Lernen Sie Microsoft Fabric in unseren Webinaren kennen
Einführung
Unsere Termine
In unserem kostenfreien Webinar geben wir Sie eine Einführung in Microsoft Fabric und zeigen live, wie Sie mit Lakehouse, Dataflows und Power BI Dashboards arbeiten.
In unserem kostenfreien Webinar erhalten Sie einen fundierten Einblick mit spannenden Live-Demos in die Erstellung von Echtzeit-Dashboards mit der Kusto Query Language (KQL).
Microsoft Fabric ist eine vielseitige und leistungsstarke Plattform für aktuelle Daten- und Analyseanforderungen und genießt derzeit große Aufmerksamkeit bei unseren Kunden. Dabei begegnen wir ganz unterschiedlichen Bedürfnissen – abhängig von Unternehmensgröße, Datenkultur und dem jeweiligen Entwicklungs- und Analysefokus.
Kunden aus dem Power-BI-Umfeld profitieren insbesondere von der Erweiterung des Self-Service-Ansatzes: Über vertraute Weboberflächen und ohne spezialisierte Entwicklungsprogramme können selbst Fachabteilungen oder Enduser schnell in die Datenaufbereitung einsteigen.
Erfahrene Entwickler:innen und IT-Teams möchten hingegen sicherstellen, dass sie in Fabric nicht auf bewährte Abläufe, wie die Entwicklung in einer IDE, Versionsverwaltung via Git oder etablierte Test- und Rollout-Prozesse, verzichten müssen. Dabei stellt sich die Frage, wie zentrale Änderungen robust geprüft und einer Vielzahl von Usern zur Verfügung gestellt werden können.
In diesem Blogpost möchten wir einen Überblick über die Entwicklungs- und Kollaborationsmöglichkeiten sowie die verschiedenen Deployment-Szenarien in Fabric geben. Obwohl wir versuchen, einen allgemeinen Überblick darzustellen, arbeitet Microsoft aktuell mit Hochdruck an neuen Funktionen und Verbesserungen für Fabric, sodass sich technische Einzelheiten mit der Zeit ändern können. Der jeweils aktuelle Stand zur Entwicklung von Fabric ist in der offiziellen Dokumentation oder im Microsoft-Fabric-Blog zu finden.
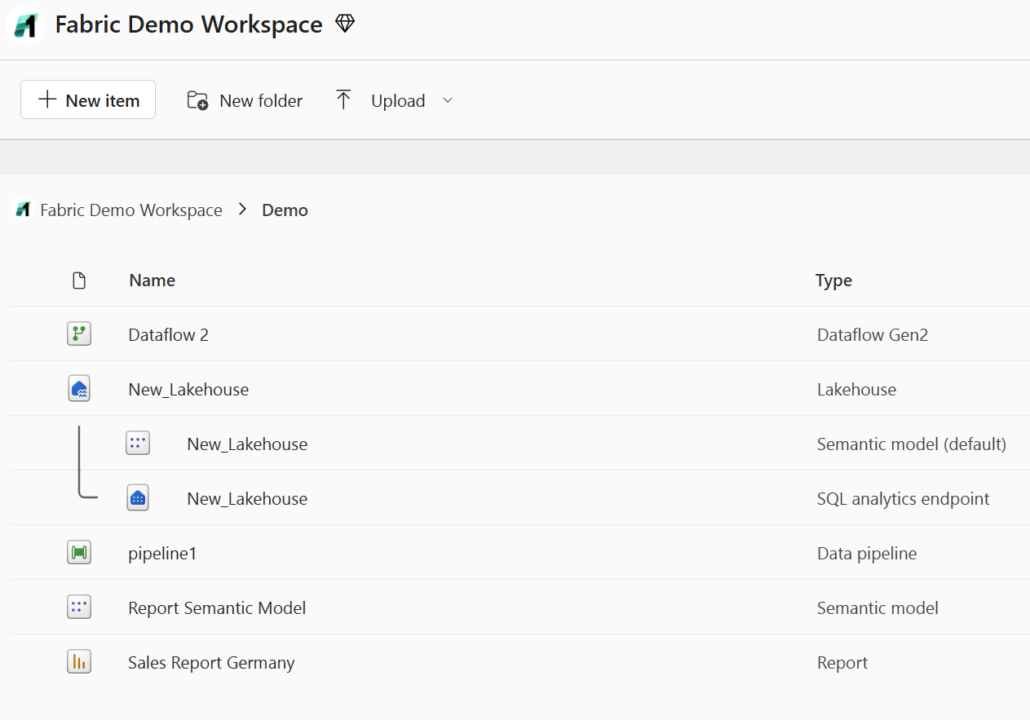
Fabric als Software-as-a-Service wird in der Regel direkt über den Browser bedient.
