

Der Einsatz von VideoRAG für den Wissenstransfer im Unternehmen
Der Wissenstransfer als Herausforderung
Vielen Unternehmen mangelt es nicht an Daten, sondern an Möglichkeiten diese zu verwalten und verfügbar zu machen. Eine besonders drängende Herausforderung ist der Wissenstransfer von älteren Mitarbeiter*Innen zur jüngeren Generation, der zum großen Teil von solchen Daten abhängig ist. Dabei geht es nicht nur um das in in Handbüchern dokumentierte Wissen sondern auch um das implizite Wissen, das „zwischen den Zeilen“ vorhanden ist – die Erkenntnisse und Erfahrungen, die in den Köpfe langjähriger Mitarbeiter*Innen stecken.
Diese Herausforderung besteht seit Jahren in vielen Branchen, und mit der rasanten Entwicklung von Künstlichen Intelligenz (KI), insbesondere der generativen KI, entstehen auch neue Möglichkeiten, dieses wertvolle Unternehmenswissen einzusetzen.
Der Aufstieg der generativen KI
Generative KI, insbesondere Large Language Models (LLMs) wie GPT-4o von OpenAI, Claude 3.5 Sonnet von Anthropic oder Llama3.2 von Meta, bieten neue Möglichkeiten, große Mengen unstrukturierter Daten zu verarbeiten und zugänglich zu machen. Mit diesen Modellen können Nutzer über Chatbot-Anwendungen mit Unternehmensdaten interagieren, wodurch der Wissenstransfer dynamischer und benutzerfreundlicher wird.
Die Frage ist jedoch, wie dem Chatbot die richtigen Daten zur Verfügung gestellt werden können. Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel.
Retrieval-Augmented Generation (RAG) für textuelle Daten
RAG hat sich als zuverlässige Lösung für den Umgang mit Textdaten erwiesen. Das Konzept ist einfach: Alle verfügbaren Unternehmensdaten werden in kleinere Datenblöcke (sogenannte Chunks) aufgeteilt und in (Vektor-)Datenbanken gespeichert, wo sie in numerische Embeddings umgewandelt werden. Wenn ein Benutzer eine Anfrage stellt, sucht das System nach relevanten Datenblöcken, indem es die Embeddings der Anfrage mit den gespeicherten Daten vergleicht.
Diese Methode erfordert kein Fine-Tuning der LLMs. Stattdessen werden relevante Daten abgerufen und an die Benutzeranfrage in der Prompt and das LLM angehängt, um sicherzustellen, dass die Antworten des Chatbots auf den unternehmensspezifischen Daten basieren. Dieser Ansatz funktioniert effektiv mit allen Arten von Textdaten, einschließlich PDFs, Webseiten und sogar mittels multimodaler Einbettung mit Bildern.
Auf diese Weise wird das in Handbüchern gespeicherte Unternehmenswissen für Mitarbeiter*Innen, Kunden oder andere Interessengruppen über KI-gestützte Chatbots leicht zugänglich.
Erweiterung des RAG um Videodaten
Während RAG für textbasiertes Wissen gut funktioniert, ist es für komplexe, prozessbasierte Aufgaben, die sich oft besser visuell darstellen lassen, nicht vollständig geeignet. Für Aufgaben wie die Wartung von Maschinen, bei denen es schwierig ist, alles durch schriftliche Anweisungen zu erfassen, bieten Video-Tutorials eine praktische Lösung, ohne dass zeitaufwändige Dokumentationen geschrieben werden müssen.
Videos bilden implizites Wissen ab, indem sie Prozesse Schritt für Schritt mit Kommentaren aufzeichnen. Im Gegensatz zu Text ist die automatische Beschreibung eines Videos jedoch alles andere als einfach. Selbst Menschen gehen hierbei unterschiedlich vor und konzentrieren sich oft auf unterschiedliche Aspekte desselben Videos, je nach Perspektive, Fachwissen oder Zielsetzung. Diese Variabilität verdeutlicht die Herausforderung, vollständige und konsistente Informationen aus Videodaten zu extrahieren.
Aufschlüsseln von Videodaten
Um das in den Videos enthaltene Wissen den Nutzern über einen Chatbot zugänglich zu machen, ist unser Ziel, einen strukturierten Prozess für die Umwandlung von Videos in Text bereitzustellen. Dabei steht die Extraktion möglichst vieler relevanter Informationen im Vordergrund.
