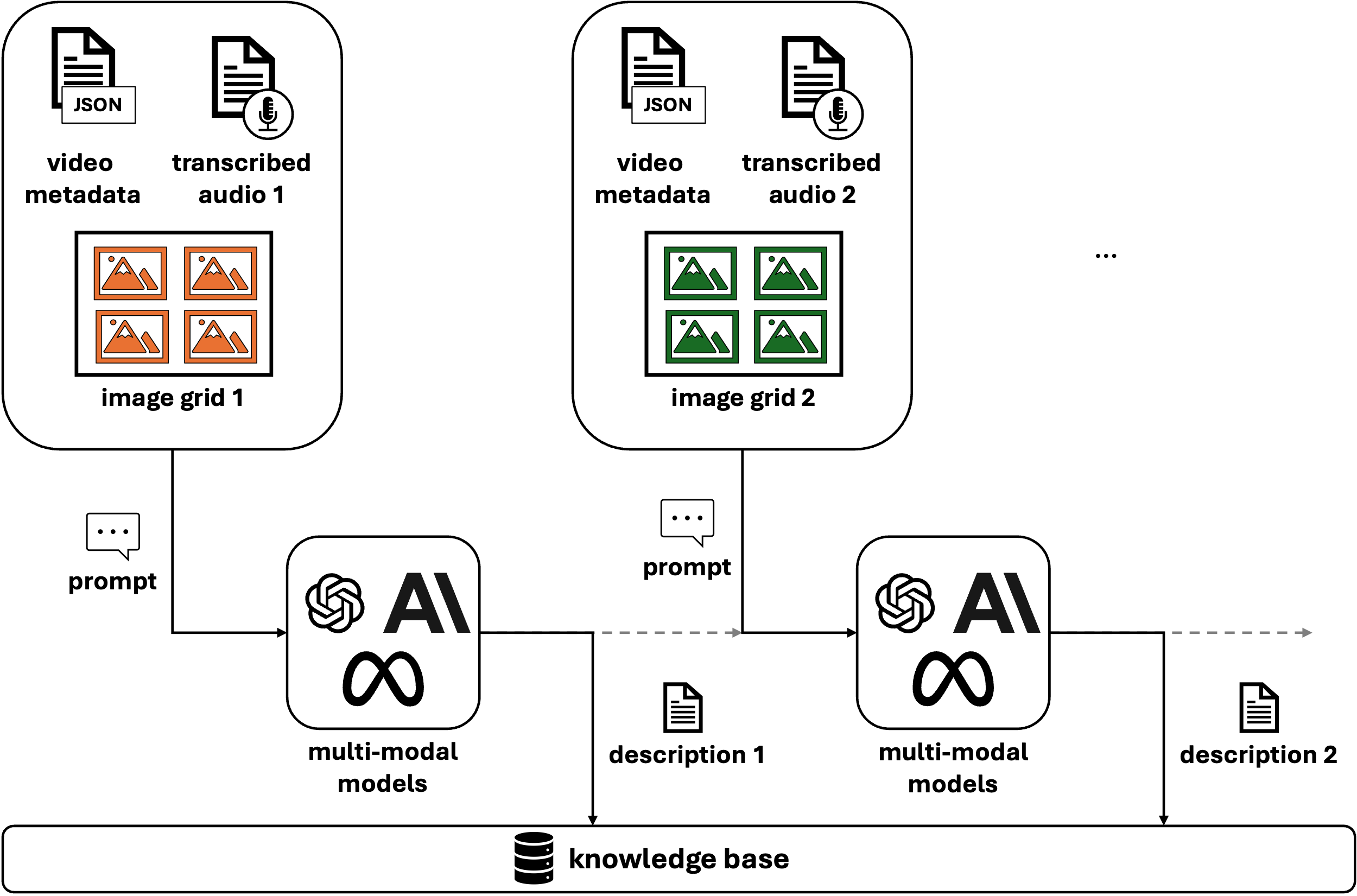
Abbildung 2: VideoRAG Ingestion Pipeline.
Sobald die Bilder gruppiert und mit der entsprechenden Audiotranskription verknüpft sind, kann das multimodale Modell geprompted werden, Beschreibungen für diese Teile des Videos zu erzeugen. Um die Kontinuität zu wahren, können Beschreibungen von früheren Teilen des Videos auf spätere Teile übertragen werden, so dass ein kohärenter Fluss entsteht (siehe Abbildung 2). Am Ende hat man Beschreibungen für jeden Teil des Videos, die zusammen mit Zeitstempeln in einer Wissensdatenbank gespeichert werden können, um eine einfache Referenz zu ermöglichen.
VideoRAG zum Leben erwecken
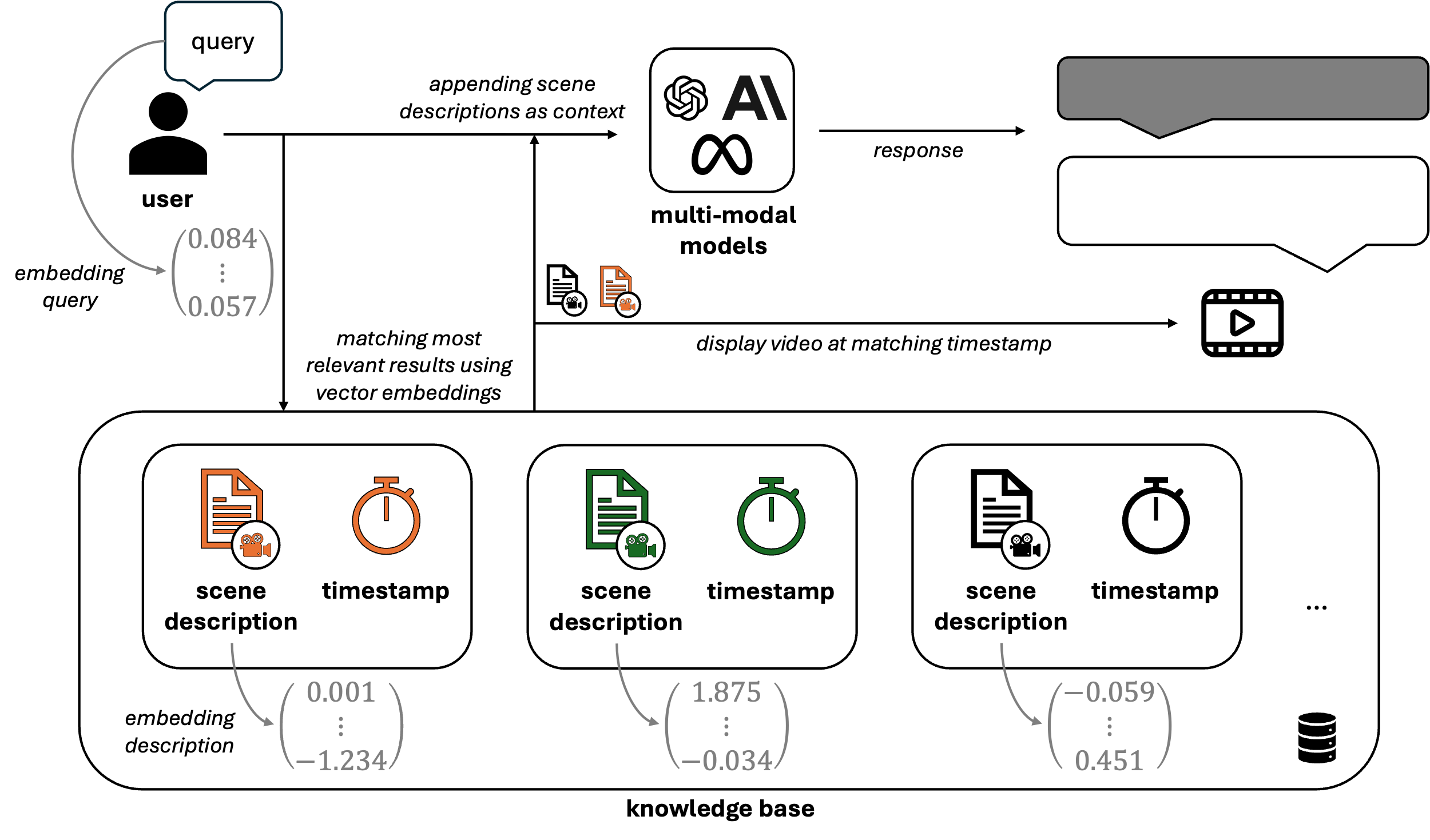
Abbildung 3: Retrieval-Prozess von VideoRAG.