Wer bereits den Power BI Service kennt, findet sich dank des vertrauten Workspace-Konzepts sofort zurecht. Neue Fabric-Objekte wie Dataflows oder Data Pipelines lassen sich unkompliziert in der Weboberfläche erstellen und bearbeiten – eine lokale Entwicklungsumgebung oder zusätzliche Softwareinstallationen sind dafür nicht nötig.
Ein weiterer wesentlicher Vorteil der browserbasierten Entwicklung in Fabric ist die plattformunabhängige Nutzbarkeit unter Windows und macOS. Allerdings sind Entwicklungsumgebung im Browser allgemein weniger flexibel und anpassbar als eine vollständige Entwicklungsumgebung (IDE), da nur ein eingeschränkter Umfang an Tools und Integrationsmöglichkeiten zur Verfügung steht. Das ist auch in Bezug auf Fabric der Fall.
Änderungen an Fabric-Objekten sind sofort live und können direkt von anderen Usern gesehen und getestet werden, wodurch sich die Entwicklungszyklen deutlich beschleunigen. Allerdings bringt diese unmittelbare Sichtbarkeit auch Risiken mit sich: Fehler oder ungewollte Änderungen wirken sich sofort auf alle User aus und lassen sich nicht so einfach rückgängig machen wie in lokal gespeicherten Dateien.
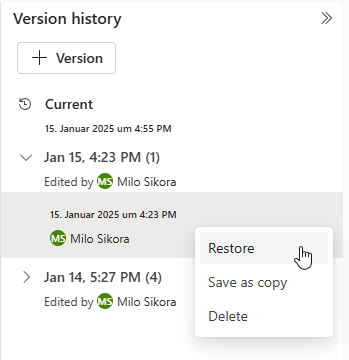
Aus diesem Grund arbeitet Microsoft an einer integrierten Versionierung, inklusive Rollback-Funktionalität für verschiedene Fabric-Objekte. Für Notebooks ist diese Funktion bereits verfügbar, für semantische Modelle befindet sie sich aktuell in der Preview-Phase.
Trotz einiger Einschränkungen bei Flexibilität und Tool-Integration bietet die Weboberfläche damit einen schnellen, bequemen Einstieg in die Entwicklung und vereinfacht die Zusammenarbeit in verteilten Teams. Beispielsweise unterstützt die Notebook-GUI paralleles Arbeiten, einschließlich Kommentaren und Cursor-Highlighting, was Pair Programming, Remotedebugging oder auch Tutoren-Szenarien erleichtert.
Dieser Entwicklungsprozess ist vor allem für Szenarien geeignet, in denen eine isolierte Entwicklung nicht erforderlich ist und Änderungen direkt am Live-Stand vorgenommen werden können – beispielsweise für Enduser in nicht-technischen Fachabteilungen oder weniger kritische Anwendungsfälle.
Benötigt man hingegen eine dedizierte Umgebung, um neue Funktionen oder Anpassungen zu testen, ohne den Live-Stand zu beeinflussen, stehen grundsätzlich zwei Ansätze zur Verfügung.
2. Isolierte Entwicklung mittels lokaler Client-Tools
Für verschiedene Fabric-Objekte stehen Client-Tools zur Verfügung, die auf einem Rechner installiert werden können und mit denen sich diese Objekte lokal bearbeiten lassen. Meist wird dazu eine lokale Kopie des Fabric-Objekts erzeugt, diese wird bearbeitet und nach Fertigstellung aller Änderungen wieder in den Fabric Workspace hochgeladen.
Power-BI-User kennen diesen Ablauf bereits: Ein Power-BI-Report aus Fabric kann als .pbix-Datei heruntergeladen und mit Power BI Desktop lokal bearbeitet werden. Die Änderungen am Report werden in Fabric erst sichtbar, wenn man die lokalen Änderungen veröffentlicht. Vergleichbar läuft das Bearbeiten von Fabric-Notebooks ab, welche als .ipynb-Datei exportiert und lokal mit den präferierten Entwicklungstools bearbeitet werden können. Für VS Code gibt es eine Erweiterung (derzeit noch unter dem Namen „Synapse“) die diesen Prozess vereinfacht.