Videos bestehen aus drei Hauptkomponenten:
- Metadaten: Metadaten sind in der Regel einfach zu handhaben, da sie oft in strukturierter Textform vorliegen.
- Audio: Audiodaten können mit Hilfe von Sprach-zu-Text (STT) Modellen wie Whisper von OpenAI in Text umgewandelt werden. Für branchenspezifische Kontexte ist es auch möglich, die Genauigkeit zu verbessern, indem benutzerdefinierte Terminologie in diese Modelle integriert wird.
- Frames (visuelle Elemente): Die eigentliche Herausforderung besteht darin, die Frames (Bilder) sinnvoll in die Audiotranskription zu integrieren. Beide Komponenten sind voneinander abhängig – ohne Audiokommentare fehlt den Frames oft der Kontext und umgekehrt.
Bewältigung der Herausforderungen bei der Beschreibung von Videos
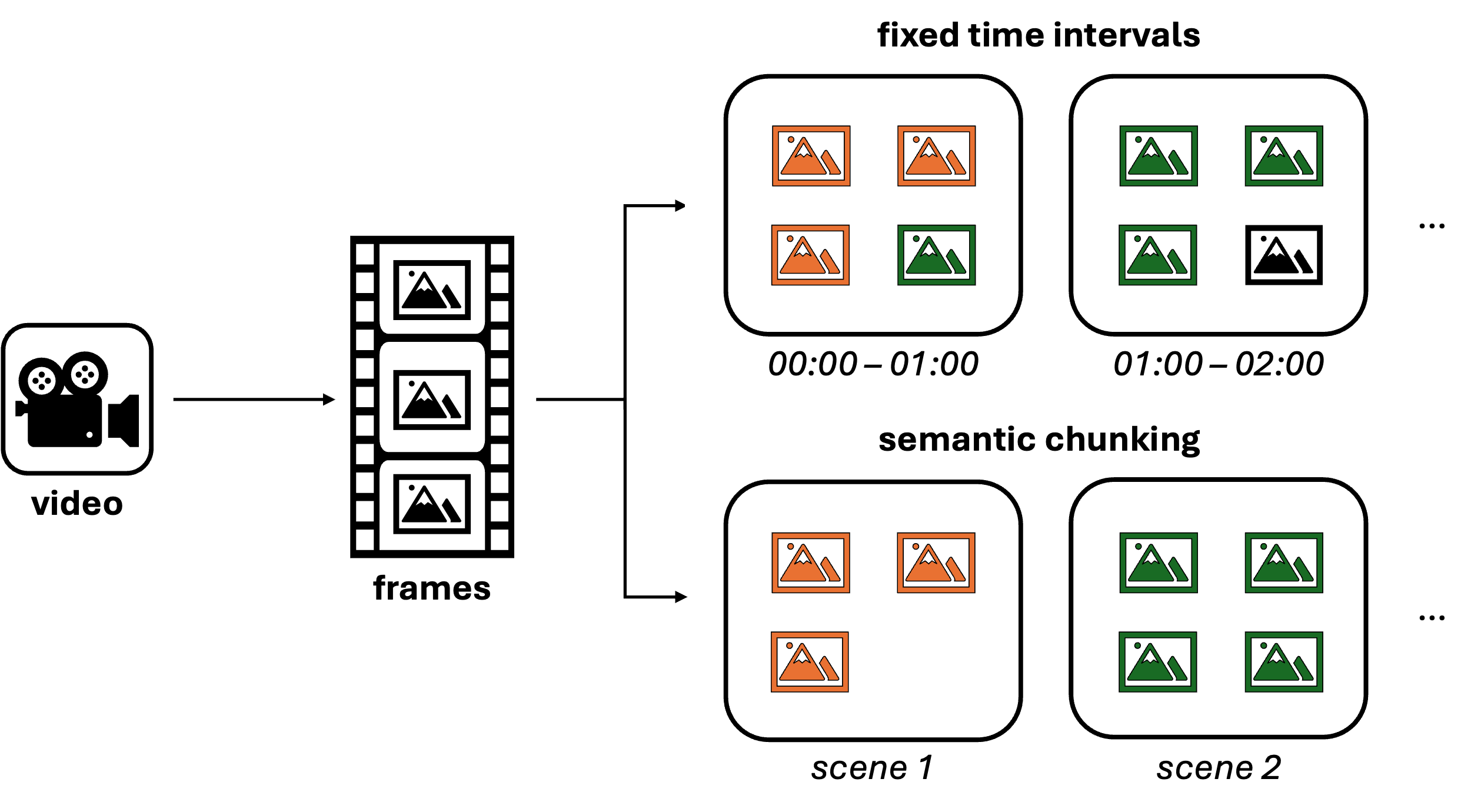
Abbildung 1: Chunking-Verfahren von VideoRAG.
