
Microsoft Fabric Deployment

Introduction
Microsoft Fabric is a versatile and powerful platform for today’s data and analytics requirements and is currently attracting a lot of attention from our customers. It meets a wide range of needs, depending on the size of the organisation, its data culture and its development and analysis focus.
Customers in the Power BI environment are particularly benefiting from the extension of the self-service approach: Using familiar web interfaces and without specialised development tools, business departments or end users can quickly get started with data preparation.
Experienced developers and IT teams, on the other hand, want to ensure that they can continue to use best practices in Fabric, such as development in an IDE, version management with Git, or established testing and rollout processes. This raises the question of how to robustly test and deploy key changes to a large number of users.
In this blog post, we aim to provide an overview of the development and collaboration capabilities and deployment scenarios in Fabric. Although we try to provide a general overview, Microsoft is working to develop new features and enhancements for Fabric, so technical details may change over time. For the latest information on Fabric, see the official documentation or visit the Microsoft-Fabric-Blog.
Table of contents
- Development Processes
- Integration: Fabric Git Integration
- Deployment Processes
- Conclusion
Development Processes
1. Live Development in the Fabric GUI
Fabric as Software-as-a-Service is usually operated directly via the browser.
If you are already familiar with the Power BI service, the familiar workspace concept will help you get up and running quickly. New fabric objects, such as data flows or pipelines, can be easily created and edited in the web interface – no local development environment or additional software installations are required.
Another key advantage of browser-based development in Fabric is its cross-platform usability on Windows and MacOS. However, browser-based development environments tend to be less flexible and customisable than an integrated development environment (IDE), with a limited set of tools and integration options. Fabric is no different.
Changes to Fabric objects are instantly live and can be seen and tested by other users, significantly accelerating development cycles. However, there are risks associated with this immediate visibility: errors or unwanted changes immediately affect all users and cannot be undone as easily as with locally stored files.
For this reason, Microsoft is working on integrated versioning, including rollback functionality for various Fabric objects. This is already available for notebooks and is currently in Preview-Phase for semantic models.

Despite some limitations in flexibility and tool integration, the web interface provides a quick and convenient introduction to development and simplifies collaboration in distributed teams. For example, the notebook GUI supports parallel working, including comments and cursor highlighting, which facilitates pair programming, remote debugging and tutoring scenarios.
This development process is particularly suitable for scenarios where isolated development is not required and changes can be made directly to the live version – for example, for end users in non-technical departments or less critical use cases.
On the other hand, if a dedicated environment is required to test new features or customisations without affecting the live version, there are two basic approaches.
2. Isolated development with local client tools
Client tools are available for various Fabric objects that can be installed on a computer and used to edit these objects locally. In most cases, a local copy of the Fabric object is created, edited, and uploaded back to the Fabric workspace once all changes have been made.
Power BI users are already familiar with this process: A Power BI report from Fabric can be downloaded as a .pbix file and edited locally using Power BI Desktop. The changes to the report are not visible in Fabric until the local changes are published. Fabric notebooks can be edited in a similar way; they can be exported as an .ipynb file and edited locally with your preferred development tools. There is an extension to VS Code (currently called “Synapse”) that simplifies this process.
Once you have installed this VS Code extension, you can create a local copy of the notebook directly from a button in the Fabric GUI and open it in VS Code.
This allows you to work in a familiar development environment. If required, you can even run the code on the fabric capacity via the fabric-spark-runtime and thus process large amounts of data. As soon as all changes have been made to the notebook, the customized version is simply uploaded backto the Fabric Workspace via the VS Code plugin – including a practical diff function to display differences compared to the version in the Fabric Workspace.
The Fabric environment can also be accessed in other areas with local tools. For example, VS Code or SQL Server Management Studio can be used to write SQL queries or define views. The Fabric Warehouse in particular is currently well integrated into these tools, but a connection is generally possible with all SQL-based fabric objects.

These features can be used without connecting the Fabric workspace to a Git repository. This makes the process particularly suitable for users who need an isolated development environment but are new to Git, or whose workspaces are not (yet) connected to a Git repository for organisational reasons.
