Die Data2Day ist eine von wenigen deutschen Konferenzen, deren Thema nicht primär auf AI oder Machine Learning liegt, sondern sich dem Datenmanagement widmet. Sie wird vom Heise Verlag ausgerichtet und fand bereits zum achten Mal statt. Wir waren mit dabei und haben uns bemüht, mit unserem Vortrag eine Brücke zwischen beiden Themen zu schlagen: ‚SiloX-GPT: Daten-Silos verbinden mittels Multi-Agenten-System‘.
Unser Vortrag zu Multi-Agenten-Systemen
Unser Kollege Nico Kreiling beim präsentieren.
Gemeinsam mit Bertelsmann konnten wir die Ergebnisse unseres Content-Search Projektes vorstellen. In diesem Projekt lösen wir das Problem, dass es aufgrund der großen und verzweigten Firmenstruktur der sogenannten Berthelsphere keinen Ort gibt, wo sämtliche Daten der unterschiedlichen Bereiche entdeckt werden können. Wir lösen das Problem der sehr heterogenen Datenlandschaft dabei mit Hilfe von LLM-Agenten, welche mit Hilfe von Tools APIs abfragen, Knowledge-Graphs durchsuchen oder klassisches RAG durchführen können. Orchestriert wird all dies mit Hilfe von LangGraph, welches erlaubt Langchain-basierte Agenten und andere Verarbeitungsknoten in einem Kommunikationsgraphen frei zu modellieren. Neben der Vorstellung des Systems standen auch zahlreiche Learnings im Zentrum des Talks, denn in der ersten Zusammenarbeit zwischen Bertelsmann und Scieneers stand zunächst eine Evaluation der neuen technischen Möglichkeiten von LLMs im Zusammenspiel mit einem Knowledge-Graph im Vordergrund. Erst über mehrere Iterationen mit verschiedenen Stakeholdern hinweg entwickelte sich daraus die eigentliche Produktidee. Einige der wichtigen Learnings waren:
Technologie-Exploration und Produktentwicklung haben sehr unterschiedliche Anforderungen an Team, Organisationsform und Zielstellung
Tracing und Monitoring ist bei LLM-Applikationen mindestens so wichtig wie bei klassischer Softwareentwicklung, um ein resilientes und stabiles System zu entwickeln
Ein Multi-Agenten-Setup ähnelt einem Micro-Service-Design und bringt ähnliche Vorteile: Modulare Komponenten sorgen für bessere Wartbarkeit und Stabilität
LLM-Agenten sind mächtige Werkzeuge. Entscheidend ist dabei eine klare Ausrichtung des Prompts und der verwendeten Tools getreu dem UNIX-Motto: Do just one thing and do it well!
Die weiteren wichtigen Themen der Konferenz
Gefühlte Wahrnehmung von Data Science Teams Anfang 2023 (von Dr. Sarah Henni)
In der Eröffnungskeynote zeigte Dr. Sarah Henni von EnBW auf unterhaltsame Art den ChatGPT-Moment, als AI im Alltag vieler Menschen ankam und Postfächer von Data Science Abteilungen geflutet wurden. Seitdem wurden zahlreiche „Hook“-Projekte realisiert, die wichtig sind, um die neue Technologie zu erproben und ins Gespräch darüber zu kommen, wo nun die wirklichen Transformations-Potentiale liegen. Diese Einschätzung können wir nur bestätigen, denn nach vielen PoCs im Jahr 2023 liegt der Fokus dieses Jahr auch in unseren Projekten nun mehr auf Produktivierung, Stabilität und Resilienz. Außerdem haben immer mehr Projekte neben strategischen Zielen auch klare finanzielle KPIs.