Hat man diese VS-Code-Erweiterung installiert, kann man direkt über einen Button in der Fabric-GUI eine lokale Kopie des gewünschten Notebooks erzeugen und in VS Code öffnen.
So arbeitet man in einer gewohnten Entwicklungsumgebung. Bei Bedarf kann man den Code über die fabric-spark-runtime sogar auf der Fabric-Kapazität ausführen lassen und damit große Datenmengen verarbeiten. Sobald alle Änderungen am Notebook erfolgt sind, lädt man die angepasste Version einfach wieder über das VS-Code-Plugin in den Fabric Workspace hoch – inklusive praktischer Diff-Funktion, um Unterschiede gegenüber der Version im Fabric Workspace anzuzeigen.
Darüber hinaus kann auch in anderen Bereichen mit lokalen Tools auf die Fabric-Umgebung zugegriffen werden. Beispielsweise lassen sich VS Code oder SQL Server Management Studio verwenden, um SQL-Abfragen zu schreiben oder Views zu definieren. Besonders das Fabric Warehouse ist aktuell gut in diese Tools integriert, eine Verbindung ist grundsätzlich aber mit allen SQL-basierten Fabric-Objekten möglich.
Die vorgestellten Funktionen sind ohne eine Anbindung des Fabric-Workspaces an ein Git-Repository nutzbar. Damit eignet sich dieser Prozess besonders für User, die eine isolierte Entwicklungsumgebung benötigen, jedoch noch keine Erfahrung mit Git haben oder deren Workspaces aus organisatorischen Gründen (noch) nicht an ein Git-Repository angebunden sind.
Für erfahrene Entwickler:innen ist eine Git-Integration jedoch ein zentraler Baustein professioneller Entwicklungsprozesse. Aus diesem Grund bietet Microsoft Fabric auch eine native Integration in Azure DevOps und GitHub.
Einschub: Fabric Git-Integration
Microsoft Fabric ermöglicht es, einen Workspace mit einem Azure DevOps- oder GitHub-Repository zu verbinden, um die Vorteile eines Git -integrierten Entwicklungsprozesses, wie beispielsweise die Versionierung, zu nutzen. Eine ausführliche Erläuterung aller Funktionen und Einschränkungen dieser Funktionalität findet sich hier.
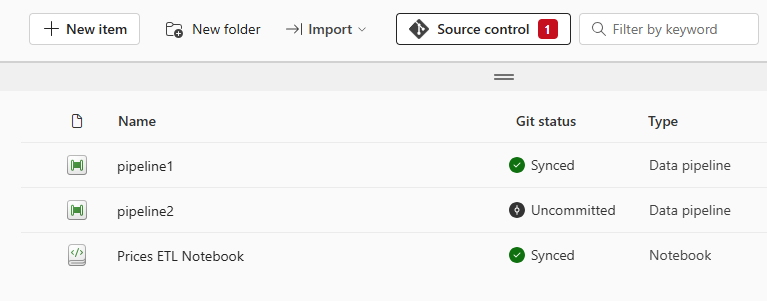
Ist ein Workspace an ein Repository angebunden, kann jederzeit der Git-Status der einzelnen Fabric-Objekte eingesehen werden. Änderungen an Objekten oder das Erstellen neuer Objekte können direkt aus der GUI heraus committet und in dem Repository gespeichert werden. Dadurch ist sicher gestellt, dass versehentlich gelöschte Objekte jederzeit wiederhergestellt werden können.
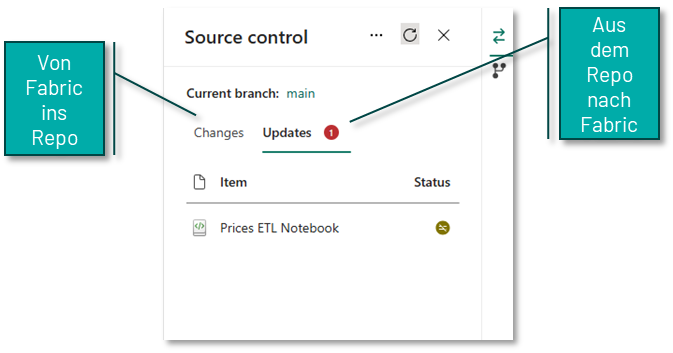
Es ist wichtig zu verstehen, dass diese Synchronisation zwischen Fabric und dem Repository in beide Richtungen erfolgen kann. Es können also Änderungen aus Fabric in das Repository gesichert werden und ebenso Änderungen an den Objekten im Repository (z.B. wenn ein Notebook direkt im Repository bearbeitet wurde) zurück in den Fabric Workspace importiert werden.