For experienced developers, however, Git integration is a key component of professional development processes. For this reason, Microsoft Fabric also offers native integration with Azure DevOps and GitHub.
Integration: Fabric Git Integration
Microsoft Fabric allows you to connect a workspace to an Azure DevOps or GitHub repository to use a Git-integrated development process, such as versioning. A detailed explanation of this functionality’s features and limitations can be found here.
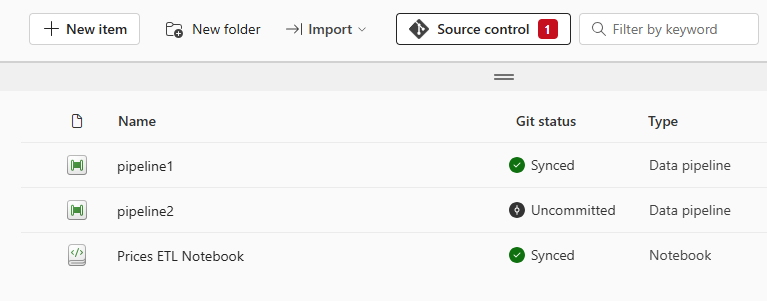
When a workspace is connected to a repository, the Git status of each fabric object can be viewed at any time. Changes to objects or the creation of new objects can be committed directly from the GUI and saved to the repository. This ensures that accidentally deleted items can be recovered at any time.
It is important to understand that this synchronisation between Fabric and the repository can work in both directions. This means that changes from Fabric can be saved to the repository and changes to the objects in the repository (e.g. if a notebook has been edited directly in the repository) can be imported back into the Fabric workspace.
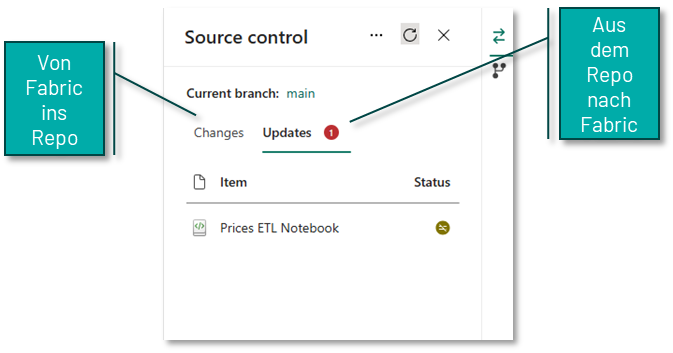
If the Fabric workspace is Git-integrated, this opens up further possibilities for working locally with different Fabric elements. By cloning the relevant repository, you can use all the familiar Git features, such as local feature branches or individual commits for important intermediate states.
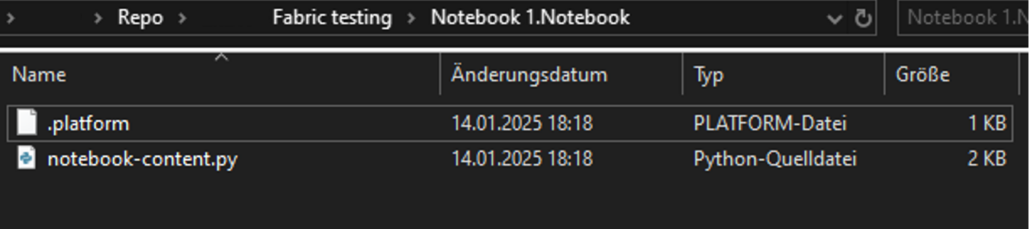
The downside is that the individual Fabric items in the repository are stored in formats that are primarily designed for Git-optimised storage rather than convenient editing. Notebooks, for example, are not saved as .ipynb files but as pure .py files, supplemented by an additional platform file containing important metadata. This can make it difficult to work locally with branches in the repository.
3. Isolated development in feature branch workspaces
To achieve an isolated development environment, you do not necessarily need to use local tools in Fabric. Provided the workspace is Git-integrated, Fabric also offers native options. Of particular interest is the ability to branch to a new feature workspace, which is described in more detail here.
