
Wie implementiere ich einen “Question Answering”-Bot für Slack in Python?
Innovationen wie sentence-transformers, neuronale Suche und Vektordatenbanken haben in letzter Zeit zu einem rasanten Fortschritt bei Frage-Antwort-Systemen geführt. Auch die Menge an vorhandenen Daten in bspw. unternehmensinternen Kommunikationstools wächst kontinuierlich weiter. Das manuelle Suchen nach internen Informationen kann dadurch schnell mühsam werden und einige Zeit in Anspruch nehmen. Insbesondere in Slack-Channels sammeln sich häufig viele Daten innerhalb kürzester Zeit an. Das Suchen nach einer bestimmten Nachricht auf eine Frage in solchen Konversationen… Aufwändig!
Daher möchten wir bei scieneers uns die neuen Technologien zu Nutze machen und mithilfe eines Slack-Bots das Auffinden und die Zugänglichkeit von internen Informationen erleichtern. Anhand von Dokumenten und Slack-Konversationen sollen Fragen der User beantwortet werden. Zur Antwortgenerierung greifen wir dabei auf das Haystack QA-Framework in Kombination mit einer Weaviate-Vektordatenbank und verschiedene, optimierte Sprach-Modellen zurück.
In diesem Blogeintrag geben wir einen Überblick über die aktuelle Entwicklung unseres Slack-Bots. Dabei gehen wir neben organisatorischen Take Aways auch auf technische Herausforderungen und Lösungen ein.
Komponenten innerhalb der Gesamtarchitektur
Die Implementierung eines Slack-Bots, der die Aufgabe eines Question Answering hat, setzt sich aus unterschiedlichen Komponenten zusammen, welche in einer Gesamtarchitektur aufeinander einwirken.
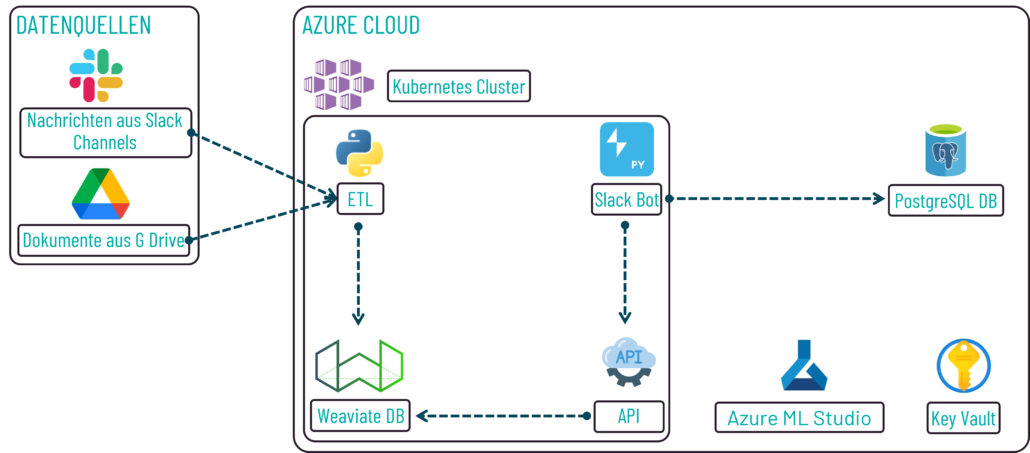
Architektur der Implementierung des Bots
Daten bilden die Grundlage, um ein Question Answering durchführen zu können. Aktuell verwenden wir interne Slack-Channels und geteilte Dokumente des unternehmensweiten G Drive als Datenquellen. Die Daten aus diesen Quellen werden durch einen ETL-Prozess extrahiert, unter Umständen modifiziert, wie bspw. das Transformieren der IDs der Dokumente in ein uuid-Format, und in eine Weaviate-Vektordatenbank geschrieben. Zur Antwortgenerierung wird auf diese Daten zurückgegriffen und die Ergebnisse werden über eine API zurückgegeben, über welche der Bot schlussendlich die Antwort(en) abfragen und an den User ausgeben kann. Die Komponenten “ETL-Prozess”, “Weaviate-Vektordatenbank”, “API” und “Slack-Bot” werden dabei in einem Kubernetes-Cluster in Azure ausgeführt. Dort ist zusätzlich eine PostgreSQL-Datenbank für das Abspeichern von Metadaten über die Userfrage und ein Key Vault zum Hinterlegen der benötigten Token konfiguriert. Azure ML Studio verwenden wir für das Testen und Tracken verschiedener Klassifizierer.