Wenn der Fabric Workspace Git-integriert ist, eröffnet das weitere Möglichkeiten, lokal mit verschiedenen Fabric-Elementen zu arbeiten. Durch das Klonen des entsprechenden Repositories kann man alle bekannten Git-Features nutzen, wie zum Beispiel lokale Feature-Branches oder einzelne Commits für wichtige Zwischenstände.
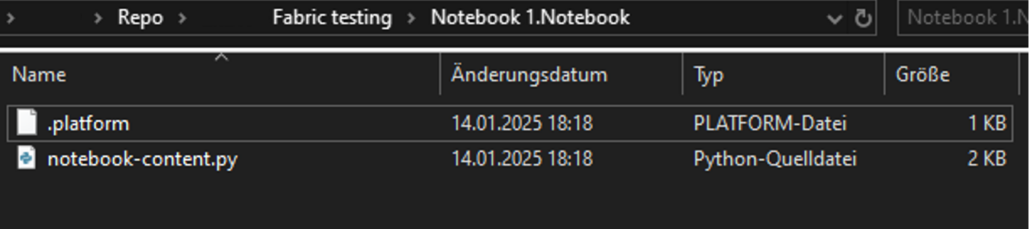
Ein Nachteil dabei ist jedoch, dass einzelne Fabric-Objekte im Repository in Formaten gespeichert werden, die primär auf eine Git-optimierte Speicherung und nicht auf eine komfortable Bearbeitung ausgelegt sind. Notebooks werden beispielsweise nicht als .ipynb-Dateien gespeichert, sondern als reine .py-Dateien, ergänzt durch eine zusätzliche .platform-Datei, die wichtige Metadaten enthält. Das kann das lokale Arbeiten mit Branches im Repository erschweren.
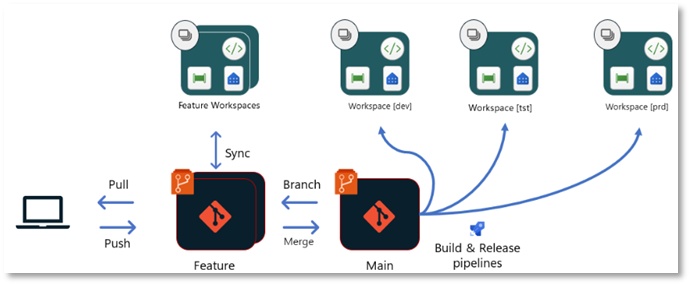
3. Isolierte Entwicklung in Feature-Branch Workspaces
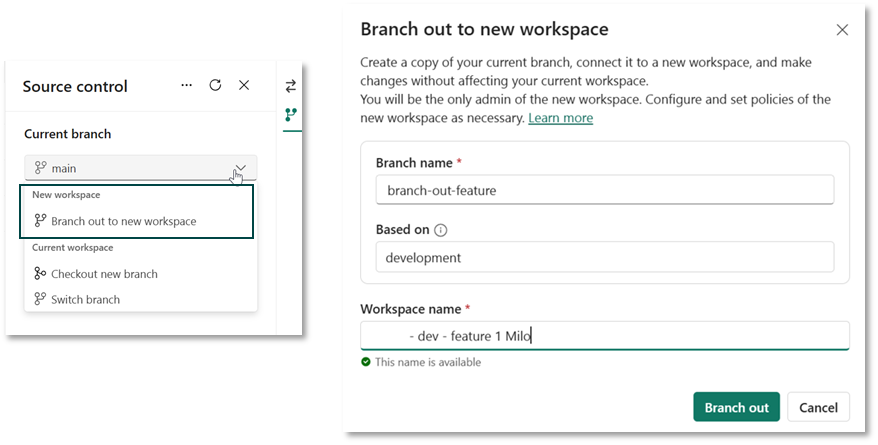
Um eine isolierte Entwicklungsumgebung zu erreichen, muss man in Fabric nicht zwangsläufig auf lokale Tools ausweichen. Fabric bietet – vorausgesetzt, der Workspace ist Git-integriert – auch native Möglichkeiten. Besonders interessant ist hierbei die Funktion “Branch out to a new feature-workspace”, die hier näher beschrieben wird.