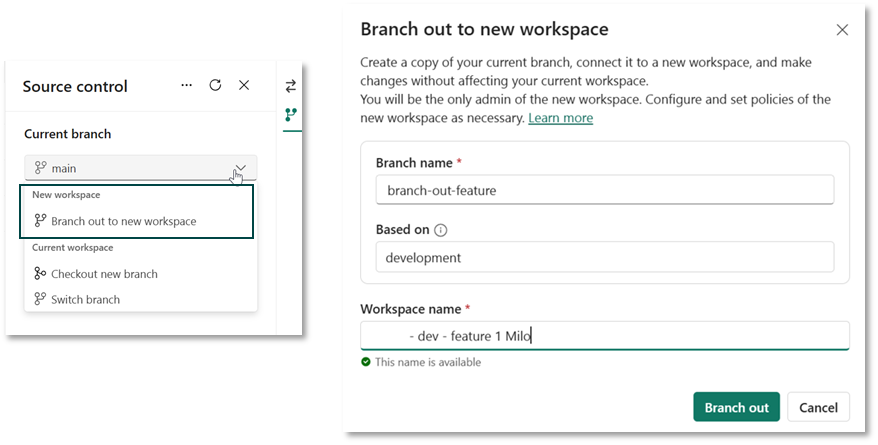
When you use this feature, a copy of the workspace is created to which only you have access. In this copy, you can develop in isolation, without affecting the functionality of the objects in the real workspace. The following happens in the background
A new empty workspace with the defined name is created.
The contents of the current workspace are copied to this branch.
A new branch is created in the repository, the name of which can also be defined.
The Tissue objects are created in the newly created workspace based on the newly created branch.
You can now work on the fabric objects in isolation and commit the changes to the new branch, for example if you want to continue developing a notebook. It is important to note that data (e.g. in a lake house) is not stored in the repository and is therefore not available in the new workspace. This means that a notebook will still connect to the lakehouse in the current workspace if it was used as a data source in the notebook.
Once you have made all the changes in the feature workspace, you still need to commit those changes back to the actual workspace. This process primarily takes place in Azure DevOps or GitHub and requires a basic understanding of Git. A pull request (PR) is created to merge the feature branch into the main branch of the actual workspace. All the usual DevOps and GitHub features are available here, such as tagging reviewers. Once the PR has been successfully completed, the main branch in the repository has a more up-to-date status than the fabric objects in the workspace itself. Finally, the status needs to be transferred from the repository to the workspace. To do this, you can use the update process described above in the source control panel of the fabric workspace, or you can automate this process via API.
The following diagram illustrates the process.
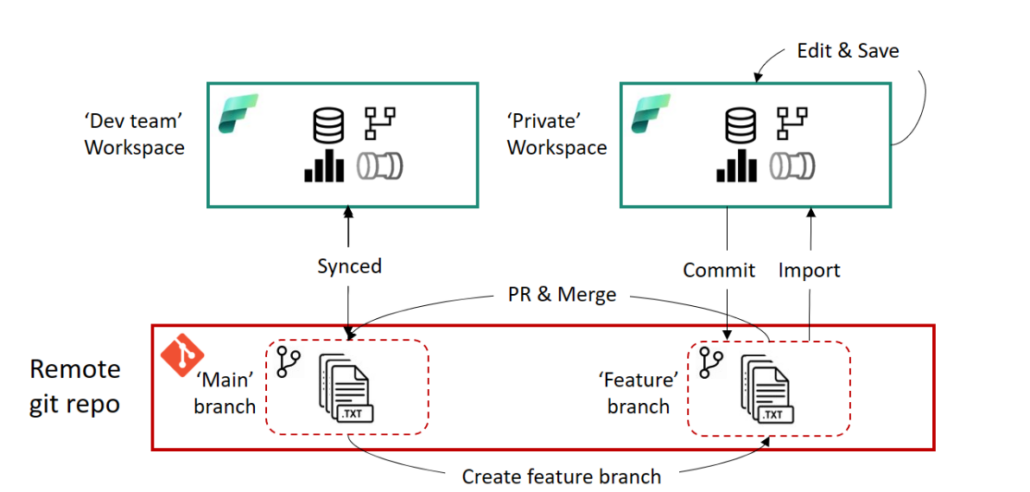
This development process offers the full benefits of Git-based development and can be supplemented with local client tools if required. For example, it is possible to open the notebooks in the feature workspace using the process described above in VS Code.