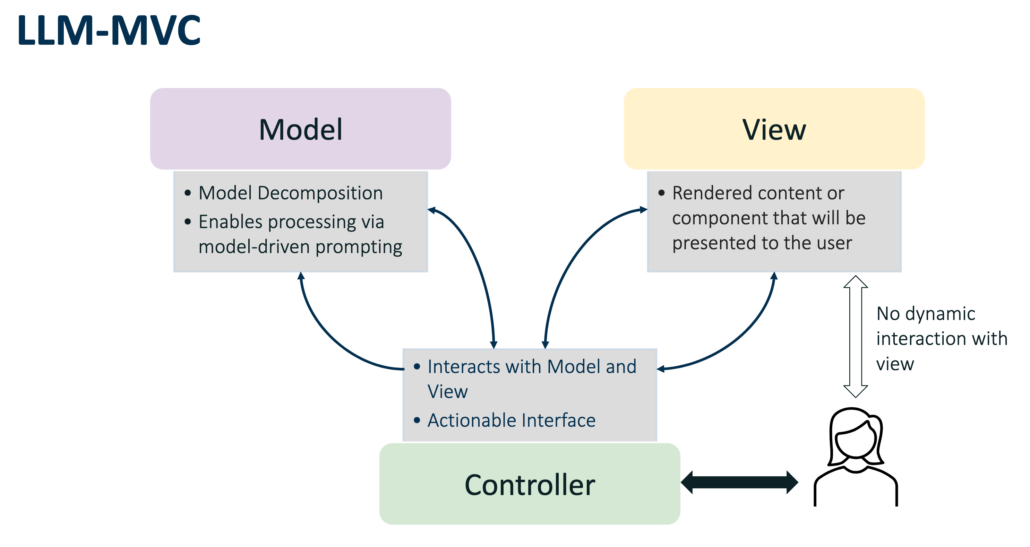
Schematische Darstellung des MVC-Pattern für LLMs nach Robert Bauer
Ein weiterer spannender Vortrag kam von Robert Bauer von der HMS Analytical Software. Er nutzte das aus der Applikationsentwicklung bekannte MVC-Pattern, um LLM-Applikationen zu strukturieren. Soll etwa ein Blog-Eintrag von einem LLM verfasst werden, so werden die einzelnen notwendigen Felder (wie Überschrift, Volltext, Excerpt, Tags, SEO-Text etc.) mit Hilfe von Pydantic als Modell repräsentiert. Die View hat dann ausschließlich die Aufgabe, dieses rein-textuelle Modell mit Hilfe von HTML-Templates in einen ansprechend formatierten Eintrag zu überführen. Der Controller übernimmt schließlich mit Hilfe unterschiedlicher, möglichst atomarer und damit besser promptbarer LLM-Calls das Befüllen des Modells.
Der Ansatz überzeugt vor allem, weil er bei der Strukturierung des Codes hilft und ermöglicht eine große LLM-Anfrage in mehrere kleinere, für das LLM besser verarbeitbare Abfragen zu zerlegen. Darüber hinaus lassen sich mit Hilfe des Modells abhängige Felder identifizieren (der SEO-Text hängt beispielsweise von Überschrift und Text ab), die automatisch als invalide markiert werden können, wenn sich im Abhängigkeitsbaum zuvor etwas geändert hat.
Natürlich haben auch bekannte Data Management Themen wie etwa Data Mesh, Knowledge Graphs oder Data Contracts das Programm der Data2Day bestimmt. Aber auch diese wurden entsprechend um AI erweitert: So zeigten die Macher von datacontract.com ihren GPT-Bot zur automatischen Erzeugung von Verträgen.
Zu guter Letzt war auch der AI-Act ein wichtiges Thema der Konferenz. Gut gefallen hat uns hier vor allem die Sichtweise von Larysa Visengeriyeva, die ihn im Wesentlichen als rechtliche Verpflichtung von Software-Best-Practices (wie etwa Transparenz, Erklärbarkeit, Data Governance, Fehlertoleranz/Resilienz, Dokumentation) für AI darstellte.
Bei der Gelegenheit wollen wir uns abschließend beim Heise Verlag für die Durchführung der gelungenen Konferenz und das Vernetzen der vielen engagierten Sprecher und Teilnehmer bedanken.
https://www.scieneers.de/wp-content/uploads/2024/09/DPK_9954-scaled.jpg17092560Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2024-09-24 16:24:462025-01-31 13:32:52Multi-Agenten LLM auf der Data2Day
In diesem zweiten Teil zu Multi-Agenten-LLM-Systemen wird es um die Umsetzung komplexer Informationsflüsse mit Hilfe von LangGraph gehen. In Teil 1 wurde generell erklärt, warum Multi-Agenten-Systeme hilfreich sind und wie sie mit AutoGen umgesetzt werden können.