Nutzt man dieses Feature, wird eine Kopie des Workspaces erstellt, auf den zunächst nur man selber Zugriff hat. In diesem kann man isoliert entwickeln, ohne die Funktionalität der Objekte im eigentlichen Workspace zu beeinflussen. Im Hintergrund passiert Folgendes:
Es wird ein neuer, leerer Workspace mit dem definierten Namen angelegt.
In diesen Branch wird der Inhalt des aktuellen Workspaces kopiert.
Im Repository wird ein neuer Branch angelegt, dessen Namen ebenfalls bestimmt werden kann.
Im neu angelegten Workspace werden die Fabric-Objekte basierend auf dem neu angelegten Branch erstellt.
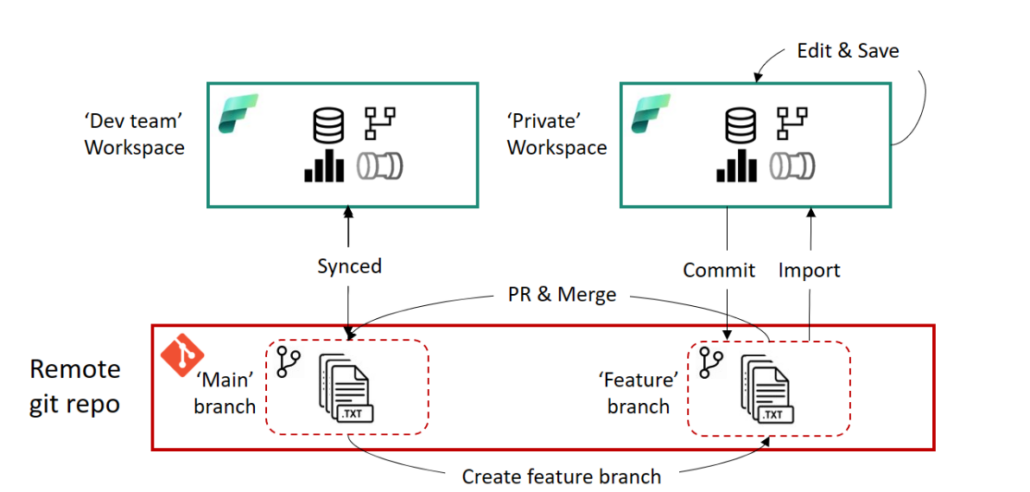
Man kann nun isoliert an den Fabric-Objekten arbeiten und die Änderungen in den neuen Branch committen, beispielsweise wenn man an einem Notebook weiterentwickeln möchte. Wichtig hierbei ist, dass Daten (z.B. in einem Lakehouse) nicht im Repository gespeichert werden und somit auch nicht in dem neuen Workspace zur Verfügung stehen. Das bedeutet, ein Notebook verbindet sich weiterhin mit dem Lakehouse in dem eigentlichen Workspace, wenn dieses im Notebook als Datenquelle genutzt wurde.
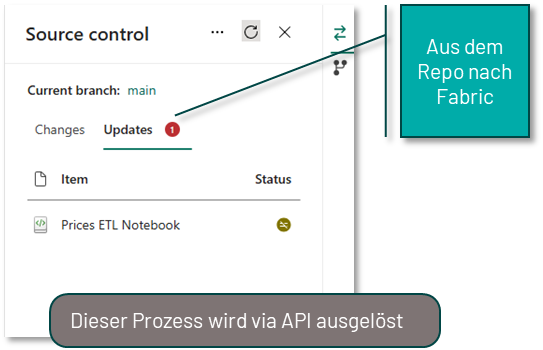
Hat man alle Änderungen in dem Feature-Workspace durchgeführt, muss man diese Änderungen noch zurück in den eigentlichen Workspace übertragen. Dieser Prozess erfolgt primär in Azure DevOps bzw. GitHub und setzt ein grundlegendes Verständnis von Git voraus. Man erstellt hierfür einen Pull-Request (PR), um den Feature-Branch in den Main-Branch des eigentlichen Workspaces zu mergen. Hierbei stehen alle gewohnten Funktionalitäten von DevOps und GitHub zur Verfügung, wie z.B. das Taggen von Reviewern. Ist der PR erfolgreich abgeschlossen, hat der Main-Branch im Repository einen aktuelleren Stand als die Fabric-Objekte im Workspace selbst. Abschließend muss der Stand aus dem Repository also noch in den Workspace übertragen werden. Hierfür kann man den oben beschriebenen Prozess des Updates im Source Control Panel des Fabric Workspaces nutzen oder diesen Prozess via API automatisieren.