Bei der Arbeit mit Videodaten bestehen drei wesentlichen Herausforderungen:
- Beschreibung der einzelnen Bilder (Frames)
- Erhaltung des Kontextes, da nicht jedes Bild unabhängig von den anderen relevant ist
- Integration der Audiotranskription für ein besseres Verständnis des Videoinhalts
Um diese Probleme zu lösen, können multimodale Modelle wie GPT-4o verwendet werden, die sowohl Text als auch Bilder verarbeiten können. Durch die Verwendung von Videobildern und transkribiertem Audio als Input für diese Modelle kann eine vollständige Beschreibung von Videosegmenten erstellt werden.
Entscheidend ist jedoch, dass der Kontext zwischen den einzelnen Frames erhalten bleibt. Hier wird die Gruppierung von Frames (oft auch als Chunking bezeichnet) wichtig. Zwei Methoden, um Frames zu gruppieren sind:
- Feste Zeitintervalle: Ein einfacher Ansatz, bei dem aufeinanderfolgende Frames auf der Grundlage vordefinierter Zeitintervalle gruppiert werden. Diese Methode ist einfach zu implementieren und für viele Anwendungsfälle gut geeignet.
- Semantisches Chunking: Ein anspruchsvollerer Ansatz, bei dem Frames auf der Grundlage ihrer visuellen oder kontextuellen Ähnlichkeit gruppiert werden, um sie effektiv in Szenen zu organisieren. Es gibt verschiedene Möglichkeiten, semantisches Chunking zu implementieren, wie z.B. die Verwendung von Convolutional Neural Networks (CNNs) zur Berechnung der Ähnlichkeit von Frames oder die Verwendung von multimodalen Modellen wie GPT-4o zur Vorverarbeitung. Durch die Festlegung eines Ähnlichkeitsschwellenwertes können verwandte Bilder gruppiert werden, um das Wesentliche jeder Szene besser zu erfassen.
Sobald die Bilder gruppiert sind, können sie zu Bildrastern kombiniert werden. Diese Technik ermöglicht es dem Modell, die Beziehung und Abfolge zwischen verschiedenen Frames zu verstehen, während die narrative Struktur des Videos erhalten bleibt.
Die Wahl zwischen festen Zeitintervallen und semantischem Chunking hängt von den spezifischen Anforderungen des Anwendungsfalls ab. Unserer Erfahrung nach sind feste Intervalle für die meisten Szenarien ausreichend. Obwohl semantisches Chunking die zugrundeliegende Semantik des Videos besser erfasst, erfordert es die Abstimmung mehrerer Hyperparameter und kann ressourcenintensiver sein, da jeder Anwendungsfall eine eigene Konfiguration erfordern kann.
Mit zunehmender Leistungsfähigkeit von LLMs und der Zunahme von Kontextfenstern könnte man versucht sein, alle Bilder in einem einzigen Aufruf an das Modell zu übergeben. Dieser Ansatz sollte jedoch mit Vorsicht gewählt werden. Wenn zu viele Informationen auf einmal übergeben werden, kann das Modell überfordert werden und wichtige Details übersehen. Darüber hinaus sind aktuelle LLMs durch die Begrenzung ihrer Token-Ausgabe eingeschränkt (z.B. erlaubt GPT-4o 4096 Token), was die Notwendigkeit gut durchdachter Verarbeitungs- und Framing-Strategien noch unterstreicht.