LangChain ist das populärste Framework für die Entwicklung von LLM-Applikationen. Es bietet nicht nur eine riesige Auswahl vordefinierter Text-Extraktionstools, Sprachmodelle und sonstiger Tools, sondern vor allem eine Hierarchie von Klassen. Typischerweise kombiniert man ein PromptTemplate mit einem LLM und optional einem Validator in einer Chain. Am einfachsten funktioniert dies durch die Nutzung der LCEL (LangChain Expression-Language), welche zwar etwas Gewöhnung erfordert, dafür aber kompakten und standardisierten Code ermöglicht.
from langchain.output_parsers.boolean import BooleanOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import AzureChatOpenAI
prompt = PromptTemplate.from_template(
"""Decide if the user question got sufficiently answered within the chat history. Answer only with YES or NO!
Sentences like "I don't know" or "There are no information" are no sufficient answers.
chat history: {messages}
user question: {user_question}
"""
)
llm = AzureChatOpenAI(
openai_api_version="2024-02-15-preview",
azure_deployment="gpt-35-turbo-1106",
streaming=True
)
parser = BooleanOutputParser()
validator_chain = prompt | llm | parser
# Zum Aufruf der Chain müssen alle Prompt-Variablen übergeben werden
validator_chain.invoke({
"user_question": "Was sind die aktuellen Trends in Italien?",
"messages": ["die aktuellen Trends Italiens sind heute Formel 1 und ChatGPT"],
}) # Returns True
Natürlich wird auch die Ausführung von Funktionen (bzw. Tools) von LangChain unterstützt. Hierfür müssen wir zunächst die auszuführende Funktion in ein LangChain-Tool umwandeln. Dies kann explizit oder via Funktionsannotation erfolgen. Der Vorteil hierbei ist, dass die notwendigen Informationen für die Nutzung in einem Sprachmodell automatisch aus den Docstrings der Funktion extrahiert werden und somit Redundanzen vermieden werden können.
from pytrends.request import TrendReq
def get_google_trends(country_name='germany', num_trends=5):
"""
Fetches the current top trending searches for a given country from Google Trends.
Parameters:
- country_name (str): The english name of the country written in lower letters
- num_trends (int): Number of top trends to fetch. Defaults to 5.
Returns:
- Prints the top trending searches.
"""
pytrends = TrendReq(hl='en-US', tz=360)
try:
trending_searches_df = pytrends.trending_searches(pn=country_name)
top_trends = trending_searches_df.head(num_trends)[0].to_list()
return top_trends
except Exception as e:
print(f"An error occurred: {e}")
from langchain.tools import StructuredTool
google_trends_tool = StructuredTool.from_function(get_google_trends)
google_trends_tool.invoke(input={})
Anschließend muss das erstellte Tool dem Modell übergeben werden. Nutzt man ChatGPT, unterstützt das Modell natives function_calling, sodass das Tool lediglich mit Hilfe des Aufrufs bind_functions aktiviert werden muss. Nun kann das Modell einen entsprechenden Funktionsaufruf bei Bedarf triggern, um die Funktion aber auch automatisch auszuführen und die Ergebnisse dem Modell zurückzugeben, muss die Chain in einen Agenten überführt werden. Hierfür existiert eine eigene Klasse, die neben der auszuführenden Chain lediglich einen Namen und die auszuführenden Tools benötigt.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.agents import create_openai_functions_agent
from langchain_core.utils.function_calling import convert_to_openai_function
from langchain_core.runnables import RunnablePassthrough
from langchain.agents.output_parsers.openai_functions import OpenAIFunctionsAgentOutputParser
from langchain.agents import AgentExecutor
from langchain_core.messages import HumanMessage
from langchain.agents.format_scratchpad.openai_functions import (
format_to_openai_function_messages,
)
from langchain_community.tools.tavily_search import TavilySearchResults
tavily_tool = TavilySearchResults(max_results=5)
tools = [google_trends_tool, tavily_tool]
system_prompt = "\\nYou task is to get information on the current trends by using your tools."
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
agent = create_openai_functions_agent(llm, tools, prompt)
llm_with_tools = llm.bind(functions=[convert_to_openai_function(t) for t in tools])
agent = (
RunnablePassthrough.assign(
agent_scratchpad=lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
)
)
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
executor = AgentExecutor(name="Analyzer", agent=agent, tools=tools)
Mit der LangChain-Version 0.1 wurde zudem LangGraph als Konzept zur Implementierung von Multi-Agenten-Systemen eingeführt. LangGraph orientiert sich an der Idee von AutoGen, organisiert die Kommunikation jedoch nicht über einen freien Nachrichtenaustausch und geteilte Chat-Historie, sondern mittels eines Graphen. Das Interface orientiert sich an der beliebten NetworkX Python-Bibliothek und ermöglicht so eine flexible Komposition von gerichteten Graphen, welche auch zyklisch sein dürfen, also Schleifen enthalten können.