Das folgende Diagramm veranschaulicht diesen Prozess.
Dieser Entwicklungsprozess bietet die umfassenden Vorteile einer Git-basierten Entwicklung und lässt sich bei Bedarf zusätzlich mit lokalen Client-Tools ergänzen. So ist es beispielsweise möglich, die Notebooks im Feature-Workspace über den oben beschriebenen Prozess in VS Code zu öffnen.
Dennoch bringt dieser Prozess auch einige Nachteile mit sich. Da Pull-Requests und Merges in Azure DevOps bzw. GitHub durchgeführt werden, setzt dieser Prozess Erfahrung im Umgang mit Git sowie Azure DevOps oder GitHub voraus. Außerdem müssen User, die dieses Feature in Fabric nutzen möchten, die Berechtigung haben, Workspaces zu erstellen, was zunächst von einem Administrator freigegeben werden muss. Zum aktuellen Zeitpunkt werden die Feature-Workspaces zudem nicht automatisch gelöscht, nachdem ein erfolgreicher Merge in den Ausgangs-Workspace durchgeführt wurde. Dies kann dazu führen, dass sich im Laufe der Zeit einige nicht mehr benötigte Workspaces ansammeln, wenn diese nicht manuell gelöscht werden.
Deployment Prozesse
Ein weiterer Schritt zur Professionalisierung des Einsatzes von Microsoft Fabric besteht darin, Workloads in mehreren Umgebungen bzw. Environments zu betreiben. In der Regel wird zwischen einer Entwicklungsumgebung (Dev.) und einer Produktivumgebung (Prod.) unterschieden. Dies ermöglicht es, den Workload in der Entwicklungsumgebung isoliert und iterativ weiterzuentwickeln, während die Enduser in der Produktivumgebung jederzeit eine funktionierende und gut dokumentierte Version des Workloads vorfinden.
Sobald ein zufriedenstellender Punkt im Entwicklungsprozess erreicht ist, wird der Entwicklungsstand von der Entwicklungsumgebung in die Produktivumgebung übertragen. Dieser Vorgang wird als Deployment-Prozess bezeichnet. Microsoft Fabric bietet hierfür verschiedene Möglichkeiten.
1. Fabric Deployment Pipelines
Die einfachste Möglichkeit, einen Deployment-Prozess in Fabric zu integrieren, sind die sogenannten Fabric Deployment Pipelines. Sie sind fester Bestandteil von Fabric und benötigen kein weiteres Tooling – um sie zu benutzen, muss der Entwicklungs-Workspace nicht einmal mit einem Git-Repository verknüpft sein.
Für jede Umgebung wird ein Workspace angelegt, und anschließend wird in dem Entwicklungs-Workspace eine Deployment Pipeline aufgesetzt. Über ein übersichtliches Interface definiert man, welche Fabric-Objekte vom Ausgangs-Workspace (in der Darstellung unten „Development“) in den Ziel-Workspace (in unserem Fall „Test“) übertragen werden sollen, und klickt auf „Deploy“.
Da sich unterschiedliche Umgebungen in der Regel in ihren Eigenschaften unterscheiden – beispielsweise in der Datenbank, auf die sie zugreifen – lassen sich für jedes Fabric-Objekt sogenannte Deployment-Rules definieren. Diese stellen sicher, dass diese Eigenschaften während des Deployment-Prozesses entsprechend angepasst werden.
Zum aktuellen Zeitpunkt sind diese Deployment-Rules jedoch noch nicht für alle Fabric-Objekte einsetzbar und unterstützen nur eine vordefinierte Auswahl an Eigenschaften, die angepasst werden können. So kann man beispielsweise in einem Fabric-Notebook keine zuvor im Code definierten Parameterwerte austauschen.
Insgesamt bieten die Fabric Deployment Pipelines einen einfachen Einstieg in die Entwicklung mit mehreren Umgebungen, ohne dass tiefgreifende Erfahrung mit Git notwendig ist. Sie eignen sich besonders für Workloads, die beispielsweise von nicht-technischen Fachabteilungen verwaltet werden, und stellen eine logische Erweiterung des Self-Service-Prinzips dar.