Erstellung von Videobeschreibungen mit multimodalen Modellen
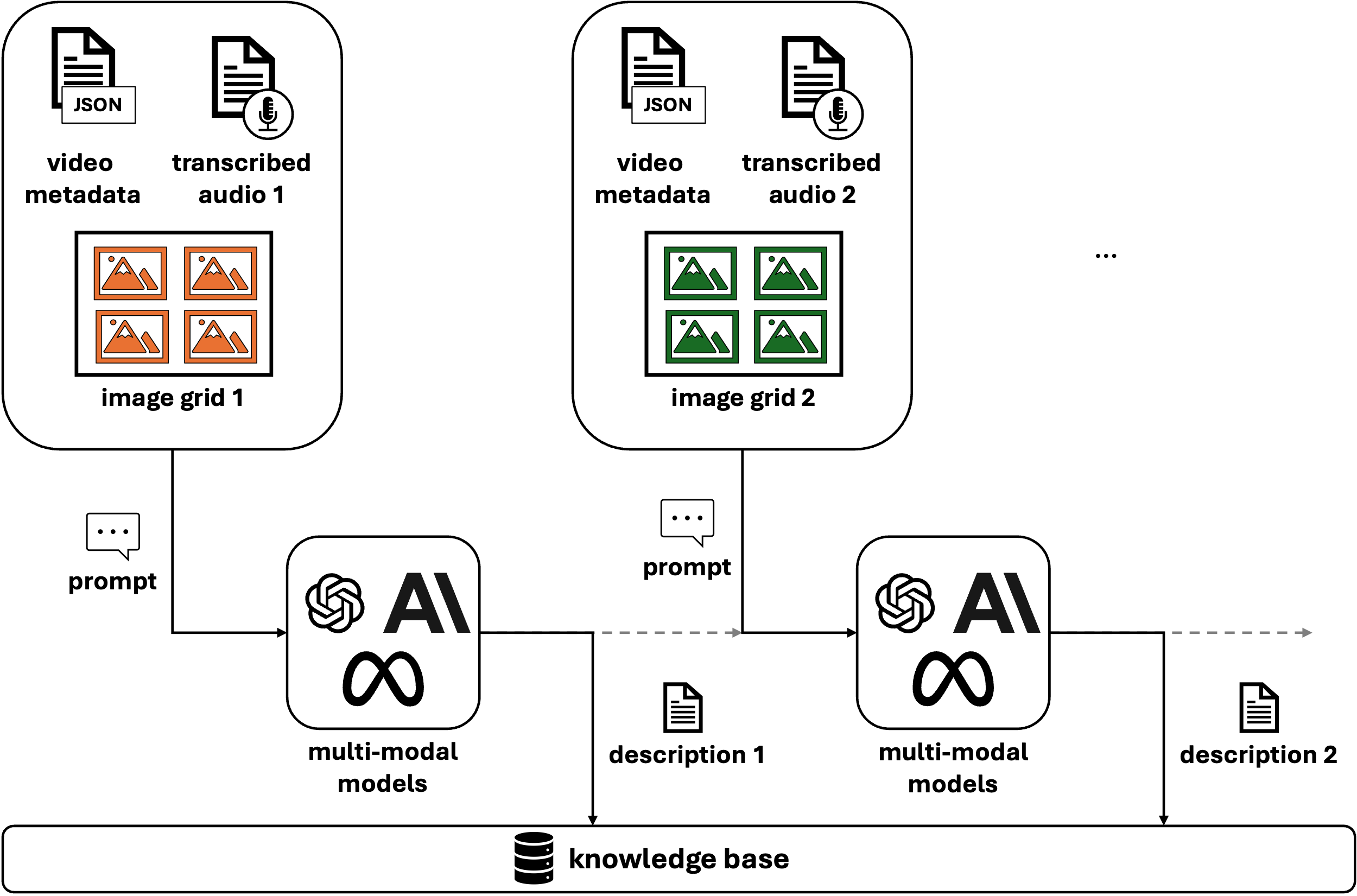
Abbildung 2: VideoRAG Ingestion Pipeline.
Sobald die Bilder gruppiert und mit der entsprechenden Audiotranskription verknüpft sind, kann das multimodale Modell geprompted werden, Beschreibungen für diese Teile des Videos zu erzeugen. Um die Kontinuität zu wahren, können Beschreibungen von früheren Teilen des Videos auf spätere Teile übertragen werden, so dass ein kohärenter Fluss entsteht (siehe Abbildung 2). Am Ende hat man Beschreibungen für jeden Teil des Videos, die zusammen mit Zeitstempeln in einer Wissensdatenbank gespeichert werden können, um eine einfache Referenz zu ermöglichen.