Wie in Abbildung 3 dargestellt, werden alle Szenenbeschreibungen der in der Wissensbasis gespeicherten Videos in numerische Embeddings umgewandelt. Dies ermöglicht ein ähnliches Embedding der Benutzeranfragen und damit eine effiziente Suche nach relevanten Videoszenen anhand von Vektorähnlichkeiten (z.B. Kosinus-Ähnlichkeit). Sobald die relevantesten Szenen identifiziert sind, werden die entsprechenden Beschreibungen der Anfrage hinzugefügt, um dem LLM einen auf dem tatsächlichen Videoinhalt basierenden Kontext zu liefern. Zusätzlich zur generierten Antwort ruft das System die zugehörigen Zeitstempel und Videosegmente ab, so dass der Benutzer die Informationen direkt im Quellmaterial überprüfen und validieren kann.
Durch die Kombination von RAG-Technologien mit Videoverarbeitungsfunktionen können Unternehmen eine umfassende Wissensbasis aufbauen, die sowohl Text- als auch Videodaten enthält. Vor allem neu eingestellte Mitarbeiter*Innen können schnell auf kritische Erkenntnisse älterer Kollegen zugreifen – egal ob diese dokumentiert oder per Video demonstriert wurden – und so den Wissenstransfer effizienter gestalten.
Lessons Learned
Während der Entwicklung von VideoRAG hatten wir einige wichtige Learnings, von denen zukünftige Projekte in diesem Bereich profitieren können. Hier sind einige der wichtigsten Lektionen, die wir gelernt haben:
1. Optimierung der Prompts mit dem CO-STAR Framework
Wie bei den meisten Anwendungen, an denen LLMs beteiligt sind, hat sich das Prompt-Engineering als entscheidende Komponente für unseren Erfolg erwiesen. Die Erstellung präziser und kontextbezogener Eingabeaufforderungen hat einen großen Einfluss auf die Leistung des Modells und die Qualität der Ausgabe. Wir haben festgestellt, dass die Verwendung des CO-STAR Frameworks – eine Struktur, die den Schwerpunkt auf Context, Goal, Style, Tone, Audience und Response legt – einen soliden Leitfaden für das Prompt-Engineering darstellt.
Durch die systematische Berücksichtigung aller Elemente von CO-STAR konnten wir die Konsistenz der Antworten sicherstellen, insbesondere in Bezug auf das Format der Beschreibung. Durch die Verwendung dieser Struktur konnten wir zuverlässigere und individuellere Ergebnisse erzielen und Mehrdeutigkeiten in den Videobeschreibungen minimieren.
2. Einführung von Leitplanken zur Vermeidung von Halluzinationen
Einer der schwierigsten Aspekte bei der Arbeit mit LLM ist der Umgang mit ihrer Tendenz, Antworten zu generieren, auch wenn keine relevanten Informationen in der Wissensbasis vorhanden sind (sogenannte Hullunizationen). Wenn eine Frage außerhalb der verfügbaren Daten liegt, können LLMs auf Halluzinationen oder ihr implizites Wissen zurückgreifen, was oft zu ungenauen oder unvollständigen Antworten führt.
Um dieses Risiko zu verringern, haben wir einen zusätzlichen Überprüfungsschritt eingeführt. Bevor eine Benutzeranfrage beantwortet wird, lassen wir das Modell die Relevanz jedes aus der Wissensbasis abgerufenen Chunks bewerten. Wenn keine der abgerufenen Daten die Anfrage sinnvoll beantworten kann, wird das Modell angewiesen, nicht fortzufahren. Diese Strategie wirkt wie eine Leitplanke, die nicht fundierte oder sachlich falsche Antworten verhindert und sicherstellt, dass nur relevante und fundierte Informationen verwendet werden. Diese Methode ist besonders wirksam, um die Integrität der Antworten zu wahren, wenn die Wissensbasis keine Informationen zu bestimmten Themen enthält.
3. Umgang mit der Fachterminologie bei der Transkription
Ein weiterer kritischer Punkt war die Schwierigkeit der STT-Modelle, mit branchenspezifischen Begriffen umzugehen. Diese Begriffe, zu denen oft Firmennamen, Fachjargon, Maschinenspezifikationen und Codes gehören, sind für eine genaue Suche und Transkription unerlässlich. Leider werden sie oft missverstanden oder falsch transkribiert, was zu ineffektiven Suchen oder Antworten führen kann.
Um dieses Problem zu lösen, haben wir eine kuratierte Sammlung von branchenspezifischen Begriffen erstellt, die für unseren Anwendungsfall relevant sind. Durch die Integration dieser Begriffe in den Prompt des STT- Modells konnten wir die Qualität der Transkription und die Genauigkeit der Antworten erheblich verbessern. Das Whisper-Modell von OpenAI unterstützt z.B. die Einbeziehung domänenspezifischer Terminologie, wodurch wir den Transkriptionsprozess effizienter steuern und sicherstellen konnten, dass wichtige technische Details erhalten bleiben.
Fazit
VideoRAG ist der nächste Schritt in der Nutzung generativer KI für den Wissenstransfer, insbesondere in Branchen, in denen praktische Aufgaben mehr als nur Text zur Erklärung erfordern. Durch die Kombination von multimodalen Modellen und RAG-Techniken können Unternehmen sowohl explizites als auch implizites Wissen über Generationen hinweg effektiv bewahren und weitergeben.
https://www.scieneers.de/wp-content/uploads/2024/10/neu.jpg7581024Arne Grobrueggehttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngArne Grobruegge2024-10-23 09:15:402025-01-31 13:31:35Der Einsatz von VideoRAG für den Wissenstransfer im Unternehmen
Die neue Version der aus Azure bekannten Data Factory in Microsoft Fabric stand in letzter Zeit im Fokus zweier Vorträge, die scieneers auf renommierten Veranstaltungen präsentieren durften. Stefan Kirner hat auf der SQL Konferenz in Hanau, ausgerichtet von Datamonster, sowie auf den SQLDays, organisiert von ppedv, gesprochen.
Die Präsentation beleuchtete die technischen und konzeptionellen Unterschiede zwischen der Azure Data Factory und jener in Microsoft Fabric. Ebenso wurden die Auswirkungen dieser Unterschiede auf die Entwicklung sowie wichtige Aspekte des Application Lifecycle Managements beim Teamwork in Fabric thematisiert.
Hier eine kurze Zusammenfassung der gewonnenen Erkenntnisse:
Das Gute:
– Die Data Factory entwickelt sich weiter, bietet erweiterte Features und ist besser in das Gesamtsystem integriert.
– Das Software-as-a-Service Modell und ein berechenbares Preismodell erleichtern gerade Neulingen den Einstieg.
– Viel des bereits vorhandenen technischen Know-hows und Methodenwissens rund um die Azure Data Factory ist weiterhin anwendbar.
– Die Migration von bestehenden Data Engineering Projekten ist in den meisten Fällen problemlos möglich.
Das Schlechte:
– Für sehr kleine Projekte ist die Data Factory in Fabric nicht effizient einsetzbar.
– Spark Notebooks sind in den kleinsten verfügbaren Kapazitäten nicht wirklich nutzbar.
Das Hässliche:
– Es mangelt noch immer an Unterstützung für Git und Deployment Pipelines für Data Flows der zweiten Generation.
– Es existieren viele GUI Bugs und die Stabilität lässt zu wünschen übrig.
– Die noch eingeschränkte Anzahl von Datenquellen bei der Copy Activity führt zu Verwirrung.
