Unser „Bring Your Own Data“-Workshop zeigt Ihnen die Möglichkeiten von Microsoft Fabric – von der Datenanbindung bis zur KI-Integration, direkt mit Ihren eigenen Daten. Ideal für Fachanwender, Data-Professionals und Entscheider, die einen praxisnahen Einstieg in moderne Datenplattformen suchen.
https://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.png00shinchit.han@scieneers.dehttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngshinchit.han@scieneers.de2025-08-13 10:45:092025-08-14 10:38:37Microsoft Fabric: „Bring Your Own Data“ Workshop
Missense-Varianten, also einzelne Aminosäureaustausche im Protein, sind oft schwer zu bewerten. Unser Machine-Learning-Workflow nutzt proteinstrukturbasierte Graph-Embeddings, um die Pathogenität solcher Varianten vorherzusagen. Dabei verbessern die strukturellen Informationen bestehende Ansätze wie den CADD-Score und bieten neue Einblicke für die genommedizinische Diagnostik.
Die neue Version der aus Azure bekannten Data Factory in Microsoft Fabric stand in letzter Zeit im Fokus zweier Vorträge, die scieneers auf renommierten Veranstaltungen präsentieren durften. Stefan Kirner hat auf der SQL Konferenz in Hanau, ausgerichtet von Datamonster, sowie auf den SQLDays, organisiert von ppedv, gesprochen.
Die Präsentation beleuchtete die technischen und konzeptionellen Unterschiede zwischen der Azure Data Factory und jener in Microsoft Fabric. Ebenso wurden die Auswirkungen dieser Unterschiede auf die Entwicklung sowie wichtige Aspekte des Application Lifecycle Managements beim Teamwork in Fabric thematisiert.
Hier eine kurze Zusammenfassung der gewonnenen Erkenntnisse:
Das Gute:
– Die Data Factory entwickelt sich weiter, bietet erweiterte Features und ist besser in das Gesamtsystem integriert.
– Das Software-as-a-Service Modell und ein berechenbares Preismodell erleichtern gerade Neulingen den Einstieg.
– Viel des bereits vorhandenen technischen Know-hows und Methodenwissens rund um die Azure Data Factory ist weiterhin anwendbar.
– Die Migration von bestehenden Data Engineering Projekten ist in den meisten Fällen problemlos möglich.
Das Schlechte:
– Für sehr kleine Projekte ist die Data Factory in Fabric nicht effizient einsetzbar.
– Spark Notebooks sind in den kleinsten verfügbaren Kapazitäten nicht wirklich nutzbar.
Das Hässliche:
– Es mangelt noch immer an Unterstützung für Git und Deployment Pipelines für Data Flows der zweiten Generation.
– Es existieren viele GUI Bugs und die Stabilität lässt zu wünschen übrig.
– Die noch eingeschränkte Anzahl von Datenquellen bei der Copy Activity führt zu Verwirrung.
Trotz der genannten Schwachstellen entwickelt sich Fabric in eine sehr positive Richtung. Microsoft arbeitet mit Hochdruck an den aktuellen Herausforderungen. Scieneers freut sich darauf, diese Technologie in zukünftigen Kundenprojekten weiterhin erfolgreich einzusetzen.
https://www.scieneers.de/wp-content/uploads/2024/10/stefan-kriner-sql-konferenz.png14862514Stefan Kirnerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngStefan Kirner2024-10-14 16:45:432025-01-31 13:32:21Data Factory in Fabric – the good, the bad and the ugly
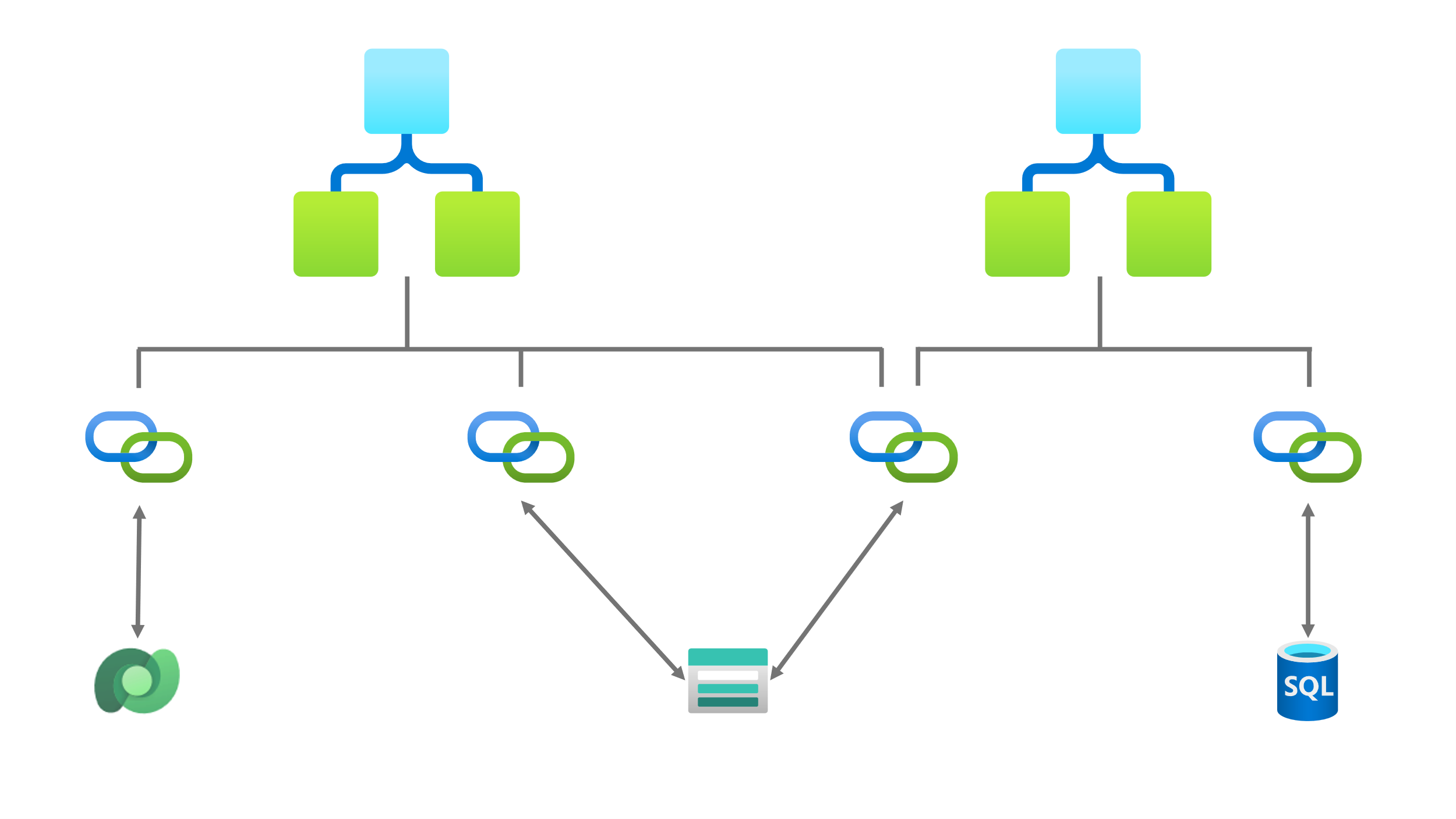
API-Connections sind ein essenzieller Bestandteil von Azure Logic Apps, einer cloudbasierten Plattform zur Erstellung und Verwaltung automatisierter Workflows. Sie können als Brücke zwischen Logic Apps und externen Diensten oder APIs gesehen werden. Sie ermöglichen es, auf externe Datenquellen und Ressourcen wie Datenbanken, Web-APIs, SaaS-Anwendungen (z. B. Salesforce, Office 365) und andere Dienste zuzugreifen und diese in automatisierte Prozesse einzubinden.