Zunächst wird ein Graph mit einem definierten Status definiert. Anschließend werden Knoten und Kanten hinzugefügt und ein Startpunkt gewählt. Kanten können statisch oder durch Bedingungen bestimmt werden, wodurch der Graph seine Dynamik erhält. Sowohl die Knoten wie auch die bedingten Kanten können einfache Python-Funktionen sein oder auch mittels LLM-Call bestimmt werden. Sie erhalten dafür jeweils den aktuellen State und geben einen neuen State für den nächsten Knoten zurück. Abschließend wird der Graph mit allen Knoten und Kanten zu einem “Pregel”-Objekt kompiliert.
from langchain_core.prompts import ChatPromptTemplate
from typing import TypedDict, Annotated, Sequence
import operator
from langchain_core.messages import BaseMessage
from langgraph.graph import StateGraph, END
compliance_prompt = ChatPromptTemplate.from_messages([
("system", """Make sure the answer is written in the same language as the user language.
The answer should be well-written in a formal style. It should use gender neutral language.
Modify the answer if necessary.
user question: {user_question}
chat history: {answer}
""")
])
compliance_chain = compliance_prompt | llm
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add] = []
round: int = 0
workflow = StateGraph(AgentState)
def call_writer(data):
if data.get("round") is None:
round = 1
else:
round = data["round"] + 1
return {"round": round, "messages": [executor.invoke(data).get("output")]}
def call_compliance(data):
return {"messages": [compliance_chain.invoke({"user_question": data["messages"][0], "answer": data["messages"][-1]})]}
workflow.add_node("writer", call_writer)
workflow.add_node("compliance", call_compliance)
workflow.set_entry_point("writer")
workflow.add_conditional_edges(
"compliance",
lambda x: validator_chain.invoke({"user_question": x["messages"][0], "messages": x["messages"][1:]}) if x["round"]<2 else True,
{
True: END,
Fals4e: "writer"
}
)
workflow.add_edge('writer', 'compliance')
app = workflow.compile().with_config(run_name="Conduct Interviews")
app.invoke({"messages": [HumanMessage("Was sind die derzeit größten Trends in der Türkei?")]})
Dieser Pregel-Graph implementiert selbst das LangChain Runnable Interface, kann also synchron wie asynchron und als Stream- oder Batch-Operation ausgeführt werden. Typisch für LangChain wird die Komplexität selbst also möglichst vor dem Nutzer verborgen, was jedoch auch das Debugging erschwert. Sehr hilfreich ist in diesem Zug LangSmith, die von LangChain entwickelte Monitoring-Lösung. Die Integration erfordert lediglich einen API-Key, anschließend werden sämtliche Events in die Cloud gestreamt und dort in einer benutzerfreundlichen WebUI dargestellt. Diese bietet einen schnellen Einblick in sämtliche ausgeführte Operationen wie LLM-API-Calls, ausgeführte Tools und aufgetretene Fehler. Dazu werden Ausführungszeiten, generierte Tokens bzw. deren Kosten sowie zahlreiche System-Meta-Informationen getrackt.
Wer LangSmith nicht nutzen möchte oder mehr Kontrolle wünscht, kann dem Workflow einen eigenen Callback mitgeben und darin auftretende Events weiterverarbeiten. Beispielsweise eignen sich Callbacks auch, um eine eigene UI anzuschließen. Die Implementierung ist durchaus aufwändig, denn es existieren insgesamt 14 verschiedene Event-Typen, die bei Start, Ende und Fehlern von unterschiedlichen Aktionen relevant sind. In unserem Fall konnten wir leider nicht in jedem Event die gewünschten Informationen extrahieren, sondern mussten teilweise auf verlinkte Parent-Events zurückgreifen, sodass wir selbst einen Graph-Callback entwickelt haben, über den sich auch die Komplexität der versteckten Aufrufe innerhalb eines LangGraph-Calls visualisieren lässt.
Vergleich zwischen LangGraph und AutoGen
AutoGen
LangGraph
Projektstatus
Als erstes Framework für Multi-Agenten-Systeme erfreut sich AutoGen großer Beliebtheit. Das Projekt wird durch Microsoft vorangetrieben, basiert aber architektonisch auf dem dünnen Fundament eines wissenschaftlichen Aufsatzes.