Trotz der genannten Schwachstellen entwickelt sich Fabric in eine sehr positive Richtung. Microsoft arbeitet mit Hochdruck an den aktuellen Herausforderungen. Scieneers freut sich darauf, diese Technologie in zukünftigen Kundenprojekten weiterhin erfolgreich einzusetzen.
https://www.scieneers.de/wp-content/uploads/2024/10/stefan-kriner-sql-konferenz.png14862514Stefan Kirnerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngStefan Kirner2024-10-14 16:45:432025-01-31 13:32:21Data Factory in Fabric – the good, the bad and the ugly
Die Data2Day ist eine von wenigen deutschen Konferenzen, deren Thema nicht primär auf AI oder Machine Learning liegt, sondern sich dem Datenmanagement widmet. Sie wird vom Heise Verlag ausgerichtet und fand bereits zum achten Mal statt. Wir waren mit dabei und haben uns bemüht, mit unserem Vortrag eine Brücke zwischen beiden Themen zu schlagen: ‚SiloX-GPT: Daten-Silos verbinden mittels Multi-Agenten-System‘.
Unser Vortrag zu Multi-Agenten-Systemen
Unser Kollege Nico Kreiling beim präsentieren.
Gemeinsam mit Bertelsmann konnten wir die Ergebnisse unseres Content-Search Projektes vorstellen. In diesem Projekt lösen wir das Problem, dass es aufgrund der großen und verzweigten Firmenstruktur der sogenannten Berthelsphere keinen Ort gibt, wo sämtliche Daten der unterschiedlichen Bereiche entdeckt werden können. Wir lösen das Problem der sehr heterogenen Datenlandschaft dabei mit Hilfe von LLM-Agenten, welche mit Hilfe von Tools APIs abfragen, Knowledge-Graphs durchsuchen oder klassisches RAG durchführen können. Orchestriert wird all dies mit Hilfe von LangGraph, welches erlaubt Langchain-basierte Agenten und andere Verarbeitungsknoten in einem Kommunikationsgraphen frei zu modellieren. Neben der Vorstellung des Systems standen auch zahlreiche Learnings im Zentrum des Talks, denn in der ersten Zusammenarbeit zwischen Bertelsmann und Scieneers stand zunächst eine Evaluation der neuen technischen Möglichkeiten von LLMs im Zusammenspiel mit einem Knowledge-Graph im Vordergrund. Erst über mehrere Iterationen mit verschiedenen Stakeholdern hinweg entwickelte sich daraus die eigentliche Produktidee. Einige der wichtigen Learnings waren:
Technologie-Exploration und Produktentwicklung haben sehr unterschiedliche Anforderungen an Team, Organisationsform und Zielstellung
Tracing und Monitoring ist bei LLM-Applikationen mindestens so wichtig wie bei klassischer Softwareentwicklung, um ein resilientes und stabiles System zu entwickeln
Ein Multi-Agenten-Setup ähnelt einem Micro-Service-Design und bringt ähnliche Vorteile: Modulare Komponenten sorgen für bessere Wartbarkeit und Stabilität
LLM-Agenten sind mächtige Werkzeuge. Entscheidend ist dabei eine klare Ausrichtung des Prompts und der verwendeten Tools getreu dem UNIX-Motto: Do just one thing and do it well!
Die weiteren wichtigen Themen der Konferenz
Gefühlte Wahrnehmung von Data Science Teams Anfang 2023 (von Dr. Sarah Henni)
In der Eröffnungskeynote zeigte Dr. Sarah Henni von EnBW auf unterhaltsame Art den ChatGPT-Moment, als AI im Alltag vieler Menschen ankam und Postfächer von Data Science Abteilungen geflutet wurden. Seitdem wurden zahlreiche „Hook“-Projekte realisiert, die wichtig sind, um die neue Technologie zu erproben und ins Gespräch darüber zu kommen, wo nun die wirklichen Transformations-Potentiale liegen. Diese Einschätzung können wir nur bestätigen, denn nach vielen PoCs im Jahr 2023 liegt der Fokus dieses Jahr auch in unseren Projekten nun mehr auf Produktivierung, Stabilität und Resilienz. Außerdem haben immer mehr Projekte neben strategischen Zielen auch klare finanzielle KPIs.
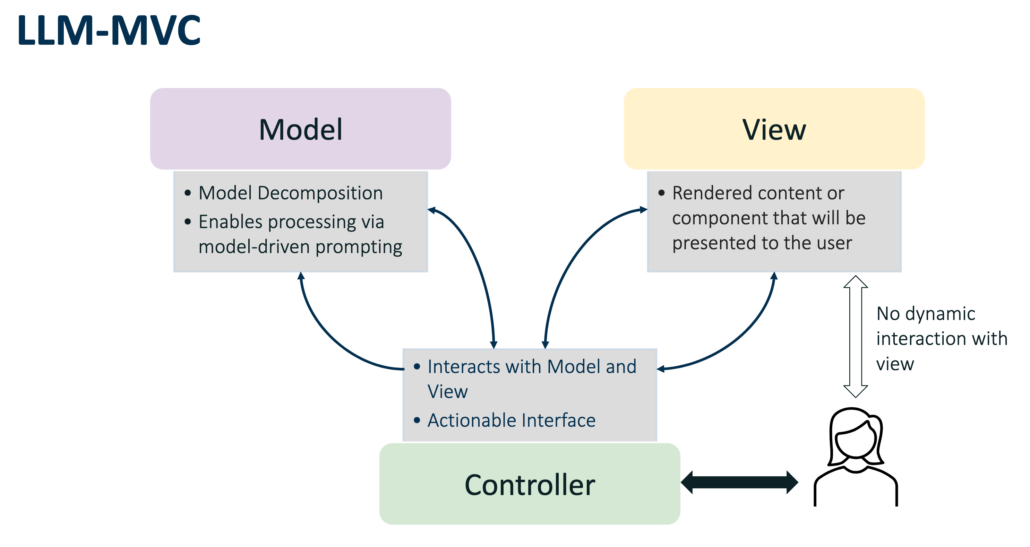
Schematische Darstellung des MVC-Pattern für LLMs nach Robert Bauer
Ein weiterer spannender Vortrag kam von Robert Bauer von der HMS Analytical Software. Er nutzte das aus der Applikationsentwicklung bekannte MVC-Pattern, um LLM-Applikationen zu strukturieren. Soll etwa ein Blog-Eintrag von einem LLM verfasst werden, so werden die einzelnen notwendigen Felder (wie Überschrift, Volltext, Excerpt, Tags, SEO-Text etc.) mit Hilfe von Pydantic als Modell repräsentiert. Die View hat dann ausschließlich die Aufgabe, dieses rein-textuelle Modell mit Hilfe von HTML-Templates in einen ansprechend formatierten Eintrag zu überführen. Der Controller übernimmt schließlich mit Hilfe unterschiedlicher, möglichst atomarer und damit besser promptbarer LLM-Calls das Befüllen des Modells.
Der Ansatz überzeugt vor allem, weil er bei der Strukturierung des Codes hilft und ermöglicht eine große LLM-Anfrage in mehrere kleinere, für das LLM besser verarbeitbare Abfragen zu zerlegen. Darüber hinaus lassen sich mit Hilfe des Modells abhängige Felder identifizieren (der SEO-Text hängt beispielsweise von Überschrift und Text ab), die automatisch als invalide markiert werden können, wenn sich im Abhängigkeitsbaum zuvor etwas geändert hat.
Natürlich haben auch bekannte Data Management Themen wie etwa Data Mesh, Knowledge Graphs oder Data Contracts das Programm der Data2Day bestimmt. Aber auch diese wurden entsprechend um AI erweitert: So zeigten die Macher von datacontract.com ihren GPT-Bot zur automatischen Erzeugung von Verträgen.
Zu guter Letzt war auch der AI-Act ein wichtiges Thema der Konferenz. Gut gefallen hat uns hier vor allem die Sichtweise von Larysa Visengeriyeva, die ihn im Wesentlichen als rechtliche Verpflichtung von Software-Best-Practices (wie etwa Transparenz, Erklärbarkeit, Data Governance, Fehlertoleranz/Resilienz, Dokumentation) für AI darstellte.