API-Connections sind eigenständige Azure-Ressourcen, die innerhalb derselben Ressourcengruppe der Logic App erstellt werden. Dadurch können auch andere Logic Apps dieser Ressourcengruppe auf dieselbe API-Connection zugreifen und sie gleichermaßen nutzen.
Wie erstellt man eine API-Connection?
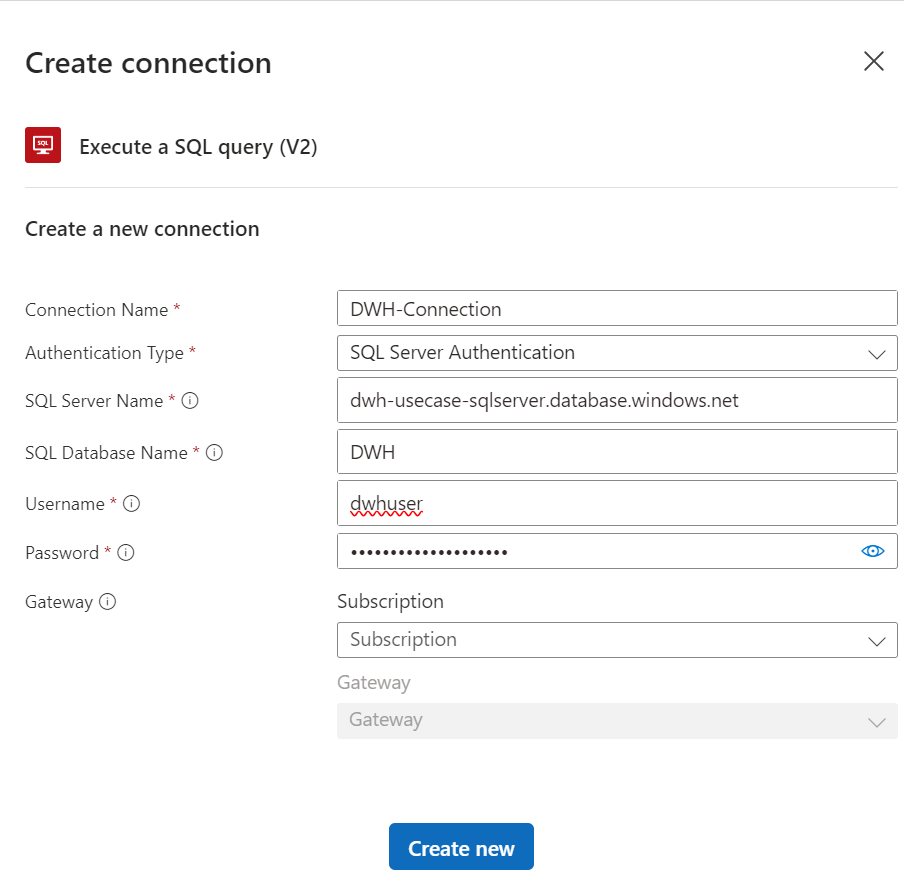
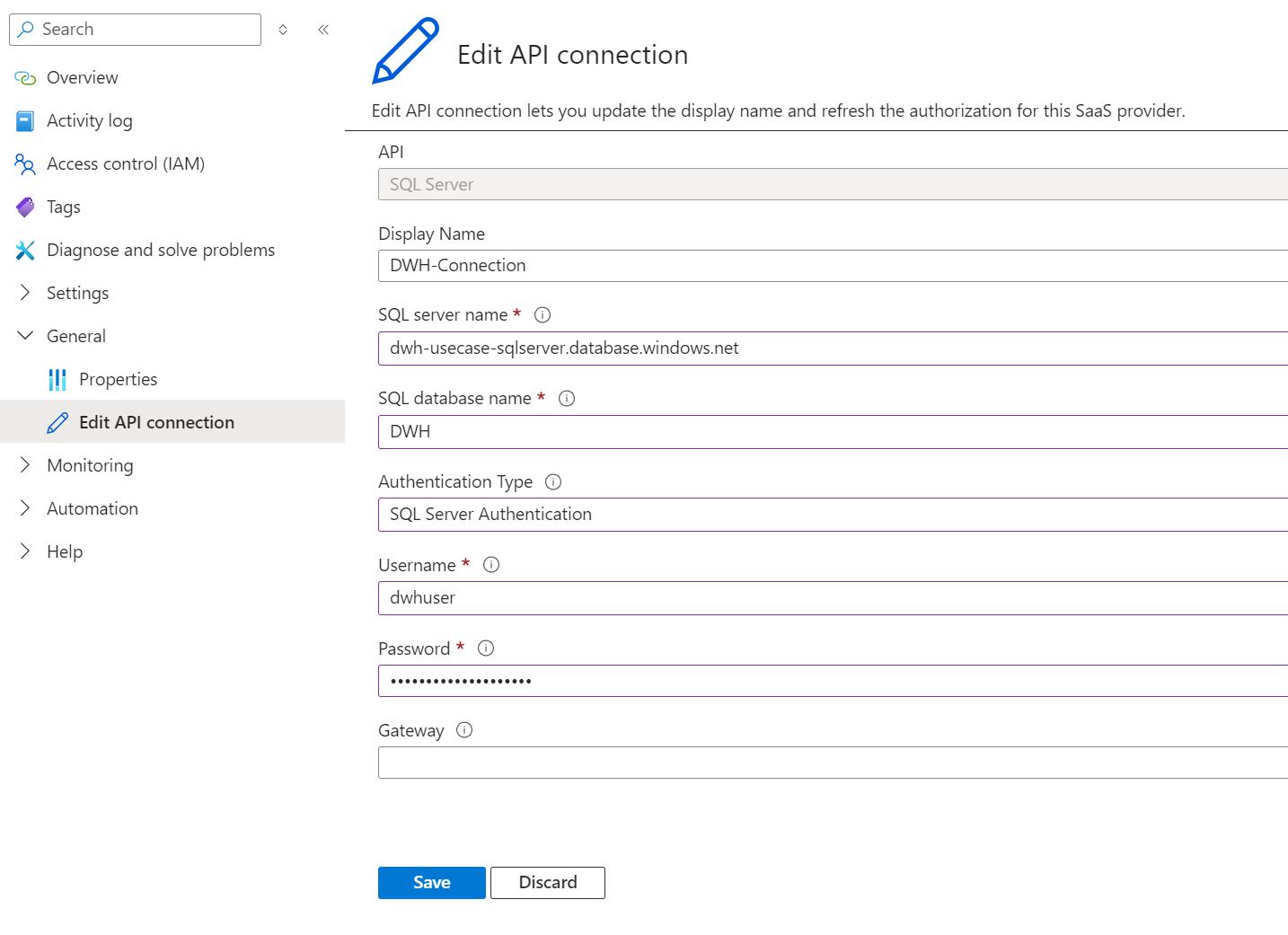
Um eine API-Connection manuell zu erstellen, wählt man innerhalb eines Workflows eine Aktion aus. Falls noch keine API-Connection angelegt ist, öffnet sich ein