Datenquellen als grundlegende Basis
Dokumente aus geteiltem G Drive laden
Bei scieneers verwenden wir G Drive für das Teilen von Dokumenten und als zentrale Ablage für Dateien. Für das Auslesen solcher Dokumente nutzen wir die von Google bereitgestellte Drive API, welche das Herunterladen unterschiedlicher Dokumente aus einem Drive Verzeichnis ermöglicht. Für das initiale Laden in die Datenbank werden alle definierten Dateien ausgelesen. Später werden lediglich die Dateien geändert, deren Modifizierungsdatum jünger als das Datum des letzten Updates der Datenbank ist.
Google unterscheidet für den Download der Dokumente verschiedene Methoden. Google-Dokumente werden mit der Methode “export” bzw. “export_media” und einem spezifizierten MIME-Type, wie bspw. “text/plain”, ausgelesen.
request = (
self.service.files(
.export(fileId = file["id"], mimeType = "text/plain")
.execute()
)
)
Alle anderen Dokumente, d.h. Microsoft-Dokumente und PDFs, erhalten wir über die Methode “get_media”. Eine Textextraktion für Word- und PDF-Dateien kann mit entsprechenden Libraries anschließend durchgeführt werden. Bei komplexeren Dateien wie PowerPoint-Präsentationen sind zusätzlich weitere Schritte notwendig.
request = self.service.files().get_media(fileId = file["id"])
fh = io.BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
logger.info(f"Download document: {file['name']}")
Relativ schnell wurde uns jedoch klar, dass manche Dokumente im Gesamttext zu lang sind, um darauf sinnvoll ein Question Answering durchführen zu können. Daher implementierten wir eine Zerlegungs-Logik, die abhängig von der Gesamtzahl an Wörtern das Dokument rekursiv mittels der Überschriftenstruktur in kleinere Blöcke zerlegt. Dafür lesen wir Google-Textdokumente mit dem MIME-Type “text/html” aus, da dieses Format uns einen Rückschluss auf Überschriften zulässt.
Nachrichten aus Slack-Channels extrahieren
Slack-Nachrichten werden durch den Bot ausgelesen, indem dieser als normales Mitglied in Channels hinzugefügt wird. Mit den entsprechenden Berechtigungen können Nachrichten aus den jeweiligen Channels extrahiert werden. Hierfür verwenden wir das “Python Slack SDK” und den darüber bereitgestellten WebClient.
Für das Auslesen der Nachrichten nutzen wir die Methode “conversations_history”, welche einen Teil der Nachrichten aus einer Konversation ausliest. Auch hier verwenden wir eine Upsert-Logik, um redundante Transformationen zu vermeiden.
Da sich mittlerweile einige Nachrichten in den Slack-Channels angesammelt haben, wird das einmalige Aufrufen der Methode nicht ausreichend sein, um alle Nachrichten zu erhalten. Ist dies der Fall, so können wir weitere Nachrichten mit einem erneuten Methodenaufruf mit der Übergabe eines erhaltenen Cursors extrahieren.
request = self.client.conversations_history(channel = channel_id, oldest = oldest, limit = LIMIT)
while request["has_more"]:
request = self.client.conversations_history (
channel = channel_id,
limit = LIMIT,
cursor = request["response_metadata"]["next_cursor"],
)
Oftmals kommt es vor, dass ein Austausch in einem Thread stattfindet. Diese Nachrichten (Replies) werden durch die obige Methode nicht erfasst und müssen separat durch die Methode „conversations_replies“ ausgelesen werden. Nach einem erfolgreichen Request kann dann über den erhaltenen Response iteriert und die Replies ausgelesen werden.
thread = self.client.conversations_replies(channel = channel_id, ts = message["thread_ts"])
Insbesondere beim initialen Laden der Slack-Nachrichten kann es schnell zu einem Rate Limit Error kommen. Um ein Abstürzen der Ausführung zu vermeiden, ist die Implementierung eines Rate Limit Handlers sinnvoll. Wir verwenden hierzu den Retry-After Header der Fehlermeldung und warten die darin übermittelte Zeit ab, bis wieder ein Request erfolgreich ist. Ferner versuchen wir ein häufiges Aufrufen von Methoden zu vermeiden und speichern daher bspw. die Namen der User in einer Klasse ab.