Bei der Gelegenheit wollen wir uns abschließend beim Heise Verlag für die Durchführung der gelungenen Konferenz und das Vernetzen der vielen engagierten Sprecher und Teilnehmer bedanken.
https://www.scieneers.de/wp-content/uploads/2024/09/DPK_9954-scaled.jpg17092560Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2024-09-24 16:24:462025-01-31 13:32:52Multi-Agenten LLM auf der Data2Day
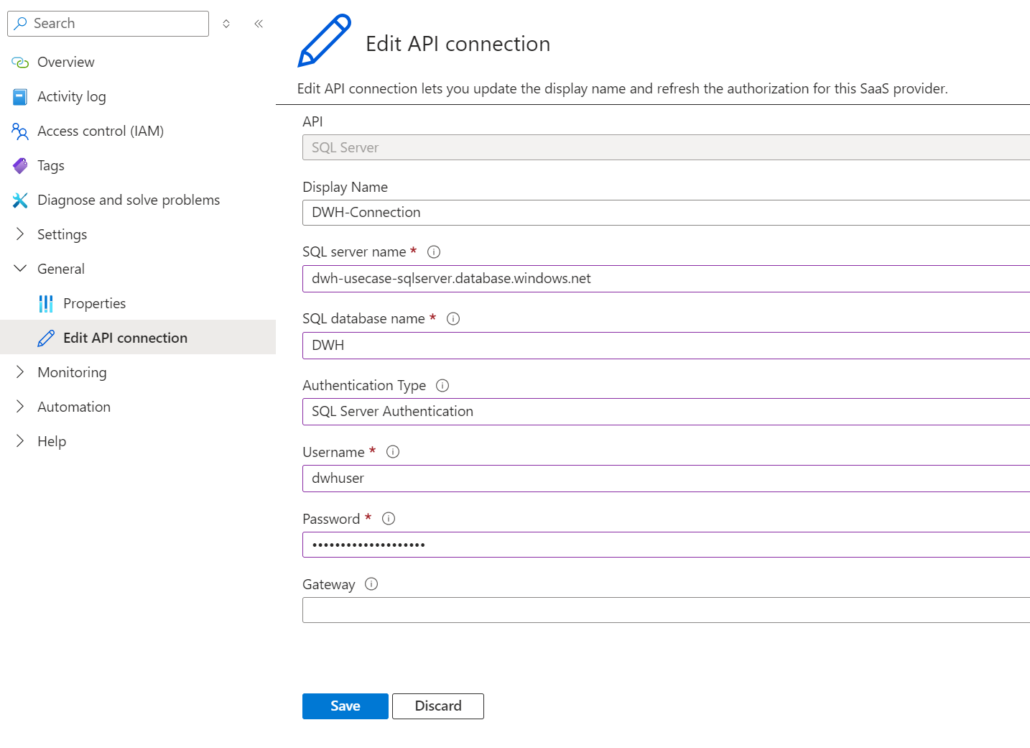
API-Connections sind ein essenzieller Bestandteil von Azure Logic Apps, einer cloudbasierten Plattform zur Erstellung und Verwaltung automatisierter Workflows. Sie können als Brücke zwischen Logic Apps und externen Diensten oder APIs gesehen werden. Sie ermöglichen es, auf externe Datenquellen und Ressourcen wie Datenbanken, Web-APIs, SaaS-Anwendungen (z. B. Salesforce, Office 365) und andere Dienste zuzugreifen und diese in automatisierte Prozesse einzubinden.
API-Connections sind eigenständige Azure-Ressourcen, die innerhalb derselben Ressourcengruppe der Logic App erstellt werden. Dadurch können auch andere Logic Apps dieser Ressourcengruppe auf dieselbe API-Connection zugreifen und sie gleichermaßen nutzen.
Wie erstellt man eine API-Connection?
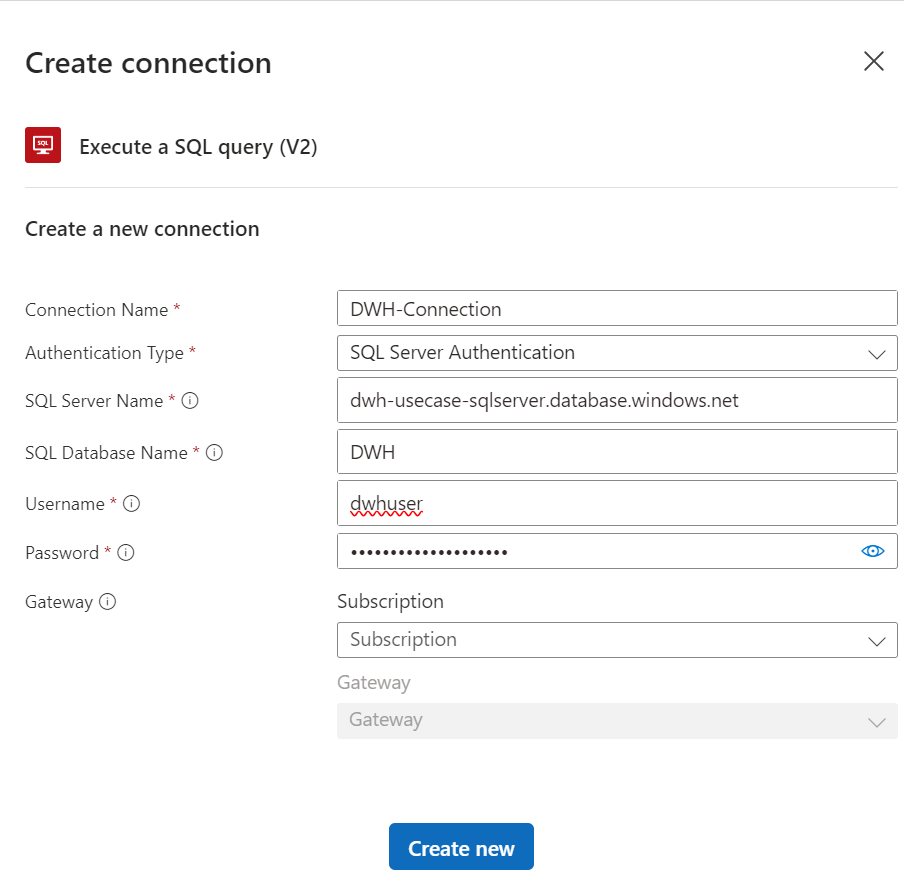
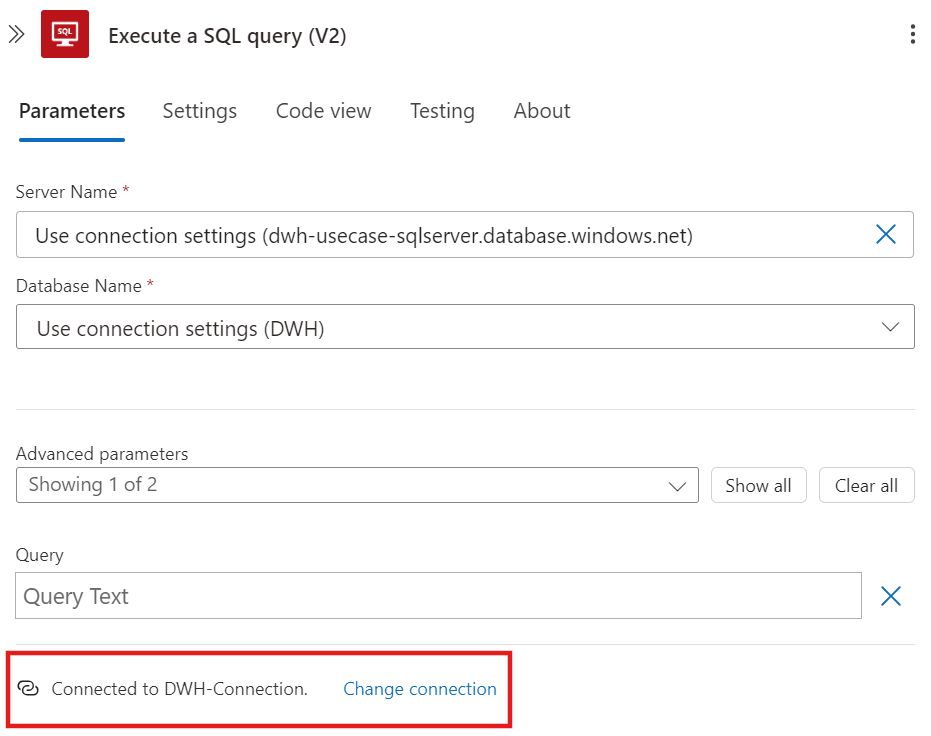
Um eine API-Connection manuell zu erstellen, wählt man innerhalb eines Workflows eine Aktion aus. Falls noch keine API-Connection angelegt ist, öffnet sich ein Dialogfenster, durch das man unter Angabe der korrekten Verbindungsdaten eine API- Connection anlegen kann:
Nach dem Anlegen der API-Connection erscheint diese mit dem vorher definierten Namen in der Aktion und kann künftig auch für weitere Aktionen Logic App-übergreifend in der gleichen Ressourcegruppe verwendet werden:
Obwohl API-Connections eigenständige Azure Ressourcen darstellen, können sie nicht manuell über das Azure Portal angelegt werden, sondern nur innerhalb einer Logic App.