Dialogfenster, durch das man unter Angabe der korrekten Verbindungsdaten eine API- Connection anlegen kann:
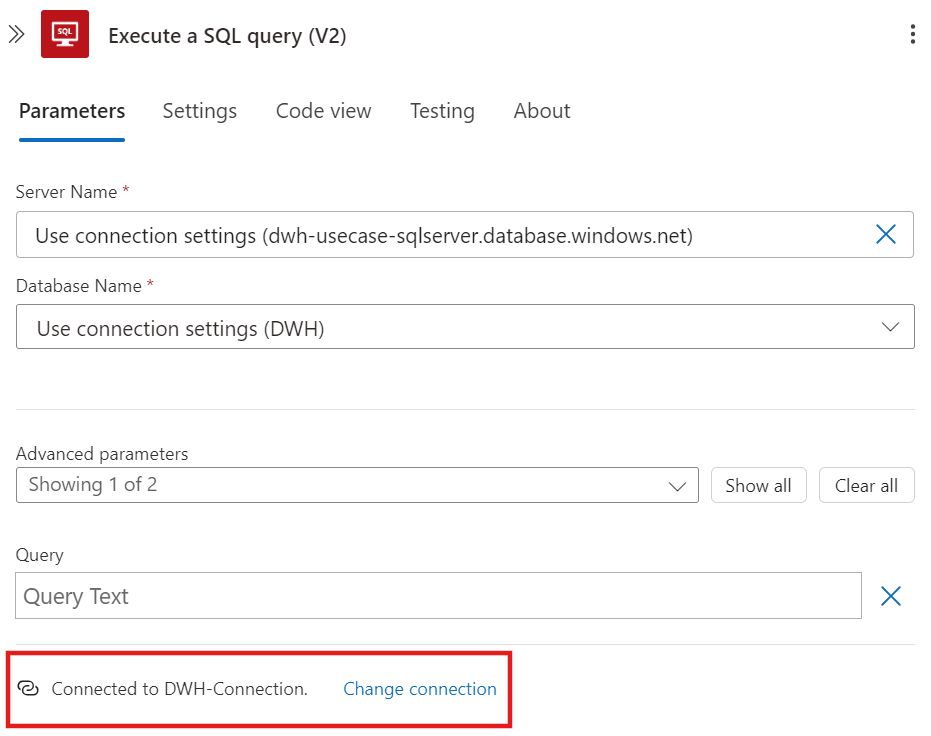
Nach dem Anlegen der API-Connection erscheint diese mit dem vorher definierten Namen in der Aktion und kann künftig auch für weitere Aktionen Logic App-übergreifend in der gleichen Ressourcegruppe verwendet werden:
Obwohl API-Connections eigenständige Azure Ressourcen darstellen, können sie nicht manuell über das Azure Portal angelegt werden, sondern nur innerhalb einer Logic App.