However, there are some drawbacks to this process. Since pull requests and merges are done in Azure DevOps or GitHub, this process requires experience using Git and Azure DevOps or GitHub. In addition, users wishing to use this feature in Fabric must be authorised to create workspaces, which must first be approved by an administrator. At the moment, feature workspaces are also not automatically deleted after a successful merge with the source workspace. This can result in workspaces that are no longer needed accumulating over time unless they are manually deleted.
Deployment Processes
A further step in professionalising the use of Microsoft Fabric is to run workloads in multiple environments. Typically, a distinction is made between a development environment (Dev.) and a production environment (Prod.). This allows the workload in the development environment to be developed in isolation and iteratively, while the end users in the production environment always have a working and well-documented version of the workload.
Once a satisfactory point in the development process is reached, the development state is transferred from the development environment to the production environment. This is known as the deployment process. Microsoft Fabric provides several options for this.
1. Fabric Deployment Pipelines
The easiest way to integrate a deployment process into Fabric is to use Fabric Deployment Pipelines. They are an integral part of Fabric and require no additional tools – the development workspace does not even need to be connected to a Git repository to use them.
A workspace is created for each environment, and then a deployment pipeline is set up in the development workspace. A simple interface is used to define which Fabric objects to move from the source workspace (Development in the figure below) to the target workspace (Test in our case), and click ‘Deploy’.
As different environments tend to have different properties – for example, the database they access – Deployment-Rules can be defined for each Fabric object. These ensure that these properties are adjusted accordingly during the deployment process.
However, these deployment rules cannot yet be used for all Fabric objects and only support a pre-defined selection of properties that can be customised. For example, it is not possible to replace parameter values previously defined in code in a fabric notebook.

Overall, Fabric Deployment Pipelines provide an easy entry point to multi-environment development without requiring in-depth Git experience. They are particularly suited to workloads managed by non-technical departments, for example, and are a logical extension of the self-service principle.
2. Branch-based Deployment
The second way to implement a deployment process in Fabric requires that all workspaces representing a particular environment (e.g. Dev, Test and Prod) are linked to different branches of the same Git repository. The functionality of branch-based deployment is similar to the feature branch development process characterised in the following diagram. In principle, however, the branch-based deployment process can be combined with any development process as long as a Git integration is set up.
This process uses the functionality of Azure DevOps Pipelines (or GitHub Actions), which automatically react to changes in repository branches and can trigger specific processes.
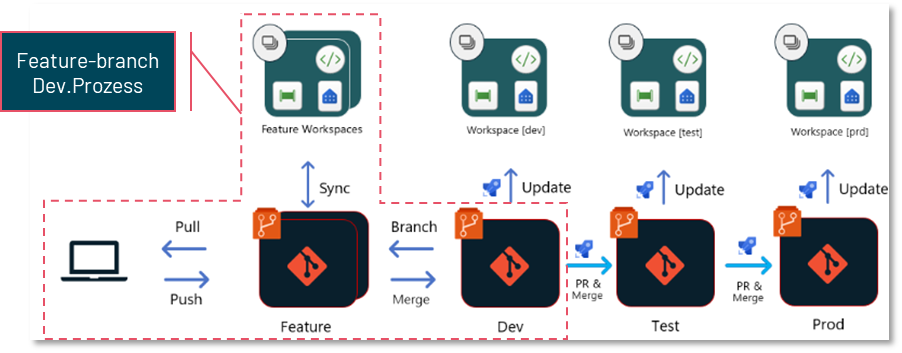
Once a new development state has been created in the development environment (Dev.) and is ready for deployment, a pull request (PR) is created in a test branch in the repository. Reviewers can review and approve the new changes in this branch.