Potenzielle Probleme
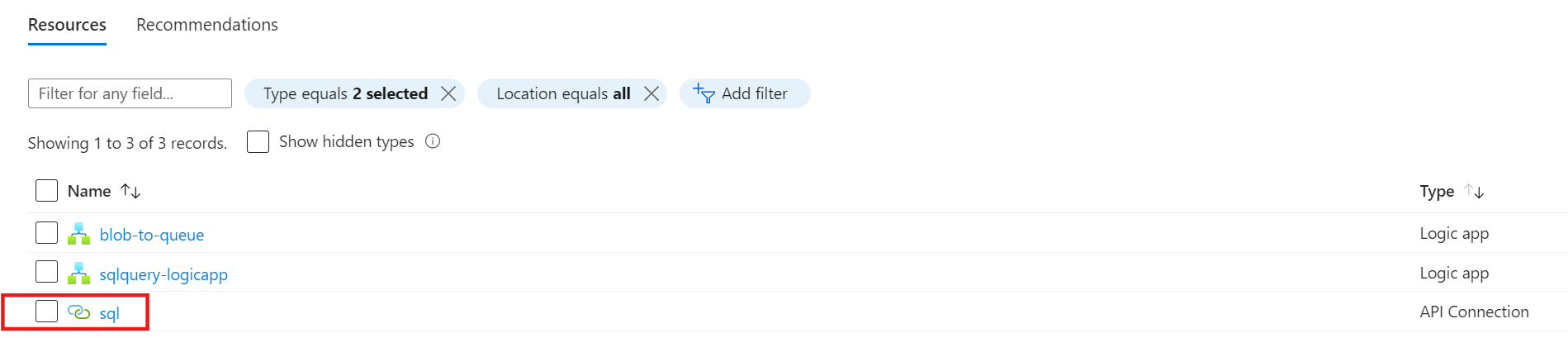
Wie bereits beschrieben, sind API-Connections eigenständige Azure Ressourcen und werden somit auch als solche angelegt. Bei der Erstellung der API-Connection wird ein Name definiert. Man könnte annehmen, dass er auch der Ressourcenname der API-Connection ist, welches leider nicht der Fall ist:
Die erstellte API-Connection bekommt einen generischen Ressourcennamen basierend auf der Verbindungsart. Dadurch hat sie zwei Namen: 1) einen internen Namen, der nur innerhalb der Logic App sichtbar ist, und 2) einen Ressourcennamen, der sowohl innerhalb als auch außerhalb der Logic App sichtbar ist. Unschön, aber bisher kein Problem. Falls man nun eine zweite Datenquelle des gleichen Typs anbinden möchte, so wird eine neue API-Connection erstellt und von Azure entsprechend benannt:
Diese Art der Benennung kann beispielsweise bei einer zunehmenden Anzahl von API-Connections die Übersichtlichkeit beinträchtigen und die Ressourcengruppe mit API-Connections überschwemmen, die möglicherweise gar nicht verwendet werden oder versehentlich angelegt wurden.
Zudem kann die Benennung bei der Integration in einen CI/CD-Prozess, je nach Setup, Probleme verursachen. Es könnte dadurch z.B. unklar werden, welche API-Connection für eine DEV/UAT/PROD Ressource steht, welche veraltet ist, etc.
