

Multi-Agenten LLM auf der Data2Day
Die Data2Day ist eine von wenigen deutschen Konferenzen, deren Thema nicht primär auf AI oder Machine Learning liegt, sondern sich dem Datenmanagement widmet. Sie wird vom Heise Verlag ausgerichtet und fand bereits zum achten Mal statt. Wir waren mit dabei und haben uns bemüht, mit unserem Vortrag eine Brücke zwischen beiden Themen zu schlagen: ‚SiloX-GPT: Daten-Silos verbinden mittels Multi-Agenten-System‘.
Unser Vortrag zu Multi-Agenten-Systemen

Gemeinsam mit Bertelsmann konnten wir die Ergebnisse unseres Content-Search Projektes vorstellen. In diesem Projekt lösen wir das Problem, dass es aufgrund der großen und verzweigten Firmenstruktur der sogenannten Berthelsphere keinen Ort gibt, wo sämtliche Daten der unterschiedlichen Bereiche entdeckt werden können. Wir lösen das Problem der sehr heterogenen Datenlandschaft dabei mit Hilfe von LLM-Agenten, welche mit Hilfe von Tools APIs abfragen, Knowledge-Graphs durchsuchen oder klassisches RAG durchführen können. Orchestriert wird all dies mit Hilfe von LangGraph, welches erlaubt Langchain-basierte Agenten und andere Verarbeitungsknoten in einem Kommunikationsgraphen frei zu modellieren. Neben der Vorstellung des Systems standen auch zahlreiche Learnings im Zentrum des Talks, denn in der ersten Zusammenarbeit zwischen Bertelsmann und Scieneers stand zunächst eine Evaluation der neuen technischen Möglichkeiten von LLMs im Zusammenspiel mit einem Knowledge-Graph im Vordergrund. Erst über mehrere Iterationen mit verschiedenen Stakeholdern hinweg entwickelte sich daraus die eigentliche Produktidee. Einige der wichtigen Learnings waren:
- Technologie-Exploration und Produktentwicklung haben sehr unterschiedliche Anforderungen an Team, Organisationsform und Zielstellung
- Tracing und Monitoring ist bei LLM-Applikationen mindestens so wichtig wie bei klassischer Softwareentwicklung, um ein resilientes und stabiles System zu entwickeln
- Ein Multi-Agenten-Setup ähnelt einem Micro-Service-Design und bringt ähnliche Vorteile: Modulare Komponenten sorgen für bessere Wartbarkeit und Stabilität
- LLM-Agenten sind mächtige Werkzeuge. Entscheidend ist dabei eine klare Ausrichtung des Prompts und der verwendeten Tools getreu dem UNIX-Motto: Do just one thing and do it well!
Die weiteren wichtigen Themen der Konferenz