Die Multi-Agenten-Lösung des populärsten LLM-Frameworks wurde im Januar 2024 veröffentlicht. Sie nutzt erste Erfahrungen von AutoGen und kombiniert sie mit Ansätzen aus etablierten Open-Source-Projekten (NetworkX, Pregel). LangGraph wird als eine Komponente des LangChain-Ökosystems fortgeführt.
Function Calling
Bei Autogen werden sämtliche Funktionsausführungen durch einen idee proxy agent ausgeführt. Entweder nativ oder für mehr Sicherheit innerhalb eines Docker Containers.
In LangChain können Funktionen und Agenten selbst in Executables verwandelt werden. Das vereinfacht die Struktur, eine Kapselung von Funktionsausführung in einer separaten Sandbox wie bspw. einem Container ist derzeit nicht vorgesehen..
Nachrichtenfluss
Die Kommunikation zwischen Agenten erfolgt innerhalb eines Gruppenchats prinzipiell frei und wird über einen group chat manager gesteuert. Dies bietet viel Flexibilität für Agenten, aber erschwert explizite Struktur.
Die Kommunikation wird durch einen Graphen abgebildet. Darüber lassen sich auch spezifische Kommunikationspfade einfach und intuitiv abbilden. Durch Conditional Edges sind aber auch komplett offene Gruppengespräche zwischen Agenten abbildbar.
Usability
AutoGen bietet mit seinen Beispielen und dem AutoGen Studio einen einfachen Einstieg in die Nutzung mehrerer Agenten. Möchte man jedoch nicht nur Prompts und Tools modifizieren, müssen die eigentlichen Agentenklassen erweitert werden, was Upgrades und Maintenance erschwert.
LangChain ist ein mächtiges Framework, das versucht, Komplexität vor dem Nutzer zu verstecken, ihn dafür aber abverlangt, zahlreiche Framework-Eigenheiten zu erlernen. Der hohe Grad an Abstraktion führt jedoch gerade zu Beginn oft zu Hindernissen. Hat ein Nutzer jedoch die Spezifika von LangChain verstanden, ist der Einsatz von LangGraph einfach und intuitiv.
Reifegrad
Autogen eignet sich hervorragend für einen Einstieg ins Thema Multi-Agenten, jedoch ist es schwierig, produktive Use-Cases hiermit umzusetzen. Gruppenkonversationen sind wenig verlässlich und es gibt keine Unterstützung bezüglich Monitoring und Ähnlichem. Durch die geteilte Chat-Historie der Agenten werden die ausgeführten Prompts schnell lang und damit teuer und langsam.
LangGraph ist eine noch junge Software auf einem gut durchdachten Fundament. Das LangChain-Ökosystem bietet zahlreiche Output-Parser und Möglichkeiten des Fehlermanagements. LangGraph bietet zudem eine genaue Kontrolle, welcher Knoten zu welchem Zeitpunkt welche Informationen verfügbar haben soll und Business-Anforderungen an den Kommunikationsfluss lassen sich flexibel abbilden. Zudem wird es durch seine Serving- und Monitoring-Infrastruktur unterstützt.
Fazit
AutoGen hat einen wertvollen Beitrag für Multi-Agenten-Systeme geleistet und eignet sich gut für erste Experimente. Wer allerdings eine genauere Kontrolle über die Kommunikation der Agenten wünscht oder eine produktive Anwendung bauen möchte, sollte eher auf LangGraph setzen. Wir selbst haben kürzlich eine existierende Anwendung von AutoGen auf LangGraph umgebaut. Während die Umsetzung der Agenten und Tools relativ einfach war, lagen die größten Aufwände in der Migration der UI-Anbindung, um via LangGraph-Callback alle notwendigen Informationen bezüglich Tool- und LLM-Nutzung abzubilden. Zudem unterstützen beide Frameworks bisher noch nicht nativ die parallele Ausführung von Agenten, wenn anschließend die Ergebnisse zusammengeführt werden sollen. Dennoch lässt sich sagen, dass sich mit LangGraph und LangSmith auch komplexe Workflows unter Einbeziehung von LLMs erstellen und betreiben lassen.
https://www.scieneers.de/wp-content/uploads/2024/03/Screenshot-2024-03-28-at-17.48.35.png17703108Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2024-03-28 17:49:562025-01-31 13:40:05Multi-Agenten-LLM-Systeme kontrollieren mit LangGraph