Leider gibt es aktuell keine Möglichkeit mehr, eine API-Connection über die grafische Oberfläche im Azure Portal umzubenennen.
API-Connections können aber über ihr ARM-Template unter geändertem Namen neu deployed werden, was somit verschiedene Möglichkeiten eröffnet. Diese Möglichkeiten wollen wir uns in dem folgenden Abschnitt anschauen.
Deployment über das Azure Portal & Probleme
Eine Möglichkeit ist, das Deployment direkt über die Benutzeroberfläche des Azure Portal vorzunehmen.
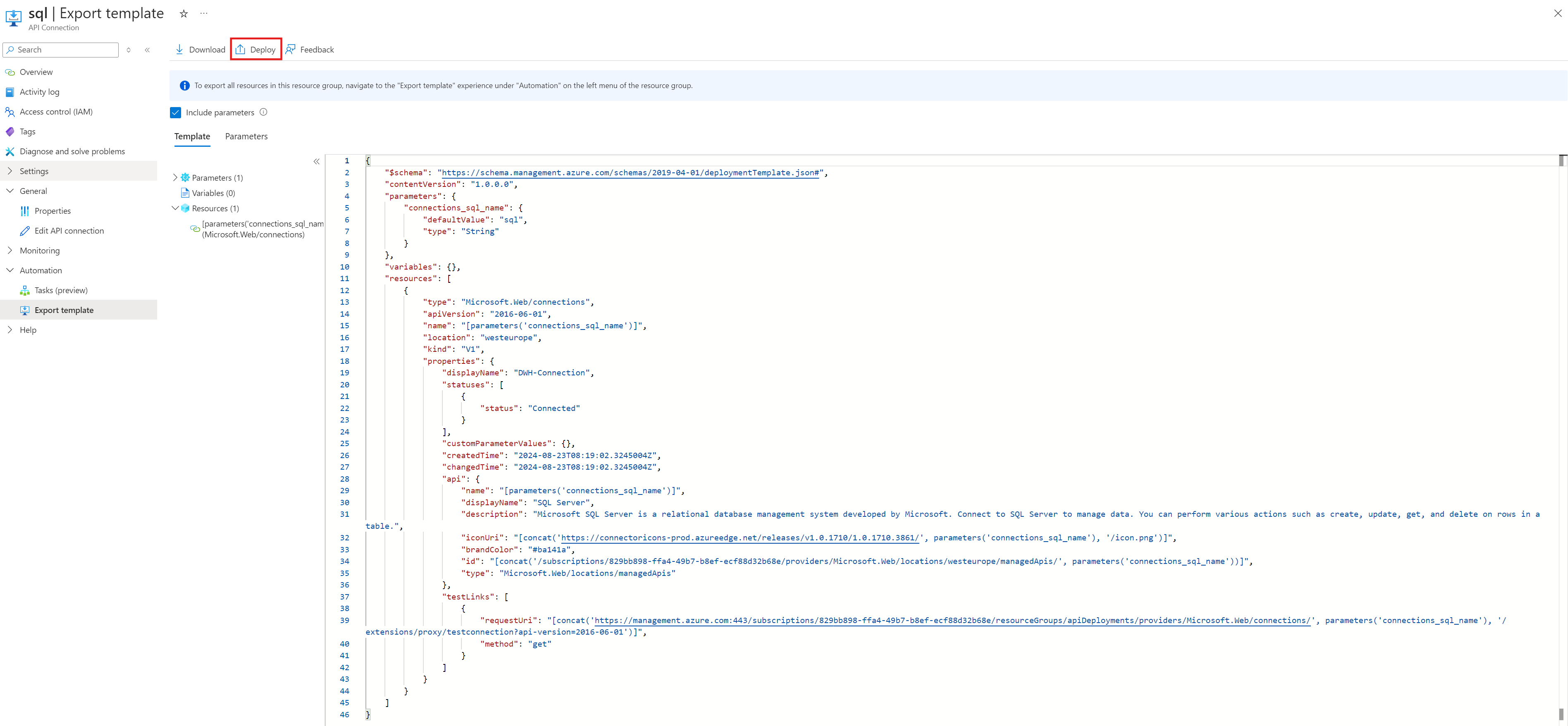
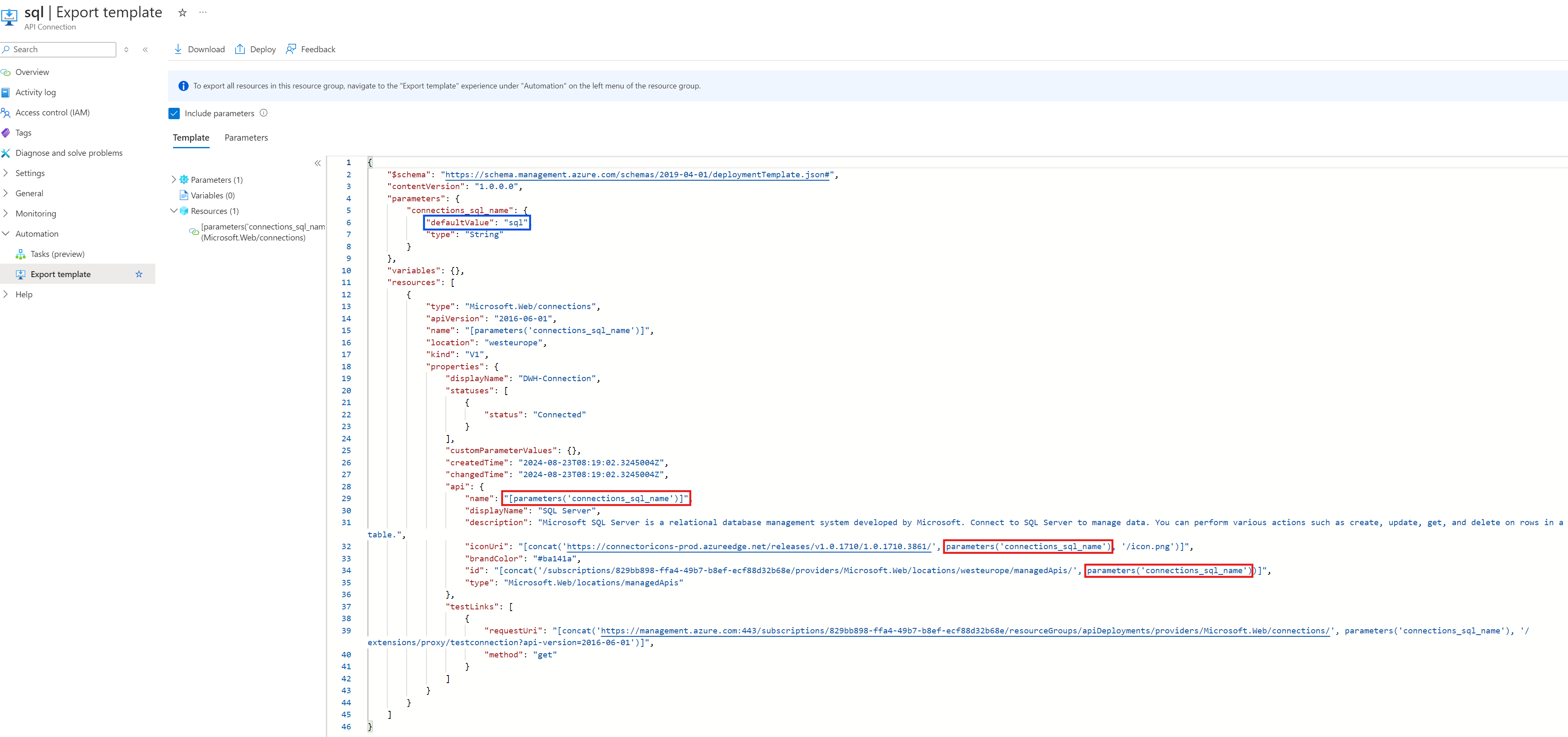
Hierzu wird die gewünschte API-Connection und ihr ARM-Template über den Menü-Punkt „Export Template“ geöffnet. Da das ARM-Template in dieser Ansicht schreibgeschützt ist, wählt man „Deploy“ und dann „Edit Template“ aus, um zu einer editierbaren Ansicht des ARM-Templates zu kommen.
Hier öffnet sich ein neues Dialogfenster, in dem man einige Änderungen für ein valides ARM-Template vornehmen muss. Im Parameter-Objekt muss der Value für „defaultValue“ (blau umrandet) zum gewünschten API Connection Namen geändert werden.
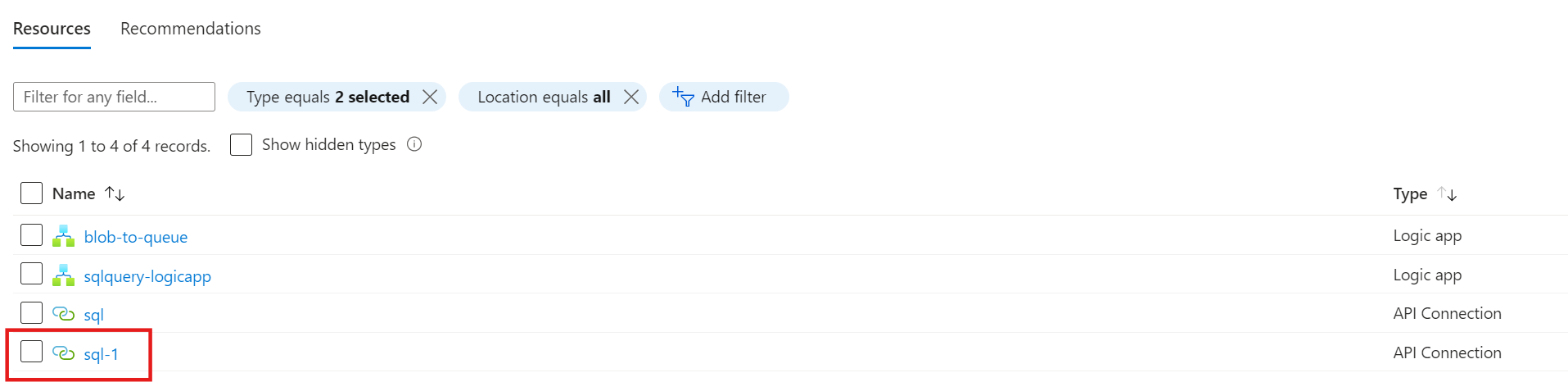
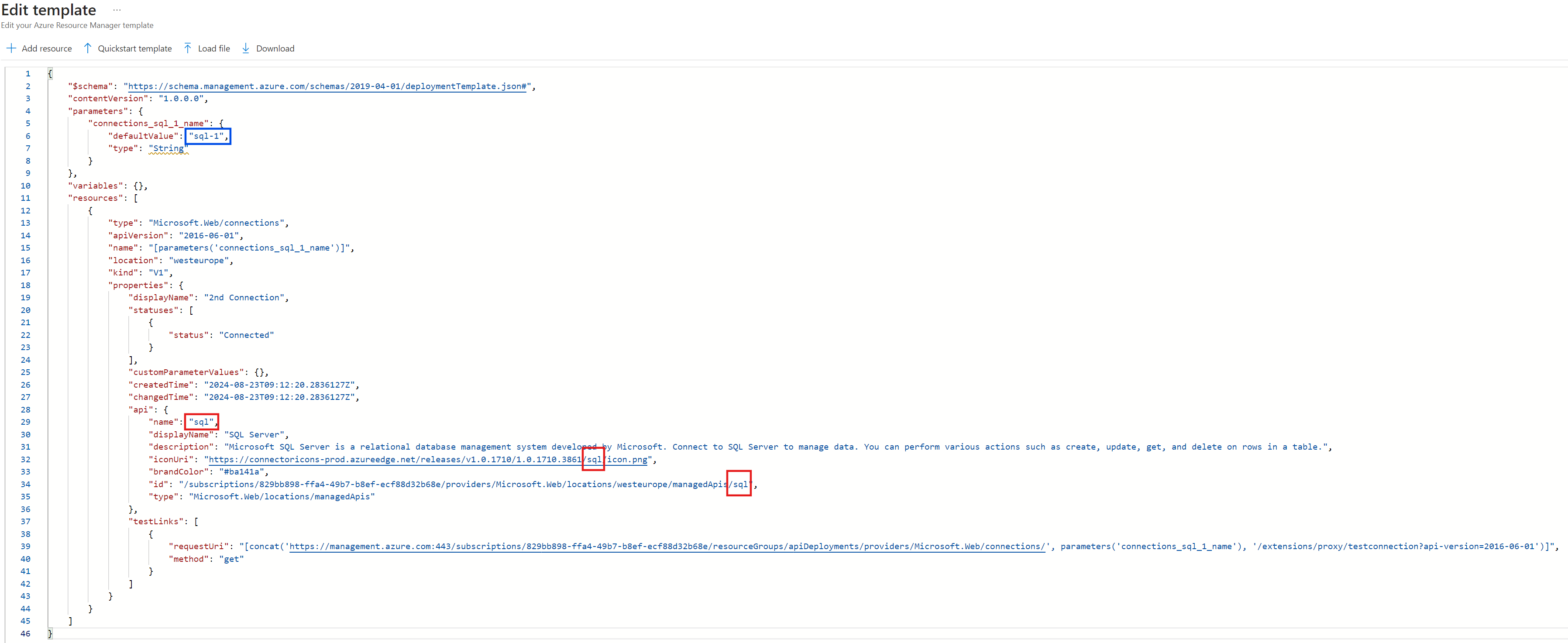
Da „defaultValue“ im api-Objekt referenziert wird (rot umrandet), muss die Referenz durch die Art der Connection, hier sql, ersetzt werden.