Datenminimierung durch Klassifizierung der Slack-Nachrichten
Die Datenmenge in den Slack-Channels wächst mit der Zeit kontinuierlich weiter. Nicht alle Nachrichten sind immer für uns relevant oder beinhalten einen Informationsgehalt, der für das Question Answering von Bedeutung ist. Solche Daten nehmen nicht nur unnötige Speicherkapazität ein, sondern erschweren auch das Filtern auf relevante Informationen. Zur Lösung dieses Problems trainierten wir ein Sprach-Modell, welches Nachrichten erst einmal in die Kategorien “Spam” und “Nicht Spam” klassifiziert. Für das Training greifen wir dabei auf die Library “SetFit” zurück, die ein Few-shot Learning mit Sentence Transformer ermöglicht. Anhand verschieden großer Datensätze trainieren und testen wir Modelle für die Klassifizierung der Slack-Nachrichten. Um dabei eine Nachverfolgbarkeit der Experimente zu gewährleisten, speichern wir das jeweilige Modell inkl. verschiedener Metriken, wie bspw. Accuracy, mit mlflow ab.
Im weiteren Verlauf trainierten wir mehrere Multiclass-Klassifizierer, um bspw. Nachrichten in verschiedene Klassen zu gruppieren. Dies ermöglicht uns, Fragen zu identifizieren, bei denen Nutzer nach Experten in Technologie xy fragen, und dort neben dem eigentlichen Text Reaktionen über Emojis auszulesen, um darüber Personen mit Erfahrung zu erfassen.
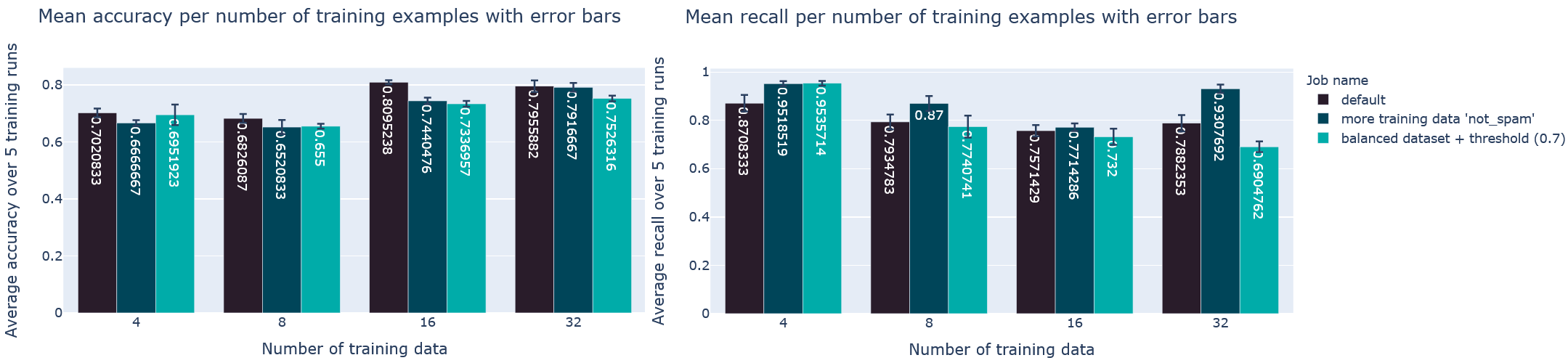
Durchschnittliche Accuracy und durchschnittlicher Recall über fünf Trainingsläufe
Slack-Bot als Kommunikationspartner für einen User
Implementierung mittels dem Framework “Bolt”
Der Slack Bot, als App im internen Slack-Workspace hinzugefügt, stellt den Kommunikationspartner für einen User dar. Er nimmt die Frage des Users entgegen und zeigt ihm Antwort(en) auf.