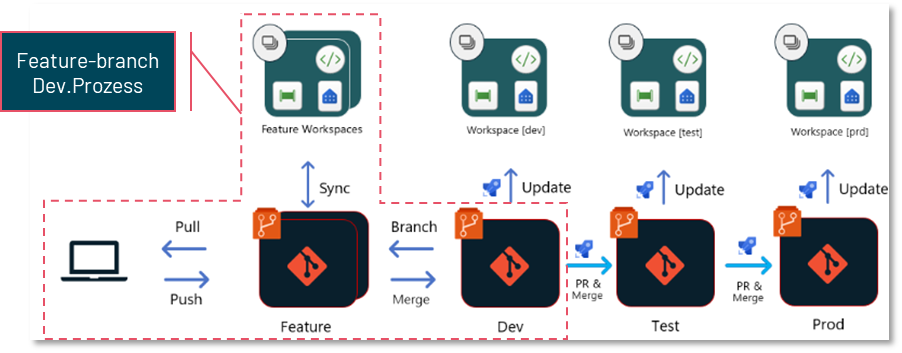
2. Branch-based Deployment
Die zweite Möglichkeit, einen Deployment-Prozess in Fabric umzusetzen, erfordert, dass alle Workspaces, die eine bestimmte Umgebung darstellen (z.B. Dev., Test. und Prod.), mit verschiedenen Branches desselben Git-Repositories verknüpft sind. Die Funktionsweise des branch-basierten Deployments ähnelt dem Feature-Branch-Entwicklungsprozess, der im folgenden Diagramm gekennzeichnet ist. Grundsätzlich ist der branch-basierte Deployment-Prozess jedoch mit allen Entwicklungsprozessen kombinierbar, solange eine Git-Integration eingerichtet ist.
Dieser Prozess nutzt die Funktionalität von Azure DevOps Pipelines (bzw. GitHub Actions), die automatisch auf Änderungen in Repository-Branches reagieren und bestimmte Prozesse anstoßen können.
Sobald ein neuer Entwicklungsstand in der Entwicklungsumgebung (Dev.) entwickelt wurde und bereit für das Deployment ist, wird im Repository ein Pull-Request (PR) in einen Test-Branch eröffnet. In diesem Branch können Reviewer die neuen Änderungen überprüfen und freigeben.
Nach der Freigabe und Aktualisierung des Test-Branches wird automatisch eine DevOps-Pipeline gestartet, die verschiedene Aktionen auf den Objekt-Definitionen in diesem Branch ausführt. Diese Pipeline kann beispielsweise Umgebungsparameter (wie Datenbankverbindungen) anpassen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht.
Der angepasste Code wird dann in einem weiteren Branch, wie z.B. Test-Release, gespeichert. Dieser Test-Release-Branch ist mit dem Test-Workspace in Fabric verbunden. Eine zweite Pipeline reagiert auf die Aktualisierung dieses Branches und sorgt über eine API dafür, dass der Stand aus diesem Branch in den Fabric-Workspace übertragen wird.
Im Test-Workspace können anschließend direkt in Fabric weitere Tests, wie Data-Quality-Tests, durchgeführt werden, bevor der Code über einen analogen Prozess in den produktiven Workspace übertragen wird.
Diese Form des Deployment-Prozesses erfordert neben dem Verständnis von Git auch Erfahrung im Aufsetzen von Azure DevOps Pipelines bzw. GitHub Actions und ist daher für erfahrene Entwickler:innen und kritische Workloads konzipiert. Die Verwendung professioneller Deployment-Tools bietet dann jedoch die volle Flexibilität in der Ausgestaltung des Deployment-Prozesses und der Integration erweiterter Schritte wie Code-Testing.
Die Arbeit mit dedizierten Branches pro Umgebung erlaubt außerdem das einfache Handling verschiedener Versionen in den einzelnen Umgebungen sowie das schnelle Zurückrollen auf vorherige Stände.
3. Release-Pipeline Deployment
Eine weitere Möglichkeit für ein Deployment in Fabric besteht darin, die einzelnen Workspaces nicht direkt über die integrierten Möglichkeiten mit einem Branch in einem Repository zu verbinden, sondern ausgehend von einem geteilten Main-Branch über Build- und Release-pipelines direkt in die einzelnen Workspaces zu deployen.