Potenzielle Probleme
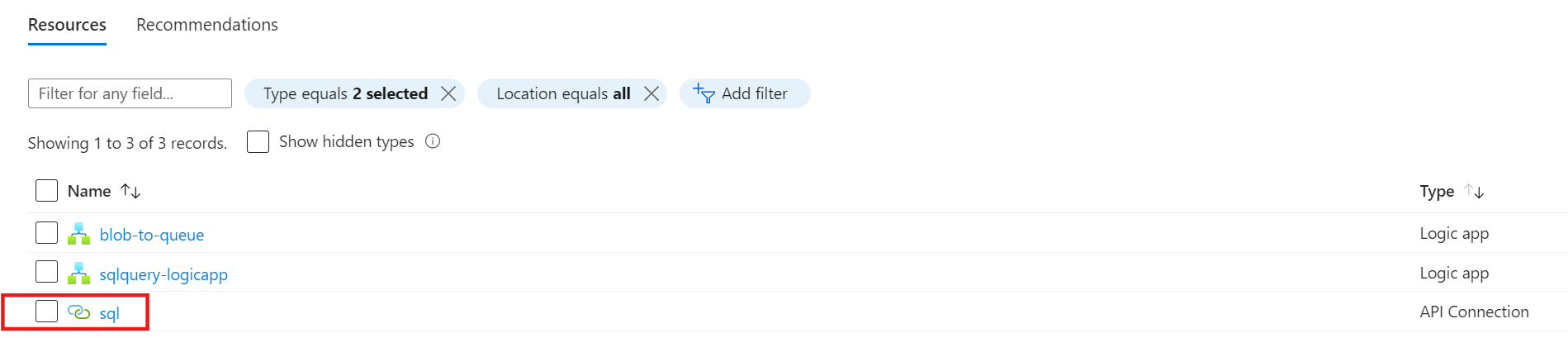
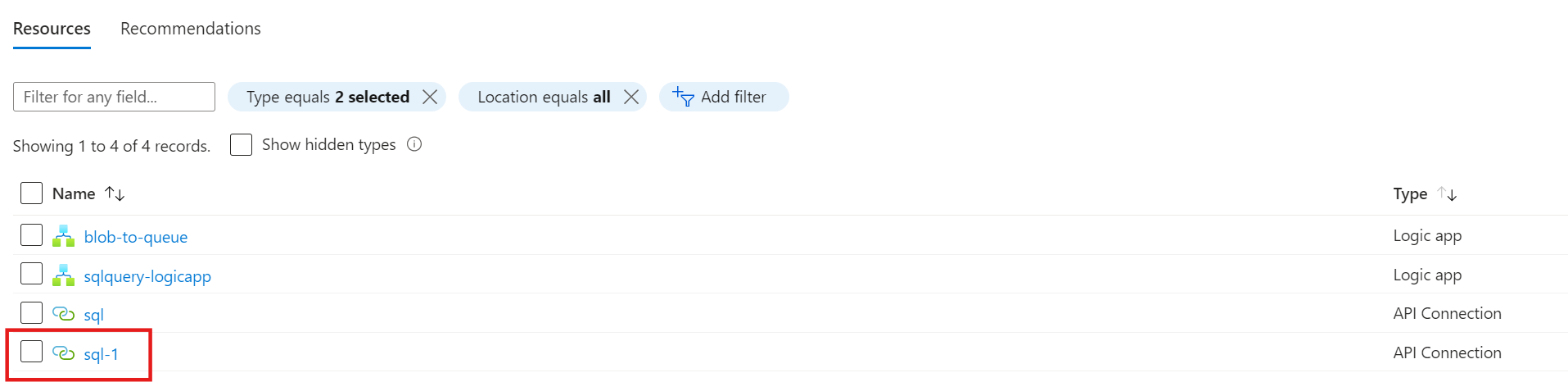
Wie bereits beschrieben, sind API-Connections eigenständige Azure Ressourcen und werden somit auch als solche angelegt. Bei der Erstellung der API-Connection wird ein Name definiert. Man könnte annehmen, dass er auch der Ressourcenname der API-Connection ist, welches leider nicht der Fall ist:
Die erstellte API-Connection bekommt einen generischen Ressourcennamen basierend auf der Verbindungsart. Dadurch hat sie zwei Namen: 1) einen internen Namen, der nur innerhalb der Logic App sichtbar ist, und 2) einen Ressourcennamen, der sowohl innerhalb als auch außerhalb der Logic App sichtbar ist. Unschön, aber bisher kein Problem. Falls man nun eine zweite Datenquelle des gleichen Typs anbinden möchte, so wird eine neue API-Connection erstellt und von Azure entsprechend benannt:
Diese Art der Benennung kann beispielsweise bei einer zunehmenden Anzahl von API-Connections die Übersichtlichkeit beinträchtigen und die Ressourcengruppe mit API-Connections überschwemmen, die möglicherweise gar nicht verwendet werden oder versehentlich angelegt wurden.
Zudem kann die Benennung bei der Integration in einen CI/CD-Prozess, je nach Setup, Probleme verursachen. Es könnte dadurch z.B. unklar werden, welche API-Connection für eine DEV/UAT/PROD Ressource steht, welche veraltet ist, etc.
Leider gibt es aktuell keine Möglichkeit mehr, eine API-Connection über die grafische Oberfläche im Azure Portal umzubenennen.
API-Connections können aber über ihr ARM-Template unter geändertem Namen neu deployed werden, was somit verschiedene Möglichkeiten eröffnet. Diese Möglichkeiten wollen wir uns in dem folgenden Abschnitt anschauen.
Deployment über das Azure Portal & Probleme
Eine Möglichkeit ist, das Deployment direkt über die Benutzeroberfläche des Azure Portal vorzunehmen.