Für die Implementierung des Bots greifen wir auf das von Slack empfohlene Framework “Bolt” zurück. Bolt bietet einige Vorteile bei der Entwicklung eines Slack Bots. Beispielsweise können sich Entwickler:innen unmittelbar um die Funktionalitäten des Bots kümmern und müssen sich nicht erst noch mit den Themen “Installation der Anwendung”, „Authentifizierung“ und “Berechtigungen” beschäftigen, da dies von Bolt im Hintergrund durchgeführt wird. Ferner bietet das Framework ein einfaches Handling der Option “Socket Mode” (siehe “Interaktionen laufen über eine WebSocket-Verbindung”).
Die Kommunikation mit dem Bot erfolgt über zwei Wege. Einerseits kann der User, wie mit jedem anderen Mitglied des Workspaces, eine Direktnachricht starten und dort unmittelbar eine Frage an den Bot senden. Andererseits kann eine Frage in einem Channel, in dem der Bot als Mitglied hinzugefügt wurde, gestellt werden – mit dem Unterschied, dass der Bot hier mit „@scieneers QA“ angesprochen werden muss.
Sobald ein User eine Direktnachricht mit dem Bot öffnet, erscheint eine Willkommensnachricht. Anschließend kann der User eine Frage stellen und nach Erhalt der Antwort(en) ein Feedback über Buttons geben. Dies dient vor allem für das Training des Machine Learning Modells und ermöglicht einen Rückschluss über die Anzahl an korrekten und falschen Antworten, die das Modell geliefert hat. Kennt der Nutzer die korrekte Antwort, hat er zusätzlich die Möglichkeit, diese als Reply auf die vom Bot zurückgegebene Antwort(en) zu schreiben.
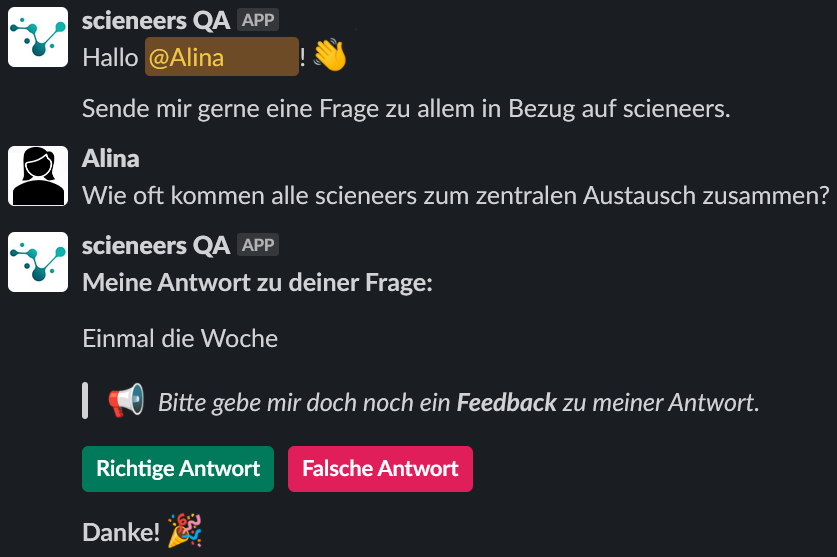
Beispielhafte Konversation mit korrekter Antwort
Um das Nutzungsverhalten besser zu verstehen sowie relevante Fragen und typische Fehler des Modells zu identifizieren, speichern wir die Fragen, angereichert durch weitere Daten, wie bspw. einem Confidence Score des Modells, in einer PostgreSQL-Datenbank. Für das Schreiben der Daten in die Datenbank aus Python heraus verwenden wir einen ORM-Ansatz.
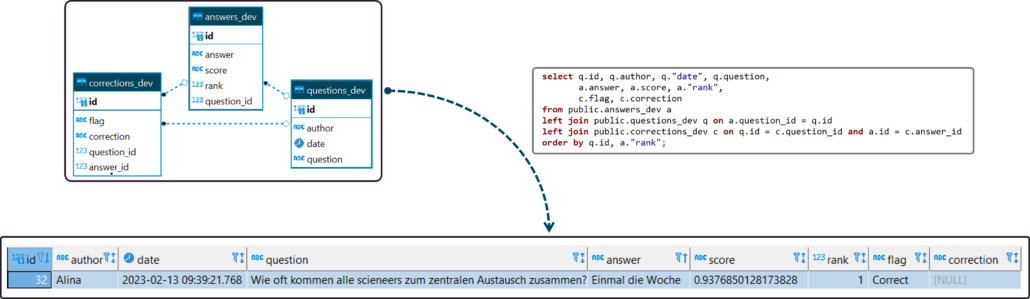
Datenbankschema
Interaktionen laufen über eine WebSocket-Verbindung
Für die Kommunikation zwischen Slack und Anwendung (Bot) greifen wir auf die Option des “Socket Mode” von Slack zurück. Dadurch laufen alle App-Interaktionen und Events über eine WebSocket-Verbindung, welche ein bidirektionales zustandsbehaftetes Protokoll mit geringer Latenz verwendet. “Socket Mode” bietet als großen Vorteil, dass Entwickler:innen unmittelbar mit der Implementierung ihrer Anwendung beginnen können, da kein zusätzliches Infrastrukturmanagement notwendig ist. Ferner ist das Entwickeln hinter einer Firewall möglich. Die Alternative hierzu ist die Verwendung eines statischen, öffentlichen http-Endpunkts.