Bei diesem Ansatz kann – wie im vorherigen Prozess auch – eine Build-Pipeline je nach Zielumgebung Umgebungsparameter (wie Datenbankverbindungen) austauschen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht. Das Ergebnis wird in diesem Ansatz jedoch nicht in einem eigenen Branch gespeichert, sondern beispielsweise als Artefakt an eine Release-Pipeline übergeben. Diese nutzt dann die Fabric Item API, um die jeweiligen Fabric-Objekte oder Änderungen in den Ziel-Workspace zu deployen.
Um die Interaktion mit der Fabric API zu vereinfachen, können Libraries wie die fabric-cicd Python Library verwendet werden.
Genau wie das Branch-based Deployment erfordert dieser Ansatz Erfahrung im Umgang mit Azure DevOps Pipelines, erlaubt deshalb aber auch die volle Flexibilität in der genauen Ausgestaltung des Deploymentprozesses.
Fazit
In diesem Artikel haben wir die gängigsten Entwicklungs- und Deploymentprozesse in Microsoft Fabric exemplarisch vorgestellt. Gerade innerhalb der Deploymentprozesse über Azure DevOps bzw. Github besteht in der konkreten Ausgestaltung aber natürlich die volle Flexibiltät, diese genau auf die eigenen Bedürfnisse anzupassen. Es ist außerdem nicht notwendig sich bei allen Workloads, die auf Fabric abgebildet werden sollen, für einen einzigen Entwicklungs- oder Deploymentprozess zu entscheiden. Die Wahl des passenden Prozesses sollte stets auf die spezifischen Anforderungen und den jeweiligen Workload abgestimmt sein. So ist es sinnvoll einen professionellen Deploymentprozess für zentrale Datenprodukte wie z.B. ein unternehmensweites Datawarehouse zu wählen, während für einzelne Fachbereiche evtl. ein Deployment über Deployment Pipelines ausreicht, oder sogar komplett auf Deploymentprozesse verzichtet werden kann.
Wer noch mehr Tipps und Tricks zu Microsoft Fabric erfahren möchte, sollte einen Blick in unseren Microsoft Fabric Kompakteinführung Workshop werfen!
Die neue Version der aus Azure bekannten Data Factory in Microsoft Fabric stand in letzter Zeit im Fokus zweier Vorträge, die scieneers auf renommierten Veranstaltungen präsentieren durften. Stefan Kirner hat auf der SQL Konferenz in Hanau, ausgerichtet von Datamonster, sowie auf den SQLDays, organisiert von ppedv, gesprochen.
Die Präsentation beleuchtete die technischen und konzeptionellen Unterschiede zwischen der Azure Data Factory und jener in Microsoft Fabric. Ebenso wurden die Auswirkungen dieser Unterschiede auf die Entwicklung sowie wichtige Aspekte des Application Lifecycle Managements beim Teamwork in Fabric thematisiert.
Hier eine kurze Zusammenfassung der gewonnenen Erkenntnisse:
Das Gute:
– Die Data Factory entwickelt sich weiter, bietet erweiterte Features und ist besser in das Gesamtsystem integriert.
– Das Software-as-a-Service Modell und ein berechenbares Preismodell erleichtern gerade Neulingen den Einstieg.
– Viel des bereits vorhandenen technischen Know-hows und Methodenwissens rund um die Azure Data Factory ist weiterhin anwendbar.
– Die Migration von bestehenden Data Engineering Projekten ist in den meisten Fällen problemlos möglich.
Das Schlechte:
– Für sehr kleine Projekte ist die Data Factory in Fabric nicht effizient einsetzbar.
– Spark Notebooks sind in den kleinsten verfügbaren Kapazitäten nicht wirklich nutzbar.
Das Hässliche:
– Es mangelt noch immer an Unterstützung für Git und Deployment Pipelines für Data Flows der zweiten Generation.
– Es existieren viele GUI Bugs und die Stabilität lässt zu wünschen übrig.
– Die noch eingeschränkte Anzahl von Datenquellen bei der Copy Activity führt zu Verwirrung.
Trotz der genannten Schwachstellen entwickelt sich Fabric in eine sehr positive Richtung. Microsoft arbeitet mit Hochdruck an den aktuellen Herausforderungen. Scieneers freut sich darauf, diese Technologie in zukünftigen Kundenprojekten weiterhin erfolgreich einzusetzen.
https://www.scieneers.de/wp-content/uploads/2024/10/stefan-kriner-sql-konferenz.png14862514Stefan Kirnerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngStefan Kirner2024-10-14 16:45:432025-01-31 13:32:21Data Factory in Fabric – the good, the bad and the ugly