In der Eröffnungskeynote zeigte Dr. Sarah Henni von EnBW auf unterhaltsame Art den ChatGPT-Moment, als AI im Alltag vieler Menschen ankam und Postfächer von Data Science Abteilungen geflutet wurden. Seitdem wurden zahlreiche „Hook“-Projekte realisiert, die wichtig sind, um die neue Technologie zu erproben und ins Gespräch darüber zu kommen, wo nun die wirklichen Transformations-Potentiale liegen. Diese Einschätzung können wir nur bestätigen, denn nach vielen PoCs im Jahr 2023 liegt der Fokus dieses Jahr auch in unseren Projekten nun mehr auf Produktivierung, Stabilität und Resilienz. Außerdem haben immer mehr Projekte neben strategischen Zielen auch klare finanzielle KPIs.
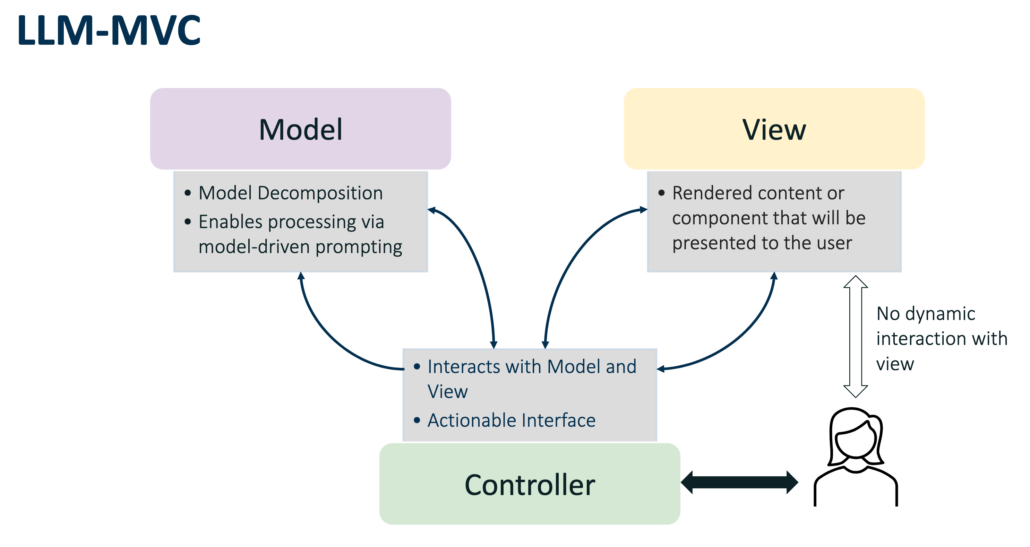
Ein weiterer spannender Vortrag kam von Robert Bauer von der HMS Analytical Software. Er nutzte das aus der Applikationsentwicklung bekannte MVC-Pattern, um LLM-Applikationen zu strukturieren. Soll etwa ein Blog-Eintrag von einem LLM verfasst werden, so werden die einzelnen notwendigen Felder (wie Überschrift, Volltext, Excerpt, Tags, SEO-Text etc.) mit Hilfe von Pydantic als Modell repräsentiert. Die View hat dann ausschließlich die Aufgabe, dieses rein-textuelle Modell mit Hilfe von HTML-Templates in einen ansprechend formatierten Eintrag zu überführen. Der Controller übernimmt schließlich mit Hilfe unterschiedlicher, möglichst atomarer und damit besser promptbarer LLM-Calls das Befüllen des Modells.
Der Ansatz überzeugt vor allem, weil er bei der Strukturierung des Codes hilft und ermöglicht eine große LLM-Anfrage in mehrere kleinere, für das LLM besser verarbeitbare Abfragen zu zerlegen. Darüber hinaus lassen sich mit Hilfe des Modells abhängige Felder identifizieren (der SEO-Text hängt beispielsweise von Überschrift und Text ab), die automatisch als invalide markiert werden können, wenn sich im Abhängigkeitsbaum zuvor etwas geändert hat.
Natürlich haben auch bekannte Data Management Themen wie etwa Data Mesh, Knowledge Graphs oder Data Contracts das Programm der Data2Day bestimmt. Aber auch diese wurden entsprechend um AI erweitert: So zeigten die Macher von datacontract.com ihren GPT-Bot zur automatischen Erzeugung von Verträgen.
Zu guter Letzt war auch der AI-Act ein wichtiges Thema der Konferenz. Gut gefallen hat uns hier vor allem die Sichtweise von Larysa Visengeriyeva, die ihn im Wesentlichen als rechtliche Verpflichtung von Software-Best-Practices (wie etwa Transparenz, Erklärbarkeit, Data Governance, Fehlertoleranz/Resilienz, Dokumentation) für AI darstellte.
Bei der Gelegenheit wollen wir uns abschließend beim Heise Verlag für die Durchführung der gelungenen Konferenz und das Vernetzen der vielen engagierten Sprecher und Teilnehmer bedanken.

Nico Kreiling, Data Scientist bei scieneers GmbH
nico.kreiling@scieneers.de