Zweistufige Haystack-Pipeline zur Antwortgenerierung
Retriever und Reader in einer zweistufigen Pipeline
Zur Antwortgenerierung verwenden wir eine zweistufige Haystack-Pipeline, die aus den in der Weaviate-Datenbank vorhandenen Daten Antworten generiert.
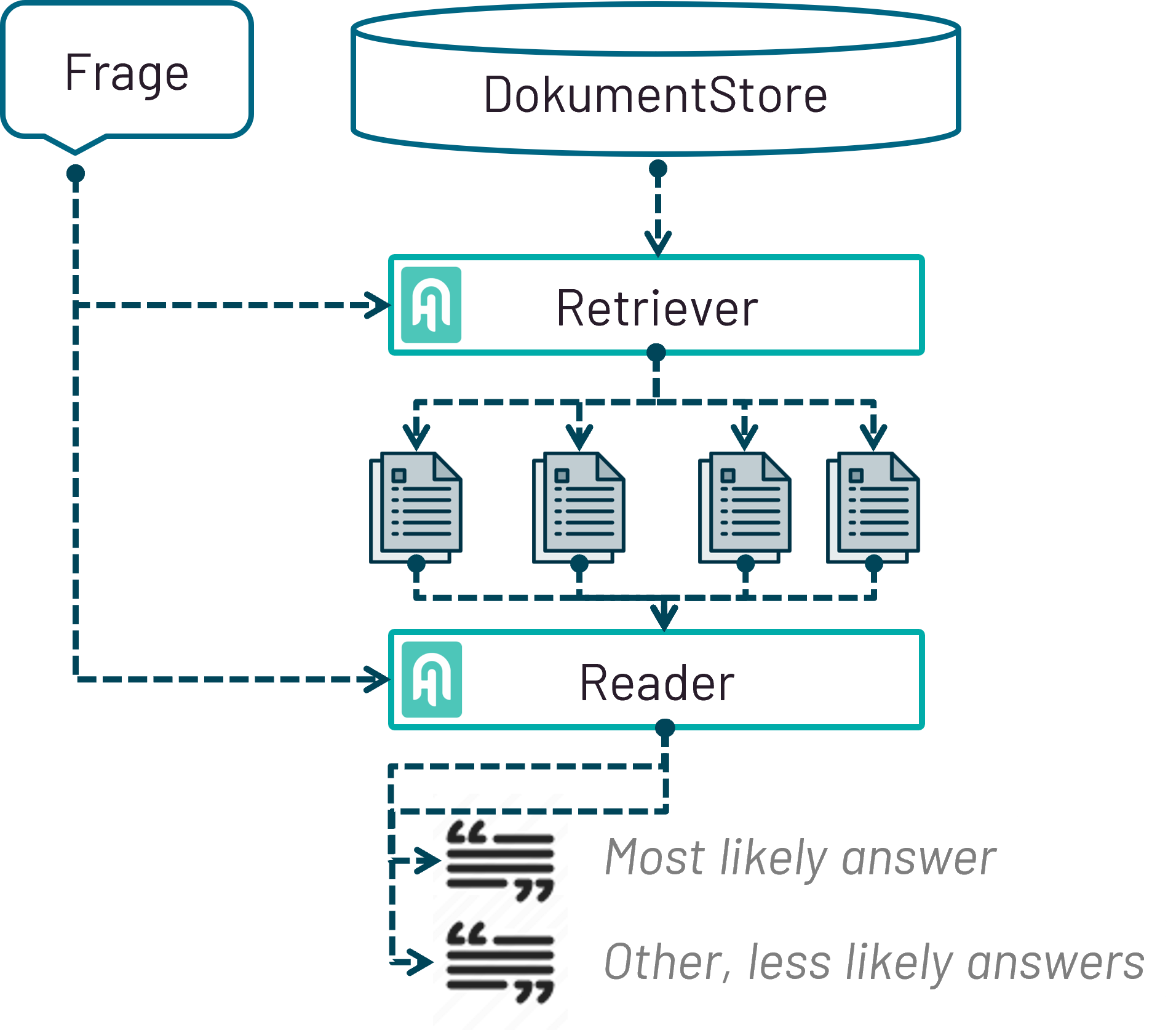
Haystack-Pipeline zur Antwortgenerierung
Die erste Stufe bildet ein Retriever (aktuell: TF-IDF), der zum einen eine Frage des Users und zum anderen einen DocumentStore (in unserem Fall die Weaviate-Datenbank) mit tausenden an Dokumenten als Input nimmt und daraus relevante Dokumentenkandidaten als Output identifiziert. Diese ausgewählten Kandidaten bilden gemeinsam mit der Frage den Input für die zweite Stufe der Pipeline – der Reader. Dieser nutzt die Textkandiadaten, um daraus relevante Passagen als Antwort(en) auf die Frage zu extrahieren. Die möglichen Textstellen werden anhand eines Scores (Confidence Score) in einem Ranking zurückgegeben. Die jeweiligen Werte der Scores verwenden wir, um die Entscheidung zu treffen, ob dem User eine Antwort (Score der ersten Antwort >= 0.6) oder drei Antworten (Score der ersten Antwort < 0.6) angezeigt wird. [/av_textblock] [av_textblock textblock_styling_align='' textblock_styling='' textblock_styling_gap='' textblock_styling_mobile='' size='' av-desktop-font-size='' av-medium-font-size='' av-small-font-size='' av-mini-font-size='' font_color='' color='' id='' custom_class='' template_class='' av_uid='av-8e3we' sc_version='1.0' admin_preview_bg='']
Performance des ML-Modell wird aktuell über ein Streamlit-Dashboard dargestellt