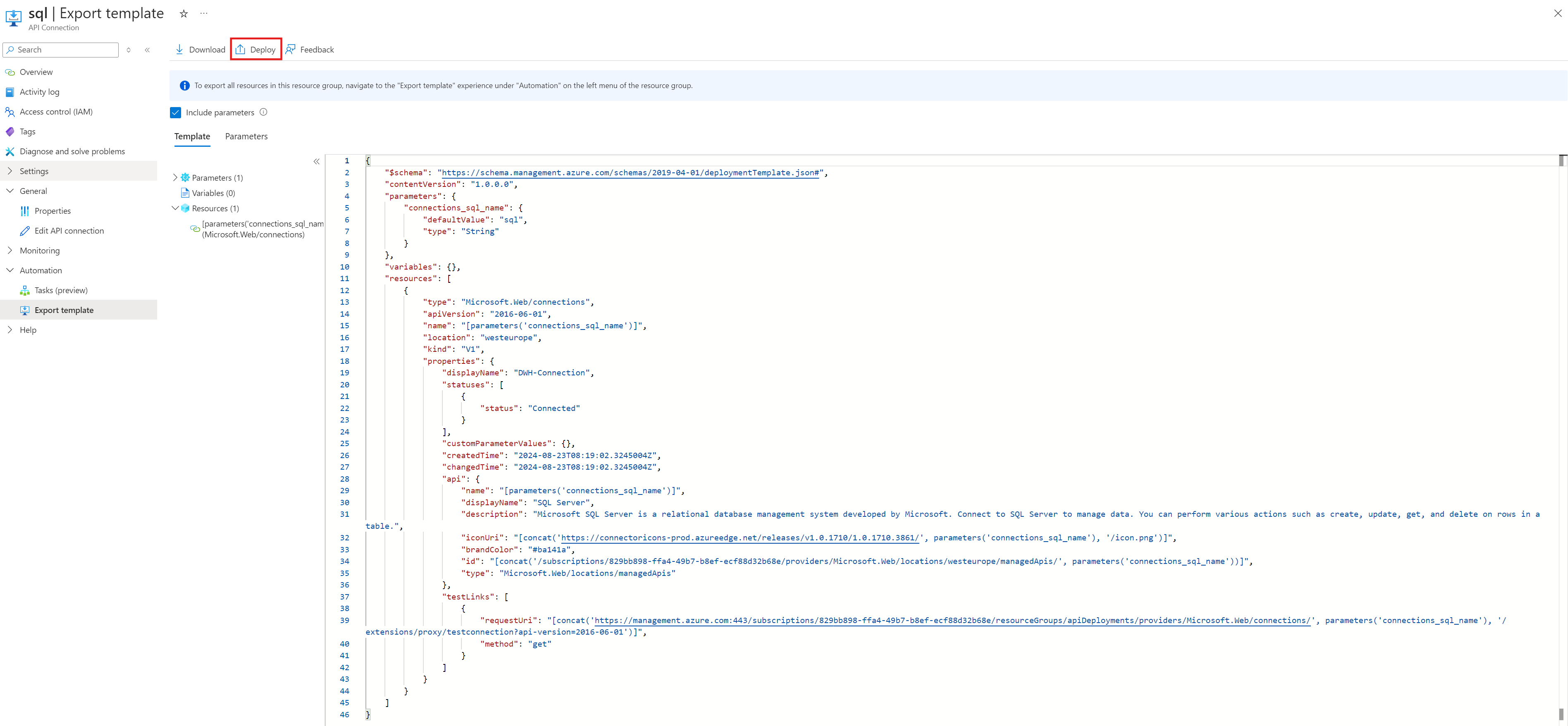
Hierzu wird die gewünschte API-Connection und ihr ARM-Template über den Menü-Punkt „Export Template“ geöffnet. Da das ARM-Template in dieser Ansicht schreibgeschützt ist, wählt man „Deploy“ und dann „Edit Template“ aus, um zu einer editierbaren Ansicht des ARM-Templates zu kommen.
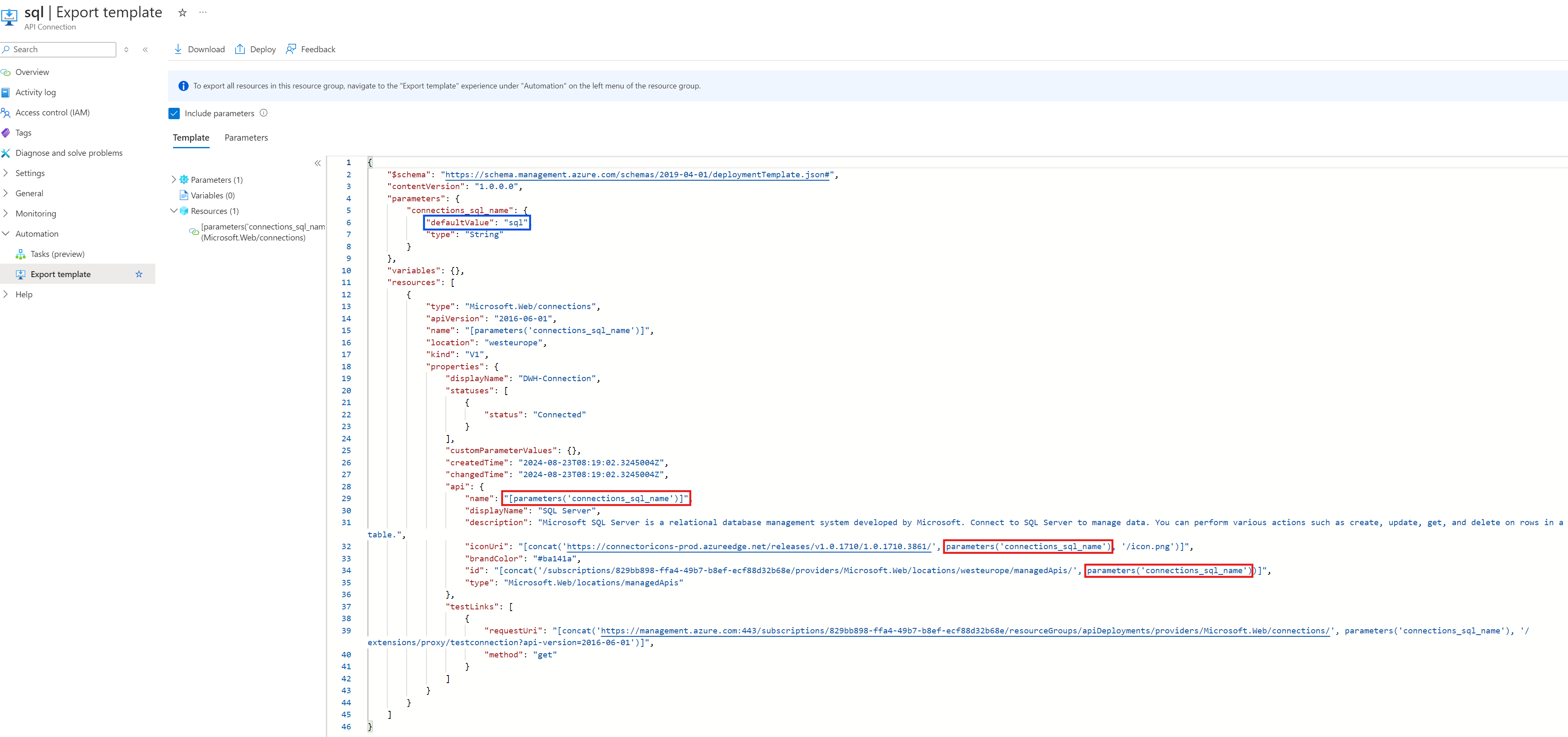
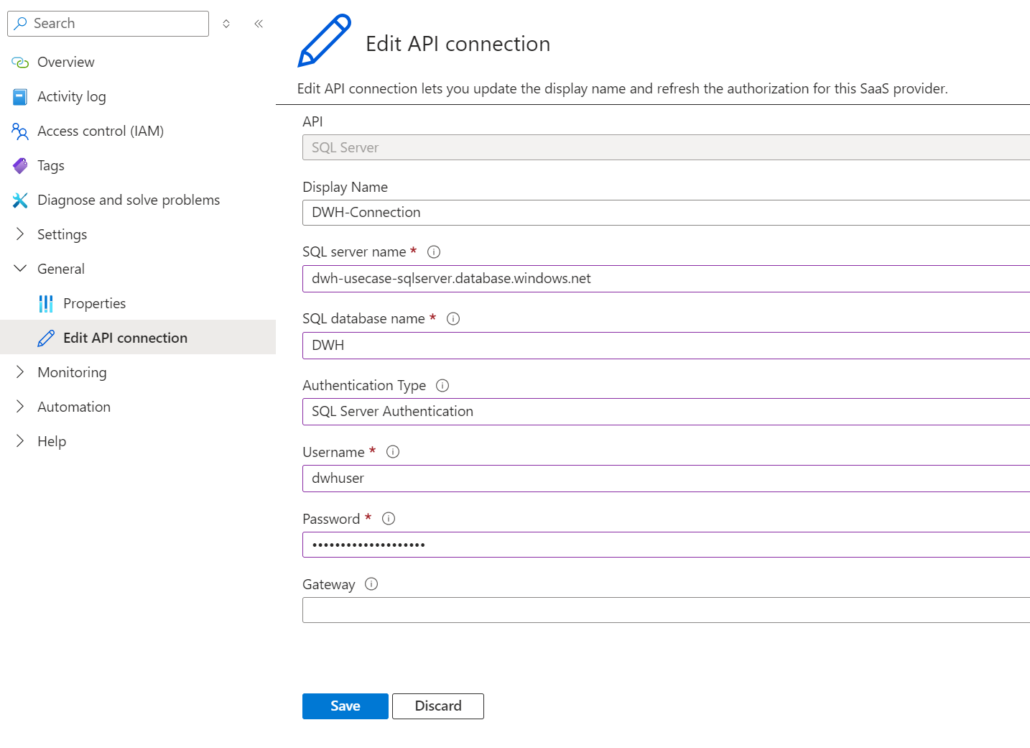
Hier öffnet sich ein neues Dialogfenster, in dem man einige Änderungen für ein valides ARM-Template vornehmen muss. Im Parameter-Objekt muss der Value für „defaultValue“ (blau umrandet) zum gewünschten API Connection Namen geändert werden.
Da „defaultValue“ im api-Objekt referenziert wird (rot umrandet), muss die Referenz durch die Art der Connection, hier sql, ersetzt werden.
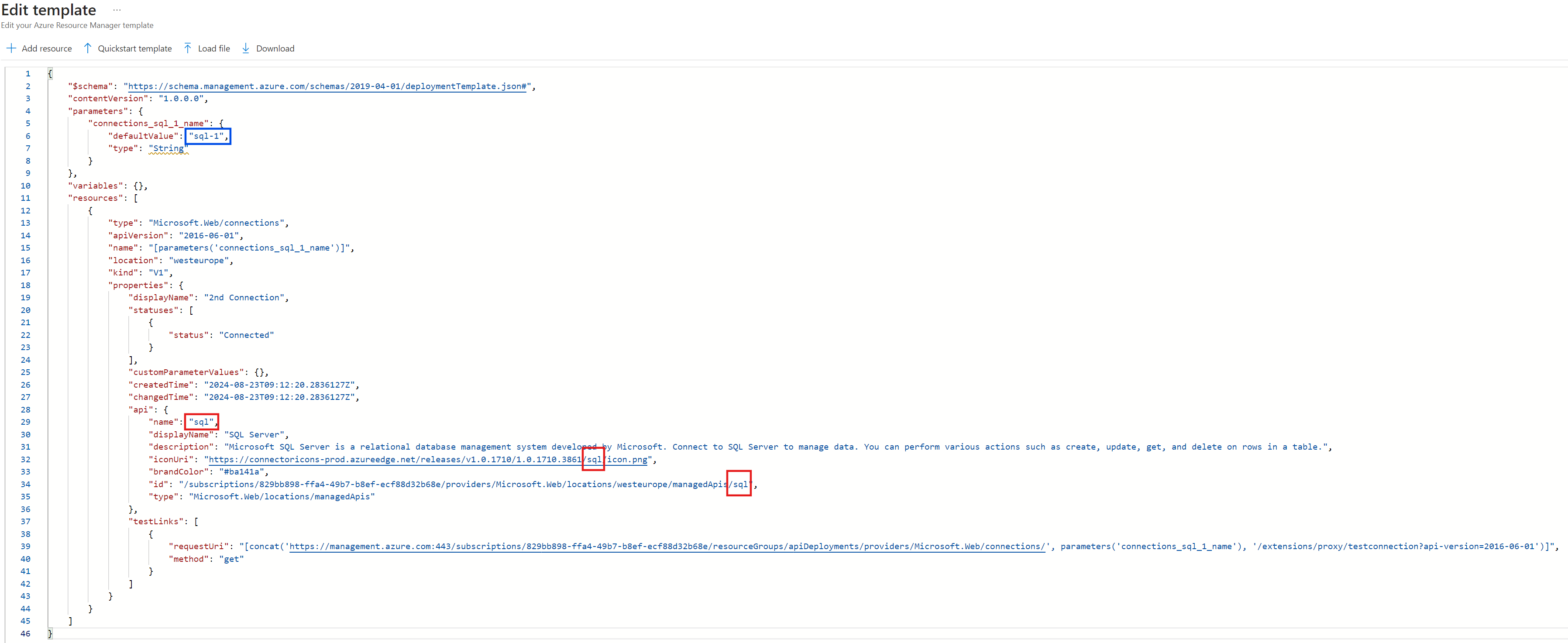
Das Referenzieren des „defaultValues“ findet man logischerweise nur im api-Objekt, wenn die API-Connection wie die Art der Connection (z.B. sql) heißt. Wenn die umzubenennende API-Connection z.B. „sql-1“ heißt, werden die vorherigen Parameterreferenzen hartkodiert:
Nach dem Deployment der neuen API-Verbindung wird schnell klar, dass diese noch keine Verbindung zur gewünschten Quelle herstellen kann, da keine Zugangsdaten oder sonstige Authentifizierungsinformationen im ARM-Template enthalten bzw. übergeben worden sind. Diese Informationen müssen manuell über die Benutzeroberfläche des Azure Portals hinzugefügt werden:
Mögliche Probleme
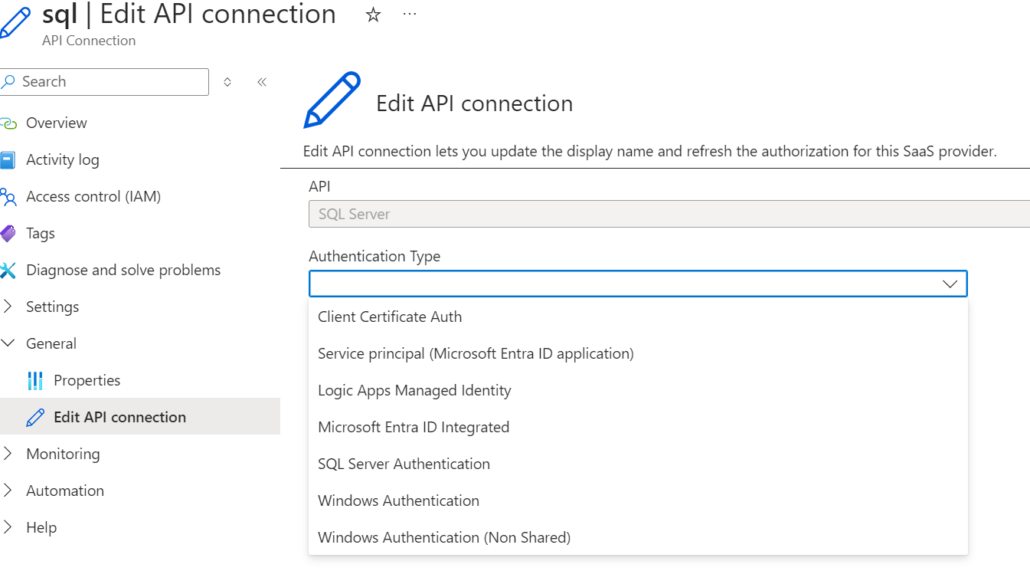
Ein Problem bei dieser Art der Bereitstellung von API-Connections ist, dass bestimmte Konfigurationen, wie der „Authentication Type“, fest vom vorherigen Template übernommen werden. Im Vergleich zu den manuell erstellten API-Connections, die angepasst werden können, sind sie nicht mehr flexibel. Dies kann insbesondere dann problematisch werden, wenn die Sicherheitsanforderungen sich ändern und der Authentifizierungstyp entsprechend angepasst werden muss.