Once the test branch is released and updated, a DevOps pipeline is automatically started to perform various actions on the object definitions in that branch. This pipeline can, for example, adjust environment parameters (such as database connections), run automated tests on the code, or ensure that the code adheres to style and naming conventions.
The customised code is then stored in another branch, such as Test-Release. This test-release branch is connected to the test workspace in Fabric. A second pipeline responds to updates to this branch and uses an API to ensure that the status of this branch is transferred to the Fabric workspace.
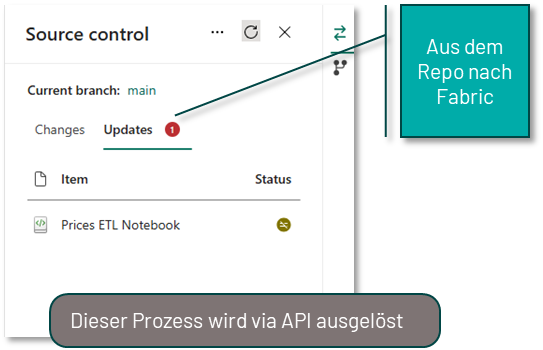
Further testing, such as data quality testing, can then be performed directly in Fabric in the test workspace before the code is moved to the production workspace in an analogous process.
In addition to an understanding of Git, this form of deployment process requires experience in setting up Azure DevOps pipelines or GitHub actions, and is therefore designed for experienced developers and critical workloads. However, using professional deployment tools then provides full flexibility to design the deployment process and integrate advanced steps such as code testing.
Working with dedicated branches per environment also makes it easy to manage different versions in each environment and roll back to previous versions quickly.
3. Release-Pipeline Deployment
Another way of deploying in Fabric is not to connect each workspace directly to a branch in a repository using the built-in options, but to deploy directly to each workspace from a shared master branch using Build- und Release-pipelines.
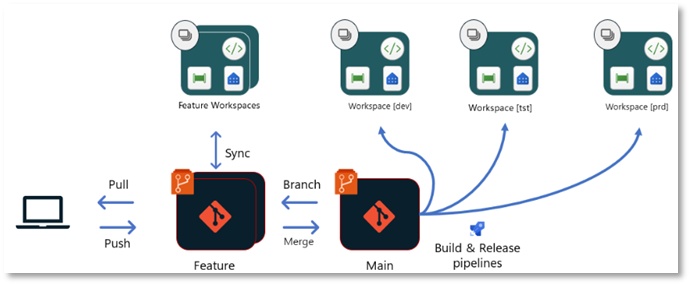
In this approach, as in the previous process, a build pipeline can exchange environment parameters (such as database connections) depending on the target environment, perform automated tests on the code, or ensure that the code conforms to style and naming conventions. In this approach, the result is not stored in a separate branch, but is passed as an artifact to, for example, a release pipeline. This then uses the Fabric Item API to deploy the relevant Fabric objects or changes to the target workspace.
Libraries such as the fabric-cicd Python Library can be used to simplify interaction with the Fabric API.
As with branch-based deployment, this approach requires experience with Azure DevOps pipelines, but also allows full flexibility in the exact design of the deployment process.
Conclusion
In this article, we have presented examples of the most common development and deployment processes in Microsoft Fabric. However, especially for the deployment processes via Azure DevOps or Github, there is of course full flexibility in the concrete design to adapt these exactly to your own needs. It is also not necessary to choose a single development or deployment process for all workloads to be mapped to Fabric. The choice of process should always be tailored to the specific requirements and workload. For example, a professional deployment process may be appropriate for central data products, such as an enterprise-wide data warehouse, while deployment via deployment pipelines may be sufficient for individual departments, or deployment processes may not be required at all.
If you want to learn more tips and tricks about Microsoft Fabric, feel free to take a look at our Microsoft Fabric Compact Introduction workshop!
Author

Milo Sikora
BI Consultant at scieneers GmbH
milo.sikora@scieneers.de