Überwacht wird die Performance des Modells über ein streamlit-Dashboard, welches die Tabs “Testing” und “Debugging” umfasst. Zur Datengenerierung für den Tab “Testing” geben wir zuvor ausgewählte Testfragen in die Haystack-Pipeline und speichern die Antwort(en) des Modells inklusive ROUGEL-Scores ab. Zur Quantifizierung der Ähnlichkeit zwischen Vorhersage und der von uns vorgegebenen korrekten Antwort verwenden wir den ROUGEL-F-Score. Sollte dieser Wert >= 0.6 sein, so bewerten wir eine Antwort als korrekt. Alles andere wird als falsche Antwort anerkannt. Darauf aufbauend können wir die Anzahl an korrekten Antworten bestimmen.
Während sich der Tab “Testing” dementsprechend mehr auf die vorhergesagten Antworten konzentriert, stellen wir beim Debugging spezifischere Auswertungen in Bezug auf Retriever und Reader dar. Auch hier geben wir wieder Testfragen in die Haystack-Pipeline, allerdings mit dem Unterschied, dass wir unter anderem die Position des korrekten Dokumentes im Retriever auslesen sowie die ersten fünf Antworten und nicht nur maximal die ersten drei. Dadurch können wir Rückschlüsse ziehen, an welchen Stellen sich im Retriever die Dokumente mit der korrekten Antwort befinden. So werden bspw. Dokumente, die erst an Stelle 11 nachfolgend kommen, nicht mehr an den Reader übergeben. Dementsprechend ist es wichtig, dass bei möglichst vielen Fragen das Dokument mit der korrekten Antwort unter die Top 10 der ausgewählten Dokumente des Retrievers kommt. Bei den verwendeten Testfragen ist dies zum größten Teil der Fall.