Automatisch erstellte API-Connection vs. Custom ARM-Template Deployment
Um die oben genannten Einschränkungen zu überwinden, kann das ParameterValueSet-Objekt im properties-Objekt des ARM-Templates hinzugefügt werden. Dieses Objekt ermöglicht eine flexible Konfiguration der API-Verbindung.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"connections_cooleAPI_name": {
"defaultValue": "cooleAPI",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.Web/connections",
"apiVersion": "2016-06-01",
"name": "[parameters('connections_cooleAPI_name')]",
"location": "westeurope",
"kind": "V1",
"properties": {
"displayName": "DWH-Connection",
"statuses": [
{
"status": "Connected"
}
],
"parameterValueSet": {
"name": "placeholder",
"values": {}
},
"customParameterValues": {},
"createdTime": "2024-08-27T06:40:25.2075565Z",
"changedTime": "2024-08-27T07:44:30.0313207Z",
"api": {
"name": "sql",
"displayName": "SQL Server",
"description": "Microsoft SQL Server is a relational database management system developed by Microsoft. Connect to SQL Server to manage data. You can perform various actions such as create, update, get, and delete on rows in a table.",
"iconUri": "https://connectoricons-prod.azureedge.net/releases/v1.0.1710/1.0.1710.3861/sql/icon.png",
"brandColor": "#ba141a",
"id": "/subscriptions/829bb898-ffa4-49b7-b8ef-ecf88d32b68e/providers/Microsoft.Web/locations/westeurope/managedApis/sql",
"type": "Microsoft.Web/locations/managedApis"
},
"testLinks": [
{
"requestUri": "[concat('https://management.azure.com:443/subscriptions/829bb898-ffa4-49b7-b8ef-ecf88d32b68e/resourceGroups/apiDeployments/providers/Microsoft.Web/connections/', parameters('connections_cooleAPI_name'), '/extensions/proxy/testconnection?api-version=2016-06-01')]",
"method": "get"
}
]
}
}
]
}