Das Referenzieren des „defaultValues“ findet man logischerweise nur im api-Objekt, wenn die API-Connection wie die Art der Connection (z.B. sql) heißt. Wenn die umzubenennende API-Connection z.B. „sql-1“ heißt, werden die vorherigen Parameterreferenzen hartkodiert:
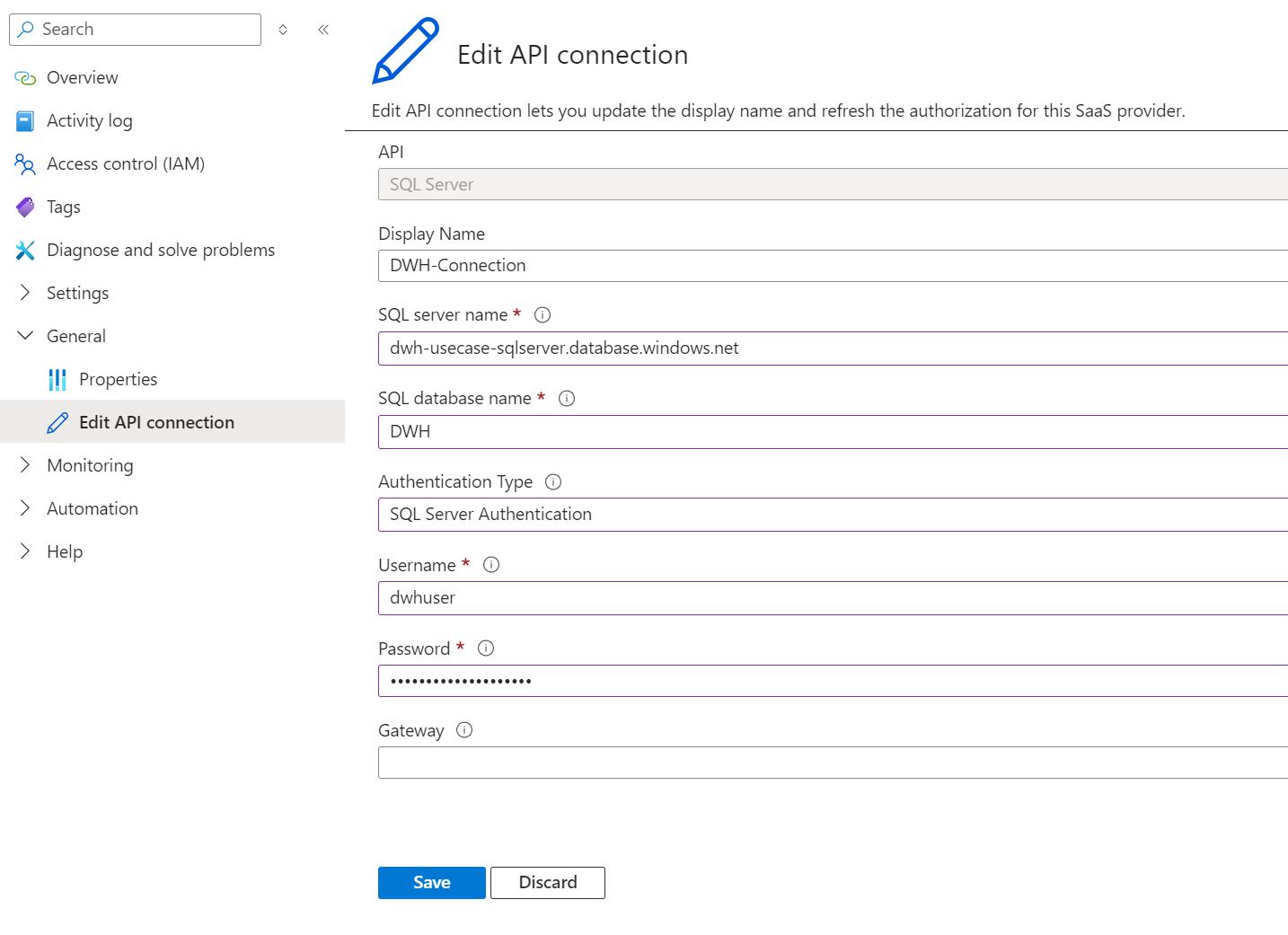
Nach dem Deployment der neuen API-Verbindung wird schnell klar, dass diese noch keine Verbindung zur gewünschten Quelle herstellen kann, da keine Zugangsdaten oder sonstige Authentifizierungsinformationen im ARM-Template enthalten bzw. übergeben worden sind. Diese Informationen müssen manuell über die Benutzeroberfläche des Azure Portals hinzugefügt werden:
Mögliche Probleme
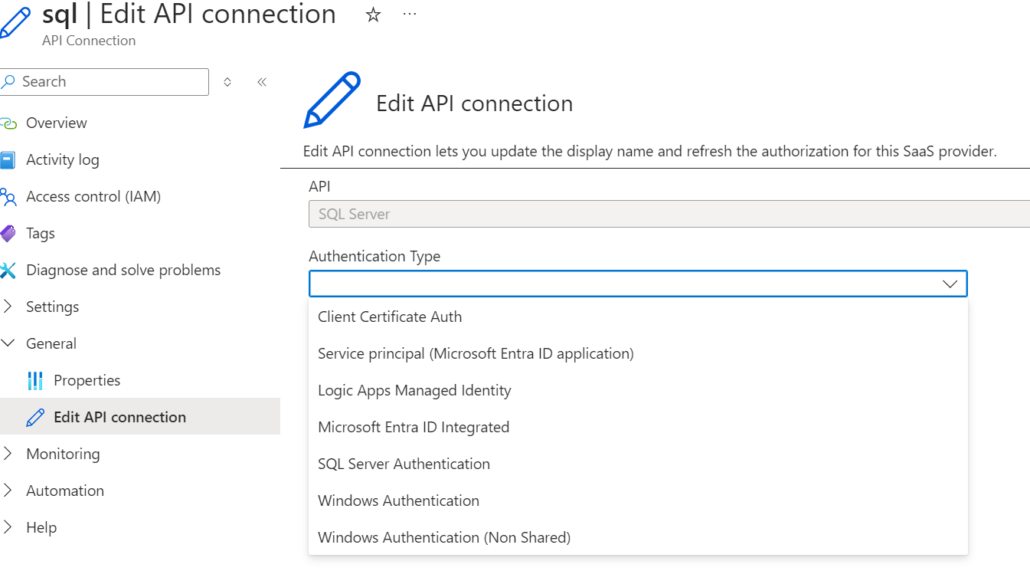
Ein Problem bei dieser Art der Bereitstellung von API-Connections ist, dass bestimmte Konfigurationen, wie der „Authentication Type“, fest vom vorherigen Template übernommen werden. Im Vergleich zu den manuell erstellten API-Connections, die angepasst werden können, sind sie nicht mehr flexibel. Dies kann insbesondere dann problematisch werden, wenn die Sicherheitsanforderungen sich ändern und der Authentifizierungstyp entsprechend angepasst werden muss.