VideoRAG zum Leben erwecken
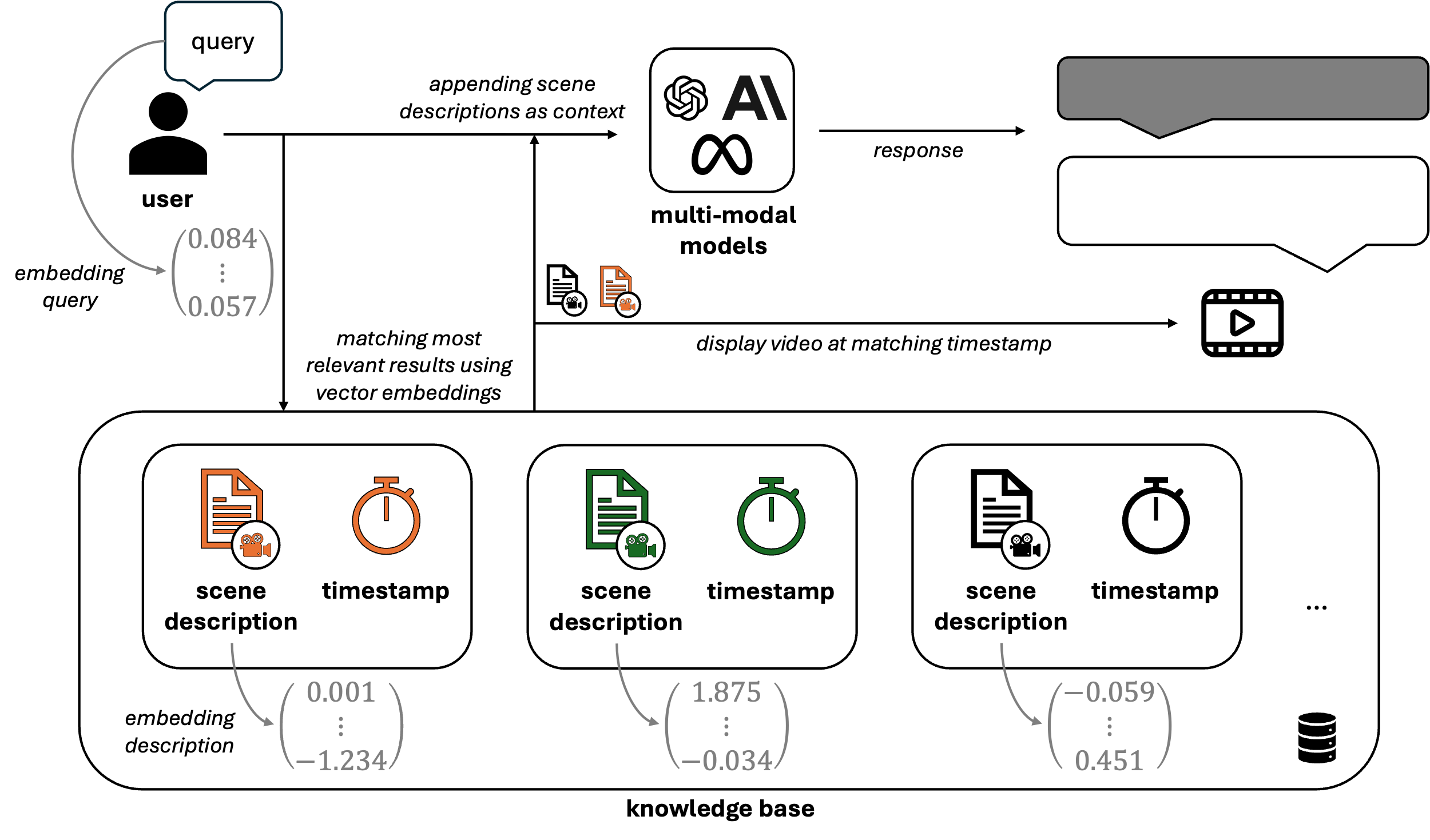
Abbildung 3: Retrieval-Prozess von VideoRAG.
Wie in Abbildung 3 dargestellt, werden alle Szenenbeschreibungen der in der Wissensbasis gespeicherten Videos in numerische Embeddings umgewandelt. Dies ermöglicht ein ähnliches Embedding der Benutzeranfragen und damit eine effiziente Suche nach relevanten Videoszenen anhand von Vektorähnlichkeiten (z.B. Kosinus-Ähnlichkeit). Sobald die relevantesten Szenen identifiziert sind, werden die entsprechenden Beschreibungen der Anfrage hinzugefügt, um dem LLM einen auf dem tatsächlichen Videoinhalt basierenden Kontext zu liefern. Zusätzlich zur generierten Antwort ruft das System die zugehörigen Zeitstempel und Videosegmente ab, so dass der Benutzer die Informationen direkt im Quellmaterial überprüfen und validieren kann.