Das parameterValueSet-Objekt wird in ARM-Templates eigentlich verwendet, um Parameterwerte einer API-Connection zu definieren und zu konfigurieren. Es besteht hauptsächlich aus zwei Komponenten:
name: Der Name der Connection-Art, z.B. „keyBasedAuth “, „managedIdentityAuth“, etc. In der Regel entspricht der Name also einer vordefinierten Gruppe von Werten, die von der API erwartet werden.
values: Das Kernstück des parameterValueSet-Objekts, da es die tatsächlichen Verbindungsdaten enthält, die für die API-Connection benötigt werden.
Da wir in unserem Beispiel keine Credentials im Code übergeben wollen, sondern diese wie bisher über die Benutzeroberfläche im Azure Portal setzen wollen, lassen wir das Values-Objekt leer und übergeben dem name-Key einen zufälligen Wert.
Nach dem Deployment kann man nun die Verbindungsdaten hinzufügen, wie in den vorherigen Schritten schon beschrieben.
Deployment mit einem PowerShell Skript
Um die Fehleranfälligkeit zu reduzieren und repetitive Arbeit zu vermeiden, können einige der bisher händisch ausgeführten Schritte mithilfe eines PowerShell Skriptes automatisiert werden. Das nachfolgende Skript führt unter der Angabe von Daten (Subscription Id, Name der Ressourcengruppe, Connection Name, etc.) folgende Aufgaben aus und erzielt das gleiche Ergebnis wie das händisch bearbeitete ARM-Template:
Herunterladen des ARM-Templates einer angegebenen API-Connection
Ändern des defaultValues in den gewünschten API-Connection Namen
Ersetzen von Parameterreferenzen im API-Objekt
Hinzufügen des ParameterValueSet-Objekts
Deployment der API-Connection in der angegebenen Ressourcengruppe unter dem angegeben Ressourcennamen
Nachdem das Skript erfolgreich durchgelaufen ist, erscheint die API-Connection in der gewünschten Ressourcengruppe. Jetzt müssen die Verbindungsdaten noch manuell über das Azure Portal gesetzt werden, bevor die API-Connection einsatzbereit ist.