Automatisch erstellte API-Connection vs. Custom ARM-Template Deployment
Um die oben genannten Einschränkungen zu überwinden, kann das ParameterValueSet-Objekt im properties-Objekt des ARM-Templates hinzugefügt werden. Dieses Objekt ermöglicht eine flexible Konfiguration der API-Verbindung.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"connections_cooleAPI_name": {
"defaultValue": "cooleAPI",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.Web/connections",
"apiVersion": "2016-06-01",
"name": "[parameters('connections_cooleAPI_name')]",
"location": "westeurope",
"kind": "V1",
"properties": {
"displayName": "DWH-Connection",
"statuses": [
{
"status": "Connected"
}
],
"parameterValueSet": {
"name": "placeholder",
"values": {}
},
"customParameterValues": {},
"createdTime": "2024-08-27T06:40:25.2075565Z",
"changedTime": "2024-08-27T07:44:30.0313207Z",
"api": {
"name": "sql",
"displayName": "SQL Server",
"description": "Microsoft SQL Server is a relational database management system developed by Microsoft. Connect to SQL Server to manage data. You can perform various actions such as create, update, get, and delete on rows in a table.",
"iconUri": "https://connectoricons-prod.azureedge.net/releases/v1.0.1710/1.0.1710.3861/sql/icon.png",
"brandColor": "#ba141a",
"id": "/subscriptions/829bb898-ffa4-49b7-b8ef-ecf88d32b68e/providers/Microsoft.Web/locations/westeurope/managedApis/sql",
"type": "Microsoft.Web/locations/managedApis"
},
"testLinks": [
{
"requestUri": "[concat('https://management.azure.com:443/subscriptions/829bb898-ffa4-49b7-b8ef-ecf88d32b68e/resourceGroups/apiDeployments/providers/Microsoft.Web/connections/', parameters('connections_cooleAPI_name'), '/extensions/proxy/testconnection?api-version=2016-06-01')]",
"method": "get"
}
]
}
}
]
}
Das parameterValueSet-Objekt wird in ARM-Templates eigentlich verwendet, um Parameterwerte einer API-Connection zu definieren und zu konfigurieren. Es besteht hauptsächlich aus zwei Komponenten:
name: Der Name der Connection-Art, z.B. „keyBasedAuth “, „managedIdentityAuth“, etc. In der Regel entspricht der Name also einer vordefinierten Gruppe von Werten, die von der API erwartet werden.
values: Das Kernstück des parameterValueSet-Objekts, da es die tatsächlichen Verbindungsdaten enthält, die für die API-Connection benötigt werden.
Da wir in unserem Beispiel keine Credentials im Code übergeben wollen, sondern diese wie bisher über die Benutzeroberfläche im Azure Portal setzen wollen, lassen wir das Values-Objekt leer und übergeben dem name-Key einen zufälligen Wert.
Nach dem Deployment kann man nun die Verbindungsdaten hinzufügen, wie in den vorherigen Schritten schon beschrieben.
Deployment mit einem PowerShell Skript
Um die Fehleranfälligkeit zu reduzieren und repetitive Arbeit zu vermeiden, können einige der bisher händisch ausgeführten Schritte mithilfe eines PowerShell Skriptes automatisiert werden. Das nachfolgende Skript führt unter der Angabe von Daten (Subscription Id, Name der Ressourcengruppe, Connection Name, etc.) folgende Aufgaben aus und erzielt das gleiche Ergebnis wie das händisch bearbeitete ARM-Template:
Herunterladen des ARM-Templates einer angegebenen API-Connection
Ändern des defaultValues in den gewünschten API-Connection Namen
Ersetzen von Parameterreferenzen im API-Objekt
Hinzufügen des ParameterValueSet-Objekts
Deployment der API-Connection in der angegebenen Ressourcengruppe unter dem angegeben Ressourcennamen
Nachdem das Skript erfolgreich durchgelaufen ist, erscheint die API-Connection in der gewünschten Ressourcengruppe. Jetzt müssen die Verbindungsdaten noch manuell über das Azure Portal gesetzt werden, bevor die API-Connection einsatzbereit ist.
$subscriptionId = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" # Your SubscriptionId
$rg = "apiDeployments"
$apiConnectionName = "sql"
$newApiConnectionName = "sql_dev"
$connectionType = "sql" # z.B. sql, azureblob, ftp
#SetContext
Set-AzContext -Subscription $subscriptionId
#Export template
$APIConnectionID=$(az resource show --resource-group $rg --name $apiConnectionName --resource-type Microsoft.Web/connections --query id --output tsv)
az group export --resource-group $rg --resource-ids $APIConnectionID > template.json
# Load JSON content into a variable
$jsonFile = "template.json"
$jsonContent = Get-Content -Path $jsonFile -Raw | ConvertFrom-Json
#Build ParameterName
$parameterConnectionName = $apiConnectionName.Replace('-','_')
$ParameterName = "connections_${parameterConnectionName}_name"
# Check if the 'defaultValue' property exists and add it if necessary
if (-not $jsonContent.parameters.$ParameterName.PSObject.Properties['defaultValue']) {
# Add the 'defaultValue' property with the desired value
$jsonContent.parameters.$ParameterName | Add-Member -MemberType NoteProperty -Name defaultValue -Value $NewApiConnectionName
} else {
# If exists, just update the value
$jsonContent.parameters.$ParameterName.defaultValue = $newApiConnection
}
# Access the specific resource and add the parameterValueSet if it doesn't exist
$jsonResource = $jsonContent.resources[0] # Assuming there's only one resource in the array
# Check if 'parameterValueSet' exists & add the 'parameterValueSet' property
if (-not $jsonResource.properties.PSObject.Properties['parameterValueSet']) {
$parameterValueSet = @{
name = "hasToBeSetInThePortal"
values = @{}
}
$jsonResource.properties | Add-Member -MemberType NoteProperty -Name parameterValueSet -Value $parameterValueSet
}
# Update the api properties (only if API Connectionname = ConnectionType)
if ($apiConnectionName -eq $connectionType) {
$jsonResource.properties.api.name = $ConnectionType
$jsonResource.properties.api.iconUri = $jsonResource.properties.api.iconUri -replace [regex]::Escape("parameters('$($ParameterName)')"), "'$($ConnectionType)'"
$jsonResource.properties.api.id = $jsonResource.properties.api.id -replace [regex]::Escape("parameters('$($ParameterName)')"), "'$($ConnectionType)'"
}
# Convert the modified JSON back to a string
$updatedJsonContent = $jsonContent | ConvertTo-Json -Depth 10
# Save the updated JSON back to the file
Set-Content -Path $jsonFile -Value $updatedJsonContent
# Deploy the new Api Connection
New-AzResourceGroupDeployment -Mode Incremental -Name "${NewApiConnectionName}-Deployment" -ResourceGroupName $rg -TemplateFile $jsonFile
Write-Host 'Deployment done'
Fazit:
API-Connections sind ein unverzichtbarer Bestandteil von Azure Logic Apps, da sie die Integration und den Zugriff auf externe Dienste und Datenquellen ermöglichen. Wenn jedoch zahlreiche verschiedene Datenquellen genutzt werden, kann die Verwaltung der API-Connections schnell unübersichtlich und komplex werden. Die in diesem Blog-Post beschriebenen Methoden bieten Strategien, um Struktur in die Verwaltung zu bringen und die Übersichtlichkeit zu verbessern, indem sie es erlauben entsprechende Ressourcennamen für API-Connections zu setzen
Darüber hinaus eröffnen diese Ansätze die Möglichkeit, Skripte und Methoden weiterzuentwickeln, um beispielsweise API-Connections nahtlos in CI/CD-Prozesse zu integrieren und automatisch mit den benötigten Verbindungsdaten zu deployen.
https://www.scieneers.de/wp-content/uploads/2024/09/Unbenannt.png10801920Maximilian Leisthttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngMaximilian Leist2024-09-20 16:23:142025-01-31 13:33:43Logic App API Connections – Herausforderungen und Lösungswege in der Verwaltung
Einblicke in die European Society of Human Genetics (ESHG) 2024 – eine beeindruckende, hybriden Veranstaltung, die Tausende von Besuchern aus aller Welt anlockte.
https://www.scieneers.de/wp-content/uploads/2024/06/53782461515_2a32608750_k.jpg13202048Martin Dannerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngMartin Danner2024-06-11 14:48:302024-06-14 09:30:44Einblicke in die European Society of Human Genetics Konferenz 2024




































 European Society of Human Genetics
European Society of Human Genetics