Durch die Kombination von RAG-Technologien mit Videoverarbeitungsfunktionen können Unternehmen eine umfassende Wissensbasis aufbauen, die sowohl Text- als auch Videodaten enthält. Vor allem neu eingestellte Mitarbeiter*Innen können schnell auf kritische Erkenntnisse älterer Kollegen zugreifen – egal ob diese dokumentiert oder per Video demonstriert wurden – und so den Wissenstransfer effizienter gestalten.
Lessons Learned
Während der Entwicklung von VideoRAG hatten wir einige wichtige Learnings, von denen zukünftige Projekte in diesem Bereich profitieren können. Hier sind einige der wichtigsten Lektionen, die wir gelernt haben:
1. Optimierung der Prompts mit dem CO-STAR Framework
Wie bei den meisten Anwendungen, an denen LLMs beteiligt sind, hat sich das Prompt-Engineering als entscheidende Komponente für unseren Erfolg erwiesen. Die Erstellung präziser und kontextbezogener Eingabeaufforderungen hat einen großen Einfluss auf die Leistung des Modells und die Qualität der Ausgabe. Wir haben festgestellt, dass die Verwendung des CO-STAR Frameworks – eine Struktur, die den Schwerpunkt auf Context, Goal, Style, Tone, Audience und Response legt – einen soliden Leitfaden für das Prompt-Engineering darstellt.
Durch die systematische Berücksichtigung aller Elemente von CO-STAR konnten wir die Konsistenz der Antworten sicherstellen, insbesondere in Bezug auf das Format der Beschreibung. Durch die Verwendung dieser Struktur konnten wir zuverlässigere und individuellere Ergebnisse erzielen und Mehrdeutigkeiten in den Videobeschreibungen minimieren.
2. Einführung von Leitplanken zur Vermeidung von Halluzinationen
Einer der schwierigsten Aspekte bei der Arbeit mit LLM ist der Umgang mit ihrer Tendenz, Antworten zu generieren, auch wenn keine relevanten Informationen in der Wissensbasis vorhanden sind (sogenannte Hullunizationen). Wenn eine Frage außerhalb der verfügbaren Daten liegt, können LLMs auf Halluzinationen oder ihr implizites Wissen zurückgreifen, was oft zu ungenauen oder unvollständigen Antworten führt.
Um dieses Risiko zu verringern, haben wir einen zusätzlichen Überprüfungsschritt eingeführt. Bevor eine Benutzeranfrage beantwortet wird, lassen wir das Modell die Relevanz jedes aus der Wissensbasis abgerufenen Chunks bewerten. Wenn keine der abgerufenen Daten die Anfrage sinnvoll beantworten kann, wird das Modell angewiesen, nicht fortzufahren. Diese Strategie wirkt wie eine Leitplanke, die nicht fundierte oder sachlich falsche Antworten verhindert und sicherstellt, dass nur relevante und fundierte Informationen verwendet werden. Diese Methode ist besonders wirksam, um die Integrität der Antworten zu wahren, wenn die Wissensbasis keine Informationen zu bestimmten Themen enthält.
3. Umgang mit der Fachterminologie bei der Transkription
Ein weiterer kritischer Punkt war die Schwierigkeit der STT-Modelle, mit branchenspezifischen Begriffen umzugehen. Diese Begriffe, zu denen oft Firmennamen, Fachjargon, Maschinenspezifikationen und Codes gehören, sind für eine genaue Suche und Transkription unerlässlich. Leider werden sie oft missverstanden oder falsch transkribiert, was zu ineffektiven Suchen oder Antworten führen kann.
Um dieses Problem zu lösen, haben wir eine kuratierte Sammlung von branchenspezifischen Begriffen erstellt, die für unseren Anwendungsfall relevant sind. Durch die Integration dieser Begriffe in den Prompt des STT- Modells konnten wir die Qualität der Transkription und die Genauigkeit der Antworten erheblich verbessern. Das Whisper-Modell von OpenAI unterstützt z.B. die Einbeziehung domänenspezifischer Terminologie, wodurch wir den Transkriptionsprozess effizienter steuern und sicherstellen konnten, dass wichtige technische Details erhalten bleiben.
Fazit
VideoRAG ist der nächste Schritt in der Nutzung generativer KI für den Wissenstransfer, insbesondere in Branchen, in denen praktische Aufgaben mehr als nur Text zur Erklärung erfordern. Durch die Kombination von multimodalen Modellen und RAG-Techniken können Unternehmen sowohl explizites als auch implizites Wissen über Generationen hinweg effektiv bewahren und weitergeben.

Arne Grobruegge, Data Scientist bei scieneers GmbH
arne.grobruegge@scieneers.de