$subscriptionId = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" # Your SubscriptionId
$rg = "apiDeployments"
$apiConnectionName = "sql"
$newApiConnectionName = "sql_dev"
$connectionType = "sql" # z.B. sql, azureblob, ftp
#SetContext
Set-AzContext -Subscription $subscriptionId
#Export template
$APIConnectionID=$(az resource show --resource-group $rg --name $apiConnectionName --resource-type Microsoft.Web/connections --query id --output tsv)
az group export --resource-group $rg --resource-ids $APIConnectionID > template.json
# Load JSON content into a variable
$jsonFile = "template.json"
$jsonContent = Get-Content -Path $jsonFile -Raw | ConvertFrom-Json
#Build ParameterName
$parameterConnectionName = $apiConnectionName.Replace('-','_')
$ParameterName = "connections_${parameterConnectionName}_name"
# Check if the 'defaultValue' property exists and add it if necessary
if (-not $jsonContent.parameters.$ParameterName.PSObject.Properties['defaultValue']) {
# Add the 'defaultValue' property with the desired value
$jsonContent.parameters.$ParameterName | Add-Member -MemberType NoteProperty -Name defaultValue -Value $NewApiConnectionName
} else {
# If exists, just update the value
$jsonContent.parameters.$ParameterName.defaultValue = $newApiConnection
}
# Access the specific resource and add the parameterValueSet if it doesn't exist
$jsonResource = $jsonContent.resources[0] # Assuming there's only one resource in the array
# Check if 'parameterValueSet' exists & add the 'parameterValueSet' property
if (-not $jsonResource.properties.PSObject.Properties['parameterValueSet']) {
$parameterValueSet = @{
name = "hasToBeSetInThePortal"
values = @{}
}
$jsonResource.properties | Add-Member -MemberType NoteProperty -Name parameterValueSet -Value $parameterValueSet
}
# Update the api properties (only if API Connectionname = ConnectionType)
if ($apiConnectionName -eq $connectionType) {
$jsonResource.properties.api.name = $ConnectionType
$jsonResource.properties.api.iconUri = $jsonResource.properties.api.iconUri -replace [regex]::Escape("parameters('$($ParameterName)')"), "'$($ConnectionType)'"
$jsonResource.properties.api.id = $jsonResource.properties.api.id -replace [regex]::Escape("parameters('$($ParameterName)')"), "'$($ConnectionType)'"
}
# Convert the modified JSON back to a string
$updatedJsonContent = $jsonContent | ConvertTo-Json -Depth 10
# Save the updated JSON back to the file
Set-Content -Path $jsonFile -Value $updatedJsonContent
# Deploy the new Api Connection
New-AzResourceGroupDeployment -Mode Incremental -Name "${NewApiConnectionName}-Deployment" -ResourceGroupName $rg -TemplateFile $jsonFile
Write-Host 'Deployment done'
Fazit:
API-Connections sind ein unverzichtbarer Bestandteil von Azure Logic Apps, da sie die Integration und den Zugriff auf externe Dienste und Datenquellen ermöglichen. Wenn jedoch zahlreiche verschiedene Datenquellen genutzt werden, kann die Verwaltung der API-Connections schnell unübersichtlich und komplex werden. Die in diesem Blog-Post beschriebenen Methoden bieten Strategien, um Struktur in die Verwaltung zu bringen und die Übersichtlichkeit zu verbessern, indem sie es erlauben entsprechende Ressourcennamen für API-Connections zu setzen
Darüber hinaus eröffnen diese Ansätze die Möglichkeit, Skripte und Methoden weiterzuentwickeln, um beispielsweise API-Connections nahtlos in CI/CD-Prozesse zu integrieren und automatisch mit den benötigten Verbindungsdaten zu deployen.
https://www.scieneers.de/wp-content/uploads/2024/09/Unbenannt.png10801920Maximilian Leisthttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngMaximilian Leist2024-09-20 16:23:142025-01-31 13:33:43Logic App API Connections – Herausforderungen und Lösungswege in der Verwaltung
Zusammen mit der Carl Remigius Fresenius Education Group (CRFE) entwickelten wir NextGeneration:AI. Dabei handelt es sich um eine datenschutzkonforme Plattform zur Nutzung von Sprachmodellen für alle Studierende und Mitarbeitende der CRFE. Das besondere an NextGeneration:AI ist die Authentifizierung über das Learning Management System Ilias mit Hilfe einer LTI-Schnittstelle, sowie die umfassende Personalisierbarkeit, die Nutzer:innen geboten wird. Im Blogartikel gehen wir auf die Details der Implementierung ein.
350 Millionen, fast 5% der Weltbevölkerung leben mit einer seltenen Erkrankung. Etwa 75% der seltenen Erkrankungen betreffen Kinder. 80% dieser Erkrankungen entstehen durch eine einzige genetische Veränderung und können durch eine Genomanalyse diagnostiziert werden. Das menschliche Genom besteht aus etwa 3.3 Milliarden Bausteinen und jeder Mensch trägt etwa 3.5 Millionen Varianten. Die Suche nach der einen, pathogenen Variante, als Ursache der Krankheit, gleicht der Suche nach der Nadel im Heuhaufen.
https://www.scieneers.de/wp-content/uploads/2024/02/dna-3539309_1920.jpg9601920Martin Dannerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngMartin Danner2024-02-29 16:55:032024-03-01 12:56:49Erforschung des Dark Genome mit Machine Learning zur Entwicklung neuartiger Krankheitsinterventionen
Zusammen mit der RWTH Aachen University haben wir rwthGPT entwickelt: Eine datenschutzkonforme Plattform zur Nutzung von OpenAI-Modellen für Studierende und Mitarbeitende. Ergänzt wird rwthGPT durch ein dediziertes User-Management mit Kostenzuordnung, das Speichern von Chat-Verläufen und Talk to your Data. Wir werfen einen detaillierten Blick auf die Datenschutz-relevanten Aspekte.
Hands-on Umsetzung Ihres ersten Use Cases auf der Microsoft Azure Data Platform mit Ihren Daten. Dabei Durchstich durch alle Komponenten und logischen Schichten nach best practices.
https://www.scieneers.de/wp-content/uploads/2023/11/adp_poc_website.jpg6831024Stefan Kirnerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngStefan Kirner2023-11-17 09:49:122025-06-18 15:15:51Azure Data Platform Proof of Concept