Anzahl der Fragen pro Rang des richtigen Dokuments im Retriever
Next Steps
Die Implementierung des Bots ist dennoch damit nicht abgeschlossen. In den nächsten Wochen werden noch die ein oder anderen Optimierungen und Features implementiert. So steht aktuell die Fertigstellung des Klassifizierers für Slack-Nachrichten im Vordergrund. Daneben möchten wir die Performance des Question Answering Modells noch etwas steigern, um auf mehr Fragen eine sinnvolle und korrekte Antworten zu finden. Für das Testen des Modells benötigen wir zudem einen umfangreicheren Datensatz, welchen wir mit einem Question-Generation Modell erzeugen möchten. Dieses Modell soll uns sinnvolle Fragen auf Textabschnitte generieren. Als Basismodell verwenden wir hierfür ein T5-base-Modell, welches auf dem MSMarco (Multilingual) Datensatz trainiert wurde.
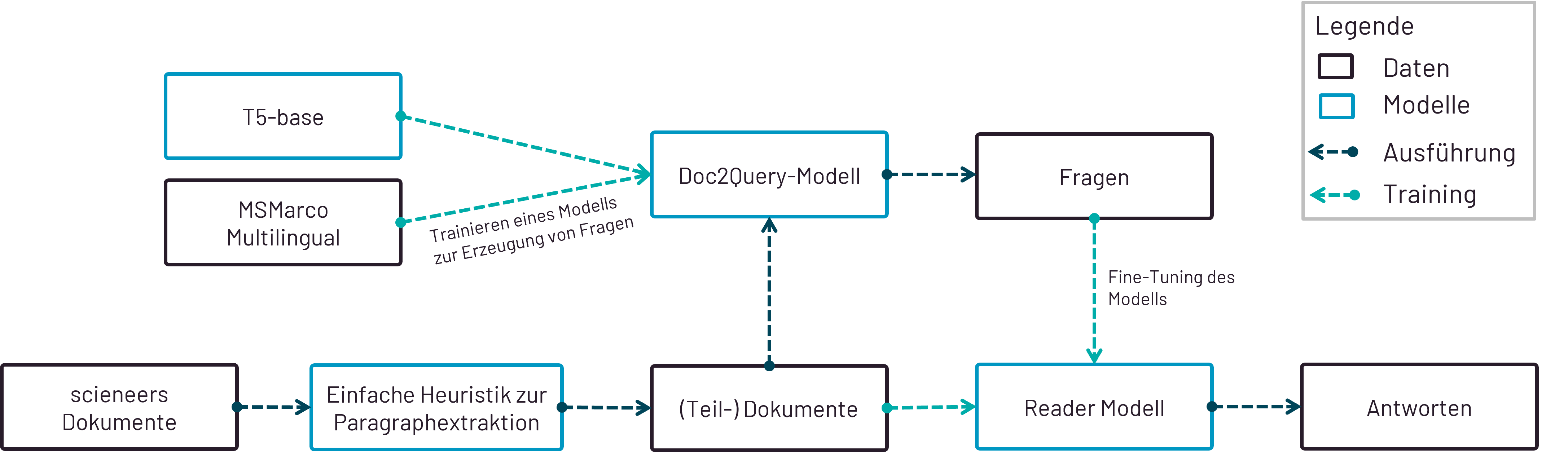
Testen des Modells mittels Fragen, die durch ein Question-Generation-Modell erstellt wurden
Weiterhin ist die Integration des Features „Frage an QA-Channel senden“ geplant. Durch die Veröffentlichung dieses Feature besteht die Möglichkeit, dass User den Bot bitten können, ihre Frage in einem separaten Channel zu stellen, falls keine der Antworten passt. Die Frage kann dadurch durch die Hilfe anderer User beantwortet werden.
Take Aways
Abschließend lässt sich festhalten, dass die Analyse und Adaption existierender Systeme an die eigenen Daten entscheidend ist. Haystack und Weaviate funktionieren prinzipiell gut. Dennoch können unterschiedliche Dokumentenlängen und unterschiedliche Informationsquellen (strukturierte Dokumente vs. informelle Chatgespräche) problematisch sein. Um solche und andere Problemfälle zu identifizieren, spielt ein gutes Evaluierungs-Dashboard mit Test-Use-Cases eine entscheidende Rolle.
Auch der Umgang mit der immer größer werdenden Datenmenge in Slack muss berücksichtigt werden, um nicht Speicherkapazitäten unnötig zu belegen und den Overhead im ETL-Prozess zu reduzieren.
Autoren
Alina Bickel, Nico